
CHAPTER 14
Interoperability Within and Across Healthcare Systems
John Moehrke*
In this chapter, you will learn how to
• Explain the relationship between identity, access control, authorization, authentication, and role assignment
• Identify and explain access control to data from the perspective of patient, user, and resource, as well as in the context of information use
• Identify and explain how to apply security concepts to a healthcare information exchange (HIE)
This chapter describes how to control access to healthcare information. This includes the typical rules of any business that provides specific types of data to specific types of people while forbidding access to those who don’t have a need for access. Access control is an important part of any system that holds information. Even systems that simply provide a cafeteria menu use general rules to restrict those who can change the menu.
Overall, healthcare is not that different from other industries’ information systems, and for many types of access to healthcare information, the same security controls found in common IT security identity and access management (IAM) can be used. But there are aspects of healthcare, related to treatment, that require some adjustments to typical access control:
• Patient safety Safety is not unique to healthcare, but in healthcare systems safety can have life-altering (even life-ending) consequences; this creates a complexity that is not as predictable as safety is in other industries.
• Patient privacy Again, privacy is not a concern unique to healthcare, but in the context of healthcare and sensitive health topics, privacy is a more complex issue. For example, once healthcare information is released to unauthorized parties, it can’t be taken back or revoked (unlike the financial world, where a breach can be recovered from by revoking the identity or transaction). In addition, although healthcare organizations would benefit from analyzing past data to make their operations better for future patients, this is not easy while also protecting the privacy rights of patients. Governments also want to mine the data to improve population health, but privacy concerns can arise.
• Healthcare information exchange HIEs are groups of cooperating (and sometimes competing) organizations that must share information because of a common patient they are diagnosing or treating. HIEs are usually defined by geographic boundaries and are described later in this chapter.
User Identity
User identity is fundamental to controlling access, both for security and for privacy. The user’s identity, known to the software, controls that user’s access to an electronic health record (EHR).1–8 It is this identity that is related to the certain data elements that the user is authorized to access. In addition, it is this identity that is recorded in security audit logs9 for tracking what was done and by whom. The user identity is not specific to health professionals, though, because patients can also be users when they interact with their personal health records (PHRs). The user identity is also critical to system administration and maintenance. The user identity is leveraged by privacy controls to enable or disable access and provide appropriate accounting.
This chapter covers the specific aspects of user identity that are important to access control. This chapter does not cover everything related to user identities, such as those aspects needed by human resources and management.
Provisioning
User provisioning is the process of creating a user account, including performing the administrative steps that prove the individual represented by the user account is the correct individual. In a typical organization, provisioning is a shared responsibility among the human resources department, the managers of the department where the individual reports, and the information technology department (where the account is actually created). Larger organizations require more formal checks and balances when provisioning a user account. In addition, the process gets more complex when contractors or other short-term user accounts are needed. The provisioning step creates a user account, from which access to protected resources is provided.
In a special case of provisioning, a patient gets a user account, but there needs to be an additional step to create a binding between it and the patient identity associated with the record.
Ideally, there is only one user account per person in an organization; however, this ideal is usually never achieved. Where all systems are using the same user account per person, the user provisioning step can be simple. It is, however, common that there is some software that manages isolated user accounts, such as for laboratory, radiology, or other departmental systems. Creating all the necessary accounts is part of the user provisioning process.
Identity Proofing
Policies should be in place that document the methods used to prove that the human is who they say they are before they are allowed access to the user account, given that the user account is going to enable the individual to access sensitive healthcare information. The policies might require that a background check is done on the individual, government-issued identification is inspected, or some form of challenge and response using a previously known identifier is performed. Whatever method is used, this sets up the level of assurance that this user identity provides.
A good standard for this identity proofing is NIST Special Publication 800-63.2 This document defines four levels of assurance that align well with other standards. The NIST specification is an easy-to-understand specification and is freely available, and there are many other good resources.6, 7 The following is a summary of the levels of assurance of identity proofing (these levels are different from the levels of assurance of authentication, discussed in the section “The Multiple Factors of Authentication”):
• Level 1 No identity proofing is required. This is typical of free Internet services such as Facebook, Twitter, Gmail, Hotmail, and so on.
• Level 2 This requires the user to present government-issued identifying materials that include full name, picture, address, or nationality.
• Level 3 This requires that the identifying information presented be proven as authentic. This is typically done through verification with the authority that issued the credentials.
• Level 4 This requires in-person registration and presentation of two independent identifying materials that are verified as authentic.
A digital certificate8, 9 is a specific type of user identity that is standards based and thus can be leveraged by many systems. Digital certificates are issued by a certificate authority. The certificate authority sets up the administrative capability for multiple organizations, individuals, or systems to “trust” the same certificate authority, and thus the certificate authority becomes known as a trusted third party. A specific example of a user provisioning policy that shows the aspects that should be included in user provisioning is a certificate policy (CP). This is a written policy that defines the methods used for digital certificate issuance and management. An X.509 certificate policy is defined in the IETF RFC 3647.8 This certificate policy helps describe why the certificate authority should be “trusted.” Note that digital certificates do not automatically mean a high level of assurance, because there are certificate authorities that will issue a digital certificate identity at level 1. Digital certificates are often issued to computer systems, services, or organizations.10
An emerging open standard is OAuth 2.0,11 which is a significant advancement over OAuth 1.0.12 OpenID Connect is a set of constraints on OAuth to provide a very powerful federated user identification and authentication infrastructure. The technology is more readily available on the Internet and to consumers through Facebook, Google, and so on. These standards are more conducive to use with the emerging Health Language 7 (HL7®) Fast Healthcare Interoperability Resource (FHIR®) standard (also discussed in Chapters 13 and 16). There are healthcare-focused profiles available.13, 14, 15
A profile in terms of “interoperability” is a set of constraints on a standard to achieve a defined outcome. Whereas interoperability standards are designed to support many outcomes, a profile is a specification that is used to assure for a given use case that two (or more) communicating parties use a narrow definition of how they are supposed to encode data and interpret that data. A profile defines vocabulary to be used (whereas the standard allows much more), specific fields to be used (whereas the standard defines them as optional), other fields that are forbidden (whereas the standard defines them as optional), and specific behaviors to be followed.
Role Assignment
Roles are the mechanism used to give user accounts access permissions. Thus, during the provisioning process, it is important to define what roles the user will need to perform their job. The initial set of roles assigned is typically simply a “starter set,” that is, a minimal set of roles assigned to everyone when they first start. User accounts are assigned more roles as they take on more responsibility.
It is also important to have procedures to remove unnecessary roles as a user takes on different responsibilities. A mechanism that is used to remove unnecessary roles will keep to a minimum the number of individuals who have access to resources. Having a minimal number of individuals with access permissions to resources is a best practice but should also be weighed carefully with the need to provide care. For example, when healthcare professionals take on administrative roles, they might not need the ability to see healthcare information, but if they later need to be called upon to treat patients, then it might be best to leave access enabled.
Deprovisioning
More important than provisioning an account is to deprovision it when it is no longer needed. This might be when an individual retires, moves to another facility, or is dismissed. The deprovisioning should be done as soon as possible, and the date and the reason for deprovisioning should be carefully recorded.
The deprovisioning of an account in healthcare is often done through simply disabling access rather than removing the account. This is to allow the user account information to remain intact for a period of time. For example, this user account information might be needed by the medical records department to preserve the provenance of medical information, to prove signatures well into the future, or for other reasons.
User accounts that are not deprovisioned will likely stick around forever in a system, and any account that is not properly maintained presents a security vulnerability. To prevent this, an identity management system may have reports and alerts that indicate when user accounts are aging without activity. Inactivity might also be detected through the failure to change passwords on a regular basis. Regardless, there needs to be some mechanism in place to detect user accounts that are not being used so that they can be deprovisioned.
User Account Support
Not directly related to security but important to maintaining it are the user account support functions. These often include changing directory information to represent name changes or changes to a user’s office location or home location.
Internal Directory vs. External Directory
A user account is often contained within a user directory, either private to the organization (internal) or public (external). Internal user directories are often richly filled with contact information including many phone numbers, e-mail addresses, physical addresses, and calendars.16 The internal directory commonly maintains the user role assignments. In this way, an internal directory is an important asset to the operation of the organization.
External directories contain information that needs to be publicly known.17 A specific example of this is a healthcare provider directory.18 This kind of a directory contains information that patients and other health providers might use to discover the healthcare providers. For example, a patient might be looking for a specialist in a type of treatment they need. These external directories would contain minimal contact information, such as only the contact information of a registration or scheduling desk. An external directory would not include security roles or private contact information. An example of an external directory is one that supports the Direct Project (https://www.healthit.gov/policy-researchers-implementers/direct-project) need for certificate discovery, where the directory will contain the e-mail address and the digital certificate to use to secure the e-mail.
Authentication
Authentication in this context consists of the electronic mechanisms used to prove that someone or something is who they say they are. (This is independent of the identity-proofing step that proves that an identity is being issued correctly.) There are two types of authentication: authentication used prior to issuing an identity and authentication for the use of that identity. This section focuses on the latter type of authentication for the use of an identity in a session or transaction.
Essentially, the process of user authentication proves that a human is the one associated with a user identity (or user account). This might be the process used in a user interface to authenticate the “human” behind the keyboard. This also includes the process that is used to move that user authentication to other software that relies on it. An extreme example of this is the authentication that is used to authorize access to health information from another organization across a health information exchange (HIE).19
Authentication can also be used to prove that a computer system (EHR) is the system identified.19 This can be extended to anything that can be identified, including a specific service (e.g., laboratory order manager) or whole organizations (e.g., virtual private network). Authenticating a computer system or service is often done using Transport Layer Security (TLS)20 and digital certificate8–10 identities.
The Multiple Factors of Authentication
Humans are hard to authenticate. When authenticating humans, security systems deal with one or more factors about that human to prove that they are indeed who they claim to be. The methods of authenticating humans have been built up over the millennium. Computers simply move these concepts to electronic technology. There are three factors2 that we use to authenticate humans:
• Something the user knows (e.g., secret passphrase, password, personal knowledge, etc.)
• Something the user has (e.g., identity card, smartcard, security token, phone, etc.)
• Something the user is (e.g., how they look, how they behave, fingerprint, DNA, etc.)
Everyone is accustomed to using passwords to log in to computer systems. These are “secrets” that only the individual logging in knows. Even the computer should not know the actual password; rather, it knows the result of an algorithm that starts with the password (e.g., salted-cryptographic-hash). Using passwords, though, is vulnerable to “guessing,” something that computers can do fast and relentlessly. This creates a need for users to create harder-to-guess passwords or change them often; however, the problem with this is that when the daily process of authenticating a user becomes hard to do, humans will get creative to thwart the system. One common example of this creativity is writing the password on a sticky note and putting it on the computer monitor for anyone to see.
Single-factor authentication, using just one of these factors, is usually not enough. Multifactor authentication, using more than one of these factors, tends to make the authentication step difficult. High-security environments or workflows might want to use at least two different factors. A good example of this is in the prescribing of narcotic drugs. Whatever method used to authenticate the user sets up another level of assurance; this is the confidence level that the user has been authenticated with for this session. Some systems, such as the Security Assertion Markup Language (SAML),21 will indicate the method of authentication used rather than identify the level of assurance (discussed in the section “Authentication vs. Claims About Authentication (Federated Identity)” later in this chapter).
Within an organization, the level of assurance is simply a business decision or policy. This becomes far more important when the organization must trust requests coming from another organization and, therefore, the level of assurance that those identities have. If the level of assurance is not good enough, then the system should not return the resource requested. Oftentimes, much discussion and hand-wringing happens when trying to predict what level of assurance is needed to prevent unnecessary rejected requests.
Secondary Authentication
Sometimes a single authentication is not enough. For example, when requesting medical procedures, you might want to be sure that the human controlling the computer is indeed still the one authenticated. Thus, the system may need to reprompt the user for authentication credentials (e.g., password). This reprompting is part of a workflow and usually is required by legal, medical, or safety rules and policies. It is done to prevent someone else from using a system that has not yet automatically logged the original user out.
Another case where a reprompt may happen is to confirm prior to creating an electronic signature, or digital signature. This reprompting is required for signature events to make sure that the signature is indeed being done by the claimed identity.
Automatic Logoff
User identity, authentication, and access controls are all intended to enable proper access to information and functions while also forbidding inappropriate access. Automatic logoff functionality recognizes that the user may step away from the computer without logging off. This could lead to someone else walking up to the computer and seeing what is displayed and using the computer as if they were the original user. To prevent this, software tries to detect when the user might not be present and take steps to protect the system. This is referred to as automatic logoff and is typically implemented by noting that the user interface (keyboard and mouse) has been inactive for a defined length of time. The exact length of time usually varies depending on the kind of access and the location of the access.
The term “automatic logoff” implies that the session is terminated and the user is logged out. This isn’t always done, but the spirit of the criteria is to stop access to the information on the screen and to prevent more actions under this user account, until the original user can prove that they are there again. The actual methods used can be quite complex.
Authentication vs. Claims About Authentication (Federated Identity)
So far, the concept of authentication has been about the computer system confirming that the human using the computer is the one identified by the user identity. There is another process that is also called authentication; this is when one computer system is using the services of a second computer system on behalf of the user. The services of the second computer system will be relying on the information that it is given and thus is called a relying party. Note that this concept extends well beyond just two parties. 1, 2, 3, 5, 21, 22
For this process, a trusted third party creates a claim, which is a statement of the user identity, authentication method, roles being used, workflow purpose leading up to the request, and possibly other things. These claims are trusted because they are made by an entity that the relying party trusts and can confirm that the relying party truly did issue the claim. A claim that is not coming from an entity that the relying party trusts should be rejected. Thus, the requesting system does need to know which trusted third parties to use for specific relying parties.
The SAML21 protocol defines a way to convey an identity and authentication claim (i.e., SAML assertion) to a relying party. Many enterprise-class authentication systems (e.g., Microsoft Active Directory) include the ability to create SAML assertions (e.g., information cards). The trusted third party is the organization, and thus there is only one trusted third party at each organization that needs to be trusted. This creates a federated identity, which is perhaps all the identity claims that your organization issues. This is similar to the OpenID and OAuth11, 12 open standards.
Accountability
Patient care is paramount in the healthcare environment. The most effective approach to patient care involves open and cooperative access to the patient information for the diagnosis, treatment, payment, and healthcare operations. Teams of people work together to diagnose and treat a patient. Some of the team members are indirect and quite possibly remote. For example, it is common for a physician or other healthcare providers to enlist the opinion of specialists. This approach assumes and relies heavily on a well-defined and vetted user group that has been schooled in the proper ways to handle confidential information.
In a perfect world, each person who needs access to data is immediately granted access, and any inappropriate use of data is immediately blocked. The problem with this is that, given the open nature of healthcare, the boundaries between justifiable need and inappropriate are elusive. Even with proper authentication and authorization controls, there is a potential for abuse. There are two philosophies to maintaining accountability: access controls and audit controls. Both methods rely on accurate authentication of the individual user. These two different philosophies are implemented in different mixtures, but it is important to understand them.
Access Control
With this method, each user account is restricted to the patient records and product functionality that the user is authorized to access. With this type of restriction, audit trails are not that important. Accountability is maintained by the technology that keeps the individuals from doing the wrong thing.
Advantages
This method prevents any misuse of patient data. An important aspect of personal data privacy is that once data has been wrongly exposed, it is very difficult to recover.
Weakness
This method does not work well in emergency situations where qualified but not previously known individuals may need to operate the equipment. This method may interfere with diagnosis and treatment in that it restricts with whom a physician can confer. As a patient transfers from one physician to another, access control needs to be updated. This puts a large burden on the information technology (IT) staff.
Audit Control
With this method, the individuals are not restricted in any way. Audit trails19 capture all uses of patient-identifiable data. In this method, the audit trail is very comprehensive. The accountability comes from training users on the proper use of the patient data and the knowledge that an audit trail will catch any misuse.
Advantages
This method will ensure that professional individuals are allowed the freedom to do the right thing when diagnosing and treating patients. Physicians and other healthcare providers are allowed to get second opinions for diagnostic and treatment purposes. In an emergency, new operators need only to have an account created; no complex access controls need to be created.
Weakness
The weakness of this method is that there is a huge number of audit trails that need to be managed, mined, and acted upon. This method relies on people not to abuse the personal data and to maintain ethical conduct. If there is no clear consequence to misuse, then this method will not work.
Balanced Access Control and Audit Control
A mixture of both access and audit control best achieves the balance of effectiveness versus safety versus security versus privacy. Using both access and audit controls follows the general concept of “failing into a safe state” in the healthcare treatment domain. What is safe in the banking industry is to forbid access; what is safe in the healthcare treatment domain is more of a balance. It’s important to understand that it is a decision based on a good balance, not simply a declaration that access controls are hard or get in the way. This is not an easy balance, and HIT systems need to be flexible and dynamic; in other words, they need to be flexible to support expanding legitimate needs, and they need to be dynamic to adjust as issues become known.
• Effectiveness Measure of success to provide healthcare
• Safety Measure of physical harm to patient and caregivers
• Security Measure of failure to achieve confidentiality, integrity, and availability of needed system/information
• Privacy Measure of achieving patient privacy desires
This balance is not the same balance when the access of patient data is for reasons other than treatment. These other accesses are less time-critical and thus are best left in a mostly access control environment, which will require solid audit logging. The difference is that a delay in these workflows does not affect safety.
Regardless of the balance used for accountability, the security audit log must always be complete. The security audit logs are important to both security and privacy, but they are not the “accounting of disclosures” or even an “access report.” These are reports that will leverage the security audit log but will also need to be informed by disclosures that are done outside of the EHR.23
Roles and Permissions
This section covers the basics of access control through roles and permissions. The classic security model that is used for many large-scale organizations is role-based access control (RBAC).24–28 What this means is that users are grouped into roles with others who have similar access control needs. A user tends to have a set of roles that they are assigned to, not just one role. These roles have permissions assigned to them that specify to the access control engine what the users assigned to this role can do. Thus, the role is simply a grouping mechanism for multiple users and multiple permissions.
What Are Permissions?
Permissions are the building block of security access control. They are an indication of the authorization of specific actions on a class of objects. The actions are a small number of specific actions often referred to as CRUDE: create, read, update, delete, and execute.
Not all objects can be executed, and typically objects that can be executed cannot be created, read, updated, or deleted. Some examples of objects that can be executed are programs, functionality within a program, and workflows. For example, in an EHR, not all users are allowed to prescribe drugs; this would require that the individual have the execute permission on the functionality to prescribe drugs.
The class of objects tends to be the usual focus of RBAC. A class of objects is a rather open definition. It is possible to define every type of attribute as a class of objects so that the user would have permissions at the most granular level. The reality is that these classes of objects are only as small as they need to be. That is, if there is no practical reason to identify two objects, then you can identify them together as an object. The class of objects does need to be reasonable to administer or efficient to operate. Another axiom is that the class of objects will have overlap but should not have overlap without good reason. These unnecessary overlaps would just cause administrative overhead without adding any value.
Use Case 14-1: Looking at Database Permissions
To see the power of permissions, look at a database: Those in billing need access to the billing data, whereas those in diagnosis and treatment should not see this infor-mation. Those in billing need to read clinical information in order to satisfy insur-ance requests, but they should not be allowed to create clinical information. Those in food service need access to the dietary needs, including knowledge of allergies, sensitivities, and food-related preferences.
This is a very high-level view of a simple RBAC system. Clearly, the data needs to be diced up smaller than this, and the operations such as update and delete need to be handled with care.

EXAM TIP Within an EHR, there are common user roles, also known as groups, such as Nurse, Physician, Physician Assistant, or Healthcare Unit Coordinator. HIT system administrators are able to set EHR permissions by specific functions that specific groups perform. For example, an attending physician may be permitted to read, write, and modify any clinical documentation on any patient under his care or whom he has been asked to consult on. A medical student may be permitted to read and write clinical documentation but not modify that “charting.” Following an implementation of Computerized Physician Order Entry (CPOE), a Healthcare Unit Coordinator may no longer be able to write orders via the computer, but she would be privileged through the EHR to read any order on any patient on her unit.
Systems Have Roles
Note that roles are not just for human users. Systems, services, and other organizations can be assigned roles and permissions. For example, a prescription management system would recognize a specific EHR by the system authentication and, based on that system identity, find that the system is authorized to create new prescriptions or update prescriptions that it had created. This remote EHR would not be allowed to do any other permission. One graphic way to show which roles have access to which objects is a truth table.
Truth Tables
A truth table is simply a table that shows the roles in an organization and the class of object, with the actions allowed (such as Create, Read, Update, Delete, and Execute). Table 14-1 shows an example truth table. This example shows how different roles (rows in the table) are given different action rights (cell content) to the various classes of objects (columns in the table).

Table 14-1 Example Truth Table
Multilevel Data Confidentiality
Simple RBAC is not sufficient in healthcare simply because the information has so many rules applied to it that there is no simple classification scheme that can be applied. There is a set of classes of data that requires more than the typical (normal) access control protections. These classes of data are called out in regulations such as U.S. 42 CFR Part 2,29 which defines special handling for things such as drug-abuse and alcohol-abuse information when it is captured as part of a federally funded program. Individual states interpret these federal regulations in different ways. These are complex regulations that give us complex rules.
Some of these especially sensitive health topics are easier to handle than others. For example, it is rather easy to know whether your own organization includes federal funding of a drug-abuse program, but you still would need to differentiate that information gathered in general healthcare provision versus that which was discovered during a federally funded drug-abuse program. Where the sensitive health topics get more difficult for access control technology is when they are based on medical conditions such as HIV or sickle cell disease. These medical conditions are not always clear in every piece of health information, and humans are very good inference engines that can take multiple pieces of what seems to be normal health information and deduce that the patient is HIV positive, for example. This is where access control rules need to engage the same technology that clinical decision support systems (CDS) utilize.
Data Tagging with Sensitivity Codes
Some methods that can be used inside an EHR are to tag the data with sensitivity codes. The problem is that this tagging is being done using the current knowledge and current information in the patient chart. As you learn more about the sensitive topics, you learn what might expose the sensitive topic. As more information is gathered on the patient, you may be able to correlate that new information with historically not-sensitive information and expose sensitive topics. For these reasons, the tagging of health information, even inside a closed system like an EHR, is not a robust solution. Within a closed system, it may be the best solution. What is critical is the decision that is made upon disclosure, which must be made based on the best knowledge and information at the time.
Coding of Restricted Data
Sensitive health topics are usually identified with a confidentiality coding of “restricted.” This identification does not indicate why the information is sensitive; for that, you would need to look at the policy that was used to declare that the information was restricted. The advantage of using a blunt code like “restricted” is that it doesn’t expose the private condition, yet does tell the access control engine that there are special rules to be enforced.
Medical Records Regulations
Healthcare information is also ruled by regulations that are concerned not only with privacy but also with the quality and accuracy of the provision of healthcare. These regulations are not much different from any records management regulations, but their timeframes are greatly increased because they deal with a time frame of a human life span. In many cases, these regulations that mandate that records be maintained conflict with a patient’s desire to have some healthcare episodes forgotten. Sometimes this can be handled through access control rules that will blind the information from the majority of potential uses. This is where the confidentiality coding of “very restricted” should be used.
Other Sources of Access Control Rules
There are other sources of rules that might need to be applied to healthcare information, such as the following:
• Medical ethics Medical ethics standards show the need to have a conversation with a patient before exposing them to the results of some life-altering results. These are often implemented as temporal restrictions on the direct exposure to the patient, such as through a PHR or patient portal, until the general provider has had this discussion.
• Court order Sometimes the courts will require the exposure of information to the courts or the blocking of exposure of information to anyone other than the courts. A special case is to protect a victim of domestic abuse. These cases are usually handled through nonautomated means.
Data Treated at the Highest Level of Confidentiality
Healthcare information, when communicated, needs to be protected at the highest level of confidentiality of any part of the information being communicated. This means that if a package of data is being sent to another party and most of the information is normal health information but one diagnosis is of a sensitive nature, then the whole package must be considered sensitive. If the receiving system cannot handle sensitive information, then this package cannot be sent as is. It might be possible to revise the sensitive information, but this cannot be done if it will change the authenticity of the original authored content.
As data are handled, including internal movement of data as well as data movement externally, care must be taken not to lose privacy controls. This means that healthcare information does need to contain sufficient metadata to indicate where the information came from, including specific identifiers that may be associated with access control rules. Note that although it may seem logical to have the metadata record the access control rules to be applied to the data, this is not a good solution for the long term. Policies change over time; information does not. Thus, it is important to maintain the access control rules in the policy database and have the rules point at the data the rules control. This allows for the policy to change while maintaining strict integrity on the healthcare information.
Purpose of Use
One type of context is the purpose of use, which is a specific parameter of a request for information or a request to have something done. It indicates why the request is being made and how the requester intends to use the information. A common purpose of use is for a patient’s “treatment.” That is, the user is asking for this information so that they can make clinical decisions related to treating the patient. If all requests were for diagnosis or treatment, then one would not need to indicate this value on each request. However, some requests for information might be for billing purposes, research purposes, population health purposes, or quality reporting. There is an emerging vocabulary around purpose of use, coming from the HL7® standards organization. Like all vocabulary, there is a meaning behind each item that both the requestor and the relying party should understand.
Patient Privacy
The biggest deviation from simple RBAC is that the information in an EHR is about a human subject and that human subject has rights and expectations about how the information is to be used. In many cases, these rights and expectations are well aligned, and there is little impact on the RBAC rules. In other cases, the deviations can be more difficult. Privacy rights are different around the globe. In some locations, they are very strict and powerful. Generally, the privacy rights fall into seven domains:
• The purpose for the data collection should be known, limited, and stated.
• The policies and practices for handling the data should be open and transparent.
• The collection of information is limited to the minimally needed information.
• The data collected should be as accurate as possible.
• The individual (patient) should have the right to see the data that has been collected and correct it if it is found to be inaccurate.
• The uses of the data should be recorded and accessible to the individual.
• The data should be controlled against any inappropriate use or access.
This list is often extended to requiring that the individual (patient) be fully informed before positively giving authorization for the use. This is the step that is often referred to as consent or privacy consent to differentiate it from “consent to diagnose and/or treat” or other cases where the patient positively authorizes something that is not privacy-related.
Privacy Consent Related to Purpose of Use and Access Control
Privacy consent, or privacy consent directive, is not a simple binary rule. Privacy consent can be a set of complex rules. Privacy consent is always a binding agreement between the individual and the controller of data about that individual. The data controller can be an individual healthcare practice but may also be a federation of multiple organizations (e.g., consent at the HIE level) or a service appointed by the patient. The binding agreement puts responsibilities upon the data controller, and thus consent rules are made up of rules that the data controller can enforce. This binding agreement needs to be captured in a way that not only meets the legal rules of evidence but also can be processed by access control enforcement, such as the policies in the IHE Basic Patient Privacy Consents (BPPC) profile.30
Privacy consent is distinct from privacy preferences, which are statements by the individual (patient) on how they want their data to be handled. Privacy preferences could be a very permissive set of rules or could be very restrictive, even unreasonable in the case of some individuals. Privacy preferences can be used by a data controller when formulating the binding privacy consent rules.
Where the privacy consent is aligned perfectly with organizational rules that RBAC enforces, there is no impact on the access control rules. This is the best case from a data controller perspective, because it requires no additional rules to be adhered to. In the United States, the Health Insurance Portability and Accountability Act (HIPAA) does not require a covered entity (the formal name for most data controllers in healthcare in the United States) to take on additional privacy consent rules but does give the patient the right to request their privacy preferences.
Use Case 14-2: Looking at Metadata
Some metadata explains where the data came from, some metadata explains who authored the data, and some metadata describes the type of data. The desired rule could identify a time frame that should be hidden, a type of data that should be hidden, data authored by a specific facility that should be hidden, or a specific object (report) that can be recognized by the unique identity value that should be hidden. The specific way that the privacy rules would be written would be based on the specific rule desired and the available metadata to act upon it. Note that privacy rules can leverage metadata that is not typically seen as specific to privacy.
The privacy consent is often implemented in a more generic way, as privacy rules or a privacy policy. In this case, privacy rules are special handling rules that are specific to that identified individual (patient). In this way, the privacy rules can incorporate obligation rules like “do not redisclose without getting new privacy consent from the individual.”
Finally, privacy consent is often the same thing as a privacy authorization, such as when the patient authorizes a researcher to use the data for a research project. In terms of HIPAA, this is an authorization, but it is technically not any different from a special “Purpose of Use” in the rules of a privacy consent. That is, the patient consent authorizes some individuals or roles to have specific purpose-of-use access to their data or a subset of their data.
Privacy consent rules can be very specific rules. A common desire is to hide specific treatment episodes because of their socially stigmatizing nature. This can be included in the privacy consent rules in many ways. This is where privacy consent rules leverage metadata or the information attributes that describe the data.
Hint
When there is a need to directly bind a specific policy and a specific piece of data, the policy rules are written to identify the data to be controlled, rather than marking the data with the policy rules around how it can be used. This is an important policy pointer axiom that the policy rule should point at the data. Specifically, the data should not include policy rules. This is because policy rules tend to change over time, whereas data are a specific record at a point in time. In this way, the data stays constant over time, whereas the policy rules governing that data can change as the patient, regulation, or circumstances adjust as desired.
Summary of Basic Access Control
Access control consists of policies and access control information. The access control information falls into some general categories: patient, user, resource, and context. Policies are where all the logic resides (Figure 14-1). The access control information is simply available information that a policy may have included as part of the logic. For example, a consent policy may indicate that any data created during a specific time period in the past be kept very restricted to just the patient and the author of that data. It is the policy that is calling for the inspection of the access control information to determine what the access control rule will allow or deny. Thus, it is the policies that ultimately choose what information is needed. Policies are multiple levels deep, and thus higher-level policies will refer to the decisions made by lower-level policies; therefore, the highest-level policies are rationalizing between the decisions of the underlying policies.
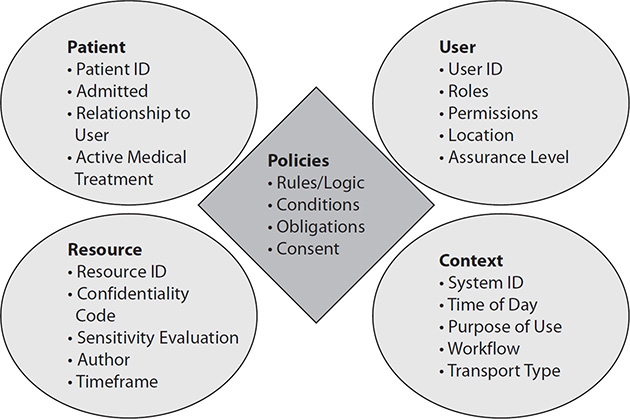
Figure 14-1 Policies vs. information used by policies
Patient Information
The patient information includes different pieces of information about the patient, most importantly, the patient identifier, their admission status, and where they are located. The patient information may contain relationships to specific user identities such as “this user identification (ID) is the patient,” “this user ID is the patient’s general practitioner,” or “this user ID is the legal guardian of the patient.” The patient information does not contain the consent rules. Consent rules are policies and thus exist in the policy space. Consent policies may be managed differently, but they are logically policies, not information.
User Information
The user information clearly includes the user ID, the roles that are assigned, the permissions assigned to those roles, where the user ID exists, and what the level of assurance of the identity is.
Resource Information
The resource information is information about the healthcare information being requested, often called metadata. Most information has some unique identifier that may be an externally known identifier, like a laboratory order number, or an internally known item, like a database table entry. The confidentiality code is an assessment of the privacy risk, where the sensitivity evaluation would be a currently assessed value of how sensitive the information is. Policies will often reference the author of an object by individual or by their organization. Policies, especially privacy policies, sometimes will have rules about any information gathered or created during a specific period of time. There are other attributes about the resource that policies call upon that are not included here, including the complete chain of provenance.
Context Information
The context information is about this specific request here and now. It would include the system that is involved, the current time of day, the purpose of use for the request, an indicator of the workflow, and the security being used for transport. There are other attributes that policy may call upon that are considered context.
Policies: Where the Logic Resides
The important part to note is that policies are where the rules are. There may be multiple levels of rules, and there may be multiple locations where rules are managed. Policies will call upon information about the patient, user, resource, and context of the request. This makes up the space of access control information. For a more detailed discussion, see the IHE access control white paper25 or other resources.27, 28, 31
Healthcare Information Exchange
Up to this point, I have discussed access control abstractly, mostly as a discussion about what happens inside an EHR. The implementation of access control within an EHR is an essential task in healthcare because it involves a patient. I will now cover how to extend access control to an HIE.32 An HIE is simply an extension of the healthcare information across organizational boundaries, usually within a region, community, or beyond. The patient may have healthcare coverage in many geographic areas.
An important aspect of HIEs is that they are often made up of healthcare provider organizations that are otherwise competing for “customers” (patients) and “employees” (providers). This is not always the case, but it is so often the case that it affects the architecture decisions. When the different parties are not competing, they will more likely just use the same EHR system in a proprietary way. Thus, this section will focus on how to satisfy access control needs when the parties are distinct and likely competing. However, the fact that they are competing does not mean they do not get benefits from the HIE. Better care for patients is in the best interest of all parties.
Push vs. Pull in an HIE
There are two general methods of exchanging healthcare information.32 One is where information is pushed from the organization that has the information to the organization that needs it, and the other is where the one that needs the information requests the information. The first case is often simply called push, and the second case is called pull.
Push Access Control in an HIE
In the case of a push, the access control decision is mostly made completely within the source organization. That is, the source organization has some workflow that determines that information needs to be sent somewhere. An access control decision is made based on all current policies, including some general knowledge about the recipient. Once the information is sent, it is mostly in the total control of the recipient and no longer in the control of the sender. There are exceptions to this. Utilizing callback technology such as digital rights management is an exception. These exceptions are not unique to push because pull can leverage them too; however, the exceptions must be agreed to by both the sender and the recipient.
Pull Access Control in an HIE
The rest of this chapter will mostly focus on the pull model of an HIE. The pull model offers the most complexity, and it benefits the most through the use of consistent access control models. The consistency is achieved through the use of the fundamentals that were already discussed using commonly available interoperability standards. These are considered commonly available because they are not unique to healthcare. Healthcare does, however, constrain these interoperability standards with specific vocabulary and behaviors.
Enforcement of Access Controls in an HIE
The enforcement of access control in an HIE is a group effort. All the parties involved in the HIE will get involved in some way with the access control enforcement. There are good resources18, 25, 33, 34 that discuss access control in an HIE. There are models that indicate that the access control enforcement is the sender’s responsibility, others that indicate it is the receiver’s responsibility, and others that indicate that the HIE itself will enforce access control. When looked at closely, all of these are actually group efforts. Ultimately, the sender, the infrastructure, and the receiver each has a role in protecting the health information. These roles are further defined in the rule of HIE access control.
The First Rule of HIE Access Control
The first rule of HIE access control is this: If the one holding the health information is not satisfied with the access control information, then the healthcare information is simply not sent. This basic rule needs to be reiterated because many people get wrapped up in all the discussion about enabling access and forget that ultimately a deny decision is the starting point. Even if the requester has provided all the types of information that could be asked of them, the policy rules can still determine that the access control decision is “no.” Ultimately, if there is no good reason to allow the information to be sent, then it clearly should not be sent. This blunt logic is not the logic that caregivers want to hear, but it is reality because sometimes their request is simply not allowed.
It is a policy decision on how this “no” is returned. The most secure way is to simply indicate no healthcare information exists, which includes denying that the patient even exists. There are others that want to enable smoother workflows through providing a hint that there is healthcare information available but the organization is not authorized to send it. The most secure method is total denial, because it doesn’t expose any information, confirmed nor denied. However, there are different layers of security in an HIE. For example, if one can tell that the requesting system is a trusted system and that there are business rules in place that give assurances that the exposure is small and will be properly handled, permission might be given. Thus, a policy could determine based on the access control information what kind of a response is given.
The Second Rule of HIE Access Control
The second rule of HIE access control is this: Once the healthcare information has been transmitted, it is in the control of the recipient. This again is a rather basic rule, but it is important to the decision. If the sender is not confident that the recipient will properly handle the information, then the sender simply should not send the data (see the first rule). Thus, the sender needs to include access control rules that provide them with comfort that the recipient should be given a copy of the healthcare information. This is typically why the access control information includes the user and the context. The context speaks to the capabilities of the receiving system and how the healthcare information will be managed.
The user-based access control information speaks about the user, but it must be recognized that this is typically just the initial user who will be exposed to the information. You must recognize that for any purpose of use that includes treatment, the healthcare information disclosed will become part of the medical record at the recipient. Thus, a request for a purpose of use of “Treatment” is a request on behalf of the requesting medical record, not simply the user identified.
This rule is not as blunt as it appears; there are policies that can be communicated along with the healthcare information that would control the access at the recipient, but even in these cases, the sender must know that the recipient is going to enforce a policy before sending the healthcare information. There are standards-based methods to assure this.
Use Case 14-3: Negotiating the Policies
A policy negotiation can take place before the healthcare information is actually transferred. The policies that go along with the healthcare information are often referred to as obligations or refrain policies. The use of obligation or refrain is under the control of policies.
Everything is in the hands of the policies. These policies should incorporate federal regulations, state regulations, regional regulations, medical ethics, profes-sional standards of practice, organizational rules, HIE rules of engagement, and the patient consent/authorizations. An HIE is really just an extension of the access control environment. The difference is that the policy space includes the whole of the HIE, including sending and receiving systems and users (recipients).
A specific example of this is a requirement of 42 CFR Part 2,29 in which the data being communicated was gathered originally within a federally funded drug-abuse program. In this case, there is an obligation to not re-disclose the data without get-ting explicit privacy consent from the patient.
HIE Access Control Information
In an HIE, the access control information must come from the different parties in the HIE. This can be a challenge when communicating across organizational boundaries and with a competing organization. The interoperability standards used have been developed specifically with this in mind. The easiest way to describe this is through the example shown in Figure 14-2.

Figure 14-2 Simple HIE access control example
1. The user is authenticated, typically as part of their long-term session in the EHR.
2. At some point, the system queries the HIE and includes information about the user and context along with the query parameters requesting healthcare information, including the patient ID and type of data requested.
3. An access control service intercepts the transaction and inspects the system credentials that are used at the transport level, the user and context captured in the assertion, and the query parameters.
4. The access control service executes all relevant policies, including consent policies; if the policies determine that there is reason to deny access or no reason to allow access, then the access control service responds with no results found.
5. If the information is going forward, the query is forwarded to the resource that processes it normally.
6. The receiver returns the normal results.
The user identity and authentication steps are totally within the control of the organization where the user is using the EHR. It is typical of an HIE that each organization within the HIE is responsible for the user identities from that organization. In theory, there could be a single user identity domain across the HIE, but this turns out to be too difficult to manage. Much of the concern is related to the fact that an HIE is often made up of competing organizations. Another important factor is that many of the users will have different identities within multiple organizations; these identities are different because they have different roles and responsibilities, and most importantly they are identities under the different organizations’ operational environments, including medical records.
There is usually a unified patient identity domain, not just one. Unified means that there is some administrative set of rules and procedures used to create a cross-reference between the patient identifiers within each of the organizations, oftentimes with an HIE master identifier. Getting this cross-reference correct is important to access control, and specifically privacy, but is also very important for patient care and safety. There are many creative ways to do this cross-reference.
This simplified view presumes that the access control decision can be made by inspecting the query parameters and the resource access control information (metadata). Oftentimes, there needs to be more access control decisions on the return path (step 6) as well as within the EHR after the information is received. This simplified view also puts the access control decision within the HIE domain. It could be done in the hospital domain or in other types of resources. The only time that healthcare information will be returned is if the access control decision will allow it.
This simplified view shows a query and response, also known as a pull transaction. The same access control decisions can be made prior to a push transaction. The sender of the push transaction simply must predict who the user and their system capabilities are going to be. The sender clearly knows who the patient and resources are.
Each step of this use-case (1–6) would also be recorded by each system involved in an audit log. In this way, audit control can be used to confirm the system is working as expected, produce privacy reports for the patient, and support other surveillance responsibilities.
Metadata
In the context of access control, this chapter describes resource access control information, which is a specialization of more general-purpose metadata.35 Metadata is associated with data to provide for specific data-handling purposes. These domains of data-handling purposes fall into some general categories. Each metadata element typically has more than one of these purposes, although there are some metadata elements that cover only one purpose. It is important to understand these domains and the purposes of metadata specific to an HIE.
• Patient identity This consists of characteristics that describe the subject of the data. This includes patient ID, patient name, and other patient identity–describing elements.
• Provenance This includes characteristics that describe where the data comes from. These items are highly influenced by medical records regulations. This includes human author, identification of the system that authored the data, the organization that authored the data, processor documents, successor documents, and the pathway that the data took.
• Security and privacy These are characteristics that are used by privacy and security rules to appropriately control the data. These values enable conformance to privacy and security regulations. These characteristics would be those referenced in privacy or security rules. These characteristics would also be used to protect against security risks to confidentiality, integrity, and availability.
• Descriptive This consists of characteristics used to describe the clinical value, so they are expressly healthcare-specific. These values are critical for query models and to enable workflows in all exchange models. This group must be kept to a minimum so that it does not simply duplicate the data and so it keeps risk to a minimum. Thus, the values tend to be from a small set of codes. Because this group is close to the clinical values, the group tends to have few mandatory items, allowing policy to not populate by choice. For healthcare data, this is typically very closely associated with the clinical workflows but also must recognize other uses of healthcare data.
• Exchange This consists of characteristics that enable the transfer of the data for both push-type transfers and pull-type transfers. These characteristics are used for the low-level automated processing of the data. These values are not the workflow routing but rather the administrative overhead necessary to make the transfer. This includes the document unique ID, location, size, types of data, and document format.
• Object life cycle This consists of characteristics that describe the current life-cycle state of the data, including relationships to other data. This includes classic life-cycle states of created, published, replaced, transformed, and deprecated.
All proper metadata elements are indeed describing the data and are not a replacement for the data. Care should be taken to limit the metadata to the minimum metadata elements necessary to achieve the goal. Therefore, each metadata element must be considered relative to the risk of exposing it as metadata. A metadata element is defined to assure that when the element is needed, it is consistently assigned and processed. Not all metadata elements are required; indeed, some metadata elements would be used only during specific uses. For example, the metadata definition inside a controlled environment such as an EHR will be different from the metadata that is exposed in a transaction between systems or the metadata that describes a static persistent object.
User Identity in an HIE
User identity in an HIE is more complex than patient identity or resource information. Here is a case where managing users and their roles and permissions centrally to the HIE is simply not possible. Thus, there is a need to use federated identity. An HIE consists of multiple organizations (e.g., St. Mary Hospital and St. Luke Clinic) that are accessing each other through some HIE. Each organization needs a trust bond with the HIE. Such organizational trust is typically built through some operational certification and legal agreements. This is characterized in Figure 14-3.
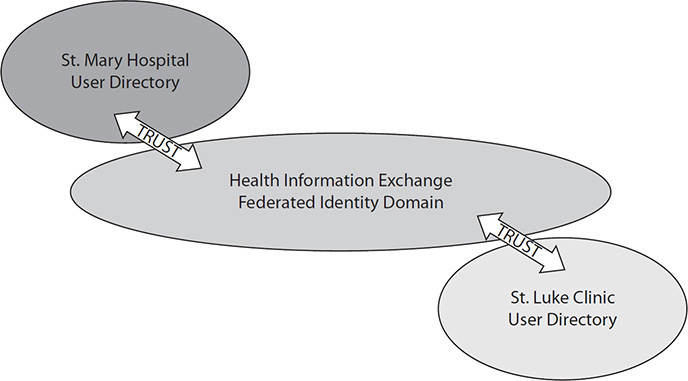
Figure 14-3 Characterization of user identity between two hospitals
For the purpose of use of “Treatment,” the user identity asserted in a request for information is not as important in an HIE. This is not because user identity is not necessary but, rather, because most of the uses of an HIE are system to system or organization to organization. In this mode, the two systems (or organizations) need to trust that the other system has done the appropriate preconditions and will do the appropriate postconditions. This is a policy: Do not let a system connect that you do not trust has the appropriate governance. In other words, you want to be sure the client machine has done the appropriate user authentication and authorization and is otherwise a secure system. The communication is highly authenticated on both the client and the server and is fully encrypted. The result returned to the client will be properly handled, the information will be exposed only to authorized individuals, and audit logs will be captured of all accesses from that point forward. If you add a user identity to this transaction, it is mostly for a little bit better audit log on the service side.
The other side of this is that even if a user identity were provided, it would be about the user who is currently connecting. The returned healthcare information will be stored in the requesting EHR, and others on the EHR will gain access. So, although the initial connection could be access-controlled, the other future accesses within the EHR must be trusted to do the right thing.
If you look at an EHR today, it has user authentication and access controls that have been built up over time to meet the requirements of being an EHR. The user authentication likely is highly flexible to support some rather complex workflows. One of the complex workflows is the ambulatory exam room, where an administrative person walks the patient to an exam room and sets up the exam room’s terminal with the right patient and then “locks the screen.” Next, the nurse comes in to take the chief complaints and vital signs. The nurse logs in, enters the data, and logs out. Next, the doctor comes in for the exam, again logs in to view and enter data, and logs out. Each of these people is authenticating, but the workflow on the desktop is all about the patient. These authentication methods and authorization methods are sufficient to protect the healthcare information that is maintained in that EHR. It is possible that an organization has gone to an enterprise-class authentication system like Microsoft Active Directory or more generically Kerberos or LDAP, but this is not required.
Let’s look at interacting with an HIE or other organization that requires a SAML assertion, as shown in Figure 14-4 for identity management. The SAML assertion is issued by an identity provider that supports SAML. This identity provider is configured to understand specific services (relying parties) of the SAML assertions (known in SAML terms as an audience). The configuration will include mapping tables. Mapping tables indicate that when creating the SAML assertion for use within a specific HIE, some list of attributes needs to be added to the assertion. One likely attribute is the user’s role, using a vocabulary known in the HIE versus the local EHR names of roles. Thus, a physician or other healthcare provider is known by a local EHR, but if the HIE wants the role to come from a different value set where the role within the HIE would be “caregiver,” then it is up to the identity provider to do this mapping. This is a common thing for identity providers to do, because role vocabulary is not stable within any organization (not just healthcare) nor is it likely to be stable in the HIE. What is important to recognize is that the SAML assertion is issued by an identity provider that does this mapping. The user directory does not need to have the HIE roles.
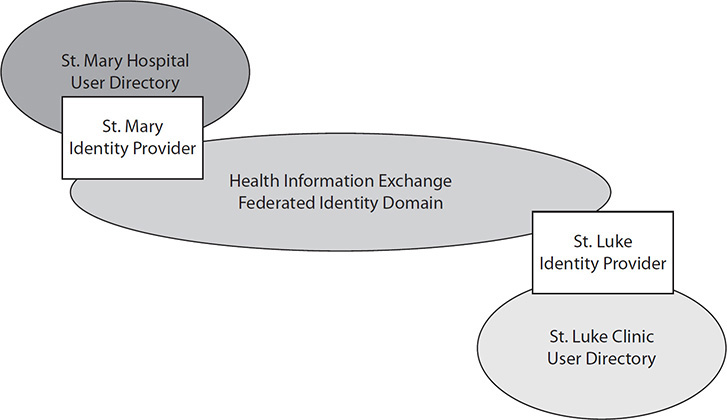
Figure 14-4 A representation of SAML
When this SAML assertion is received by the service provider, it is validated. The validation process checks that it was issued by an identity provider that is on the trusted identity provider list. This allows the service provider to support many different identity providers, likely one for each clinic and hospital connecting to the HIE. Given that all of those identity providers have normalized their roles to the HIE role vocabulary, it is clear what permissions the user should have in the context of this transaction in the HIE.
The identity provider functionality is available for most enterprise-class user-authentication systems. The WS-Trust protocol is commonly the one used to get SAML assertions issued. Federated identity decouples the task of identity management and the process of human authentication from claims of proof of authenticity within the HIE that are used for access control decisions and audit logging. The user management within any organization can be specific to that organization. Organizations are free to use proprietary means of user authentication, HTML-Forms, Kerberos, LDAP, OpenID, OAuth, or any other method. Through the conversion of these identities and authentication systems into an HIE agreed-upon federated identity, the HIE has a trusted identity system.
A few interoperability standards (such as X.509 digital certificates and SOAP) are used to support federated identity. They each have their strengths and weaknesses. The choice is often based on the technology used for the transport. Note that technologies such as SAML can bridge these environments through a trusted identity broker using WS-Trust, the interoperability standard. In this way, a user can use OpenID with their mobile device and talk to the web servers that the mobile device interfaces with. These web servers can bridge to SOAP transactions that need SAML assertions and secure e-mails that need an X.509 digital certificate.
Access Control Languages
Much standards work has been devoted to access control languages and ways to communicate policy. The most often cited is Extensible Access Control Markup Language (XACML).35 XACML is both a policy encoding and an infrastructure for deploying access control decisions and enforcement. XACML can be used with any identity management system, although it is usually associated with SAML. There is no specific tie between SAML and XACML, although they do leverage much of the same infrastructure.
As a policy encoding language, XACML is powerful, made up of logic fundamentals that can be combined into any rules possible. The rules, however, need to invoke domain-specific vocabulary, such as for roles, permissions, object types, confidentiality codes, sensitivity evaluations, patient identities, and so on. There are also vocabularies for fractions of policies such as purpose of use, obligations, refrain, and broadly applicable consent. These vocabularies are the ones that healthcare-standards organizations are working to develop, with some of them well understood for HIE use. These vocabularies are needed regardless of whether XACML is used as the policy encoding language.
As an access control decision and enforcement system, XACML is a highly modular system; however, implementations are highly customized to fit into transactions and workflows.
Chapter Review
This chapter introduced the basics of access control and showed how to apply the controls to an EHR and a healthcare information exchange. The basics of access control rely on user identity provisioning and deprovisioning providing a specified level of assurance to each user identity. Human users will authenticate to computer systems using various types of authentication technology: combinations of something they have, something they know, and something they are. The access control decisions are based on the user identity but also information about the patient, the resources, and the context of the access to healthcare information. Policies are the rules that define what can and cannot be done and call upon the access control information to make the decisions. Patient privacy and consents are a subset of policies specific to that patient and their preferences. When extending access control across a healthcare information exchange, the various access control information comes together in a cooperative access control. The access control decision in an HIE delivers data only when the access control policies authorize the information to flow.
Questions
To test your comprehension of the chapter, answer the following questions and then check your answers against the list of correct answers that follows the questions.
1. What is the level of assurance of identity proofing that requires the presentation of a government-issued identity but does not require verification of that government-issued identity?
A. Level 1
B. Level 2
C. Level 3
D. Level 4
2. Identify the factors that a computer uses to authenticate a human user.
A. Something you are, have, and know
B. Something with an image of you on it
C. Something that you know, like a secret
D. None of the above
3. What does SAML do?
A. Provisions user accounts
B. Makes access control decisions
C. Defines an identity claim
D. Provides an audit logging system
4. What are the components of RBAC?
A. Identity, permission, role
B. Consent only
C. Permission and consent
D. Role and consent
5. What are the operations on a class of objects that make up a permission?
A. Identity, authentication, authorization, and consent
B. Authentication, authorization, and identity
C. Consent, identity, and authorization
D. Create, read, update, delete, and execute (aka CRUDE)
6. What is the policy pointer axiom?
A. Data should not include the policy rules; the policy rules should point at the data they apply to.
B. Data should always be pointed to in policies.
C. Policy rules should never point to data.
D. None of the above.
7. What is federated identity?
A. It includes the concepts of authentication, authorization, and identity.
B. It provides a mechanism for communicating claims of identity and authentication to a relying party in a way that can be understood and trusted.
C. Identity can never be federated.
D. None of the above.
8. What standard can be used to harmonize different identity and authentication systems?
A. WS-Trust
B. WAP
C. Wi-Fi
D. WEP
9. What authentication standard is best paired with FHIR®?
A. SOAP
B. kAuth
C. OAuth
D. Password
10. What is it called when one system asks another to enforce a policy fragment?
A. Liability
B. Obligation
C. Commitment
D. Permission
11. What is the critical fact about healthcare data that separates it from other data?
A. It is large.
B. It is detailed.
C. It can’t be changed or revoked.
D. There is nothing special about healthcare data.
12. What type of security information is time of day?
A. Permission
B. Role
C. Label
D. Context
13. Which of the following is not a principle of privacy?
A. The purpose for data collection should be known, limited, and stated.
B. An individual (patient) should have the right to see the data that has been collected and correct it if it is found to be inaccurate.
C. The data should be controlled against any inappropriate use or access.
D. The data must be digitally signed.
Answers
1. B. Level 2 requires presenting government-issued identification that includes your full name, picture, and address or nationality; it does not require that the identity be proven as authentic.
2. A. Authentication factors are something you are (biometric), have (hardware token), or know (password).
3. C. SAML defines a way to convey an identity and authentication claim from one party to a relying party.
4. A. RBAC is a binding between an identity, role, and permission. Thus, it does not include consent.
5. D. The fundamental actions that make up a permission are create, read, update, delete, and execute (aka CRUDE).
6. A. Data should not include the policy rules; the policy rules should point at the data to which they apply.
7. B. Federated identity keeps local the identity management task by providing a mechanism for communicating claims of identity and authentication to a relying party in a way that can be understood and trusted.
8. A. WS-Trust is the standard used to harmonize different identity and authentication systems.
9. C. OAuth is considered the best security protocol for use with HL7 FHIR® along with HTTPS. Note that client certificates and SAML are also used.
10. B. When a sending system needs a receiving system to enforce a policy fragment, and it knows that the receiving system can enforce this policy fragment, then it would convey the policy fragment using an obligation. An obligation might be explicit or implied.
11. C. Healthcare data can’t be changed or revoked, thus it is extra important to protect against inappropriate disclosure. Healthcare data also are often used to make life-critical or lifesaving decisions.
12. D. Time of day is part of the context of the transaction.
13. D. Digital signatures are not a principle of privacy. Digital signatures are used to provide proof of provenance, or proof of action. They might be used to sign a privacy consent.
References
1. The White House. (2011, April). National strategy for trusted identities in cyberspace: Enhancing online choice, efficiency, security, and privacy. Accessed from www.nist.gov/sites/default/files/documents/2016/12/08/nsticstrategy.pdf.
2. Burr, W. E., Dodson, D. F., Newton, E. M., Perlner, R. A., Polk, W. T., Gupta, & Nabbus, E. A. (2013). Electronic authentication guideline (NIST SP 800-63-2). Accessed from http://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-63-2.pdf.
3. Kantara Initiative. (2009). Identity assurance framework: Assurance levels, draft 04. Accessed from http://kantarainitiative.org/confluence/download/attachments/38371432/Kantara+IAF-1200-Levels+of+Assurance.pdf.
4. Integrating the Healthcare Enterprise (IHE). (2012). Enterprise user authentication (EUA) profile. Accessed from www.ihe.net/uploadedFiles/Documents/ITI/IHE_ITI_TF_Vol1.pdf.
5. IHE. (2012). Cross-enterprise user assertion (XUA) profile. Accessed from www.ihe.net/uploadedFiles/Documents/ITI/IHE_ITI_TF_Vol1.pdf.
6. ASTM International. (1998). Standard guide for user authentication and authorization (ASTM E1985-98). Accessed from www.astm.org/Standards/E1985.htm.
7. ASTM International. (1995). Standard guide for electronic authentication of health care information (ASTM E1762-95). Accessed from www.astm.org/Standards/E1762.htm.
8. Chokhani, S., Ford, W., Sabett, R., Merrill, C., & Wu, S. (2003). Internet X.509 public key infrastructure certificate policy and certification practices framework (RFC 3647). Accessed from http://tools.ietf.org/html/rfc3647.
9. ISO. (2013). Health informatics: Public key infrastructure—Part 1: Overview of digital certificate services (ISO 17090-1:2013). Available at www.iso.org/iso/home/store/catalogue_tc/catalogue_detail.htm?csnumber=63019.
10. Joint NEMA-MITA/COCIR/JIRA Security and Privacy Committee (SPC). (2007). Management of machine authentication certificates. Accessed from www.medicalimaging.org/wp-content/uploads/2011/02/CertificateManagement-2007-05-Published.pdf.
11. Hardt, D. (Ed.). (2012). The OAuth 2.0 authorization framework (RFC 6749). Accessed from https://tools.ietf.org/html/rfc6749.
12. Hammer-Lahav, E. (Ed.). (2010) The OAuth 1.0 protocol (RFC 5849). Accessed from https://tools.ietf.org/html/rfc5849.
13. OpenID HEART Workgroup. (n.d.). What Is HEART WG? Accessed from http://openid.net/wg/heart/.
14. IHE. (2015). Internet user assertion profile: Profile on OAuth 2.0 for use with FHIR.® Accessed from www.ihe.net/uploadedFiles/Documents/ITI/IHE_ITI_TF_Vol1.pdf.
15. SMART Health IT. (n.d.). An app platform for healthcare. Accessed from http://smarthealthit.org/.
16. IHE. (2012). Personnel white pages (PWP) profile. Accessed from www.ihe.net/uploadedFiles/Documents/ITI/IHE_ITI_TF_Vol1.pdf.
17. ISO. (2013). Health informatics: Directory services for healthcare providers, subjects of care and other entities (ISO 21091:2013). Available at www.iso.org/iso/home/store/catalogue_ics/catalogue_detail_ics.htm?csnumber=51432
18. IHE. (2015). IHE IT infrastructure technical framework supplement: Healthcare provider directory (HPD). Accessed from www.ihe.net/uploadedFiles/Documents/ITI/IHE_ITI_Suppl_HPD.pdf.
19. IHE. (2012). Audit trail and node authentication (ATNA) profile. Accessed from www.ihe.net/uploadedFiles/Documents/ITI/IHE_ITI_TF_Vol1.pdf.
20. Dierks, T., & Rescorla, E. (2008). The transport layer security (TLS) protocol: Version 1.2 (RFC 5246). Accessed from http://tools.ietf.org/html/rfc5246.
21. SAML v2.0. Accessed from https://wiki.oasis-open.org/security/FrontPage.
22. DeCouteau, D. (Ed.). (n.d.). XSPA profile of SAML v2.0 for healthcare version 1.0. Accessed from https://wiki.oasis-open.org/security/XSPASAML2Profile.
23. Moehrke, J. (2009). Healthcare security/privacy blog. Accessed from http://HealthcareSecPrivacy.blogspot.com.
24. Incits (International Committee for Information Technology Standards). (2004). Information technology: Role-based access control. https://standards.incits.org/apps/group_public/project/details.php?project_id=1658.
25. IHE. (2012). Access control white paper. See Caumanns, J., Kuhlisch, R., Pfaff, O., & Rode, O. (2009, Sept. 28). IHE IT infrastructure technical framework white paper: Access control. Accessed from www.ihe.net/Technical_Framework/upload/IHE_ITI_TF_WhitePaper_AccessControl_2009-09-28.pdf.
26. ISO. (2116). ISO/CD 13606-4: Health informatics: Electronic health record communication: Part 4: Security. Available at www.iso.org/iso/home/store/catalogue_ics/catalogue_detail_ics.htm?csnumber=62306.
27. ASTM International. (2009). Standard guide for information access privileges to health information (ASTM E1986-09). Accessed from www.astm.org/Standards/E1986.htm.
28. ASTM International. (2007). Standard guide for privilege management infrastructure (ASTM E2595-07). Accessed from www.astm.org/Standards/E2595.htm.
29. Electronic Code of Federal Regulations. (1987). Confidentiality of alcohol and drug abuse patient records, 42 CFR Part 2. Accessed from www.ecfr.gov/cgi-bin/text-idx?rgn=div5;node=42%3A1.0.1.1.2.
30. IHE. (2012). Basic patient privacy consents (BPPC). Accessed from www.ihe.net/uploadedFiles/Documents/ITI/IHE_ITI_TF_Vol1.pdf.
31. ISO. (2014). ISO 22600-1:2014: Health informatics: Privilege management and access control: Part 1: Policy overview and management. Available at www.iso.org/iso/home/store/catalogue_ics/catalogue_detail_ics.htm?csnumber=62653.
32. Witting, K., & Moehrke, J. (2012, Jan. 24). IHE IT infrastructure white paper—Health information exchange: Enabling document sharing using IHE profiles. Accessed from www.ihe.net/Technical_Framework/upload/IHE_ITI_White-Paper_Enabling-doc-sharing-through-IHE-Profiles_Rev1-0_2012-01-24.pdf.
33. IHE IT Infrastructure Technical Committee. (2008, Dec. 2). IHE IT white paper: Template for XDS affinity domain deployment planning. Accessed from www.ihe.net/Technical_Framework/upload/IHE_ITI_TF_WhitePaper_AccessControl_2009-09-28.pdf.
34. Scholl, M., Stine, K., Lin, K., & Steinberg, D. (2010). Security architecture design process for health information exchanges (HIEs). NIST IR7497. Accessed from http://nvlpubs.nist.gov/nistpubs/Legacy/IR/nistir7497.pdf.
35. Moehrke, J. (2012, May 4). Healthcare metadata. Available at https://healthcaresecprivacy.blogspot.com/2012/05/healthcare-metadata.html.
*Portions of this chapter are adapted with permission from John Moehrke, Healthcare Security/Privacy, http://healthcaresecprivacy.blogspot.com/. © John Moehrke.