
CHAPTER 29
Architectural Safeguards
Lisa A. Gallagher
In this chapter, you will learn how to
• Describe the importance of architectural safeguards for designing, building, purchasing, and implementing safe and secure IT systems and medical devices
• Define the relationship between reliability, availability, and safety as they impact healthcare IT systems
• Identify basic design considerations for high-reliability healthcare IT systems
The introduction of certain technology platforms, such as electronic health records (EHRs), has highlighted concerns about the privacy, security, and availability of patient records. Other examples of IT systems used in healthcare enterprises include billing/financial systems, clinical decision support (CDS) systems, and databases/data analytics software. At the same time, the evolution of the consumer-based mobile device and application market has created a desire to integrate mobility solutions into the clinical and patient workflow.
Finally, there is one other critical category of IT system/component that is used in the healthcare workflow today—medical devices. Here are the most common categories of medical devices that are currently used in healthcare organizations:
• Monitoring Typically used to measure and track physiological aspects of patient health (for example, a heart monitor)
• Resuscitative Used to restore normal brain or heart function (for example, a defibrillator)
• Surgical Used to aid surgical procedures (for example, medical lasers)
• Imaging Used to obtain a medical image for diagnostic purposes (for example, an X-ray machine)
Each category listed contains one example of medical devices that are not only implemented in technology but have evolved to contain software operating systems, connect to and share data through information networks, and even to operate remotely through wireless technical or cellular networks. Increased use of mobile medical devices is expected to be a trend as the healthcare industry looks for new, cost-saving, and safe ways to expand and improve healthcare services (for example, to reach underserved or remote populations).
When designing or building an IT system, all aspects of the system’s architecture—its individual hardware and software components—must be considered. An IT system design-and-build process demands that various architectural considerations related to the components’ features, functions, and desired performance (in terms of measurable attributes or parameters of the system performance) are set out as requirements, based on the needs of the users and the operational environment. The goal and the desired outcome is to design, build, purchase, and implement safe and secure IT systems and components for use in healthcare.
Reliability
One important performance trait of an IT system is its reliability. Reliability is the “degree to which a system, product, or component performs specified functions under specified conditions for a specified period of time.”1 Table 29-1 shows several ways to specify and measure the reliability of an IT system.
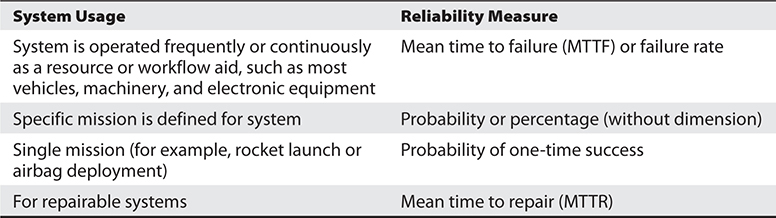
Table 29-1 System Reliability Measures

NOTE System reliability, by definition, includes all parts of the system—hardware, software, supporting infrastructure (including critical external interfaces), operators, and procedures.
For the software components of a system, a common reliability metric is the number of software faults, usually expressed as faults per thousand lines of code. This measure, along with software execution time, is key to most software reliability models and estimates.
Relationship Between Reliability and Security
Software errors, defects, and logic flaws, often stemming from poor coding practices, can be a cause of commonly exploited software vulnerabilities. For example, programming errors in the software of an IT system can introduce security vulnerabilities (weaknesses in the system that allow exploitation) in the following areas:
• Authentication of users (for example, improperly authenticating a potential user)
• Authorization of access rights and privileges (for example, allowing unauthorized access)
• Data confidentiality (for example, allowing unauthorized access)
• Data integrity (for example, allowing unauthorized modification or deletion of data)
• Data availability (for example, preventing data from being accessed when needed)
Other problems or defects that affect security are hardware defects; inadequate site access, monitoring policies, and procedures; and lack of employee performance and monitoring policies and procedures. These are examples of “system” vulnerabilities that are not directly related to the software.
Reliability Implications for Healthcare Systems
For all IT systems, design and performance considerations are critical to meeting system mission goals and foundational to technical security considerations. The goal is to design the software and other system elements to have as few defects and failures as possible. For healthcare, the consequences of IT system failures can be severe, including
• Risk to patient outcomes, health, and lives
• Data security breaches (manifesting as unauthorized data access, compromise of data integrity, and/or system or data availability issues)
• Public health implications
• Research implications
• Cost implications
• Reputational impact
• Legal/regulatory compliance implications
Reliability goals should be considered and identified for all care scenarios and processes. For hospitals, this may mean that these goals might be defined by system, department, or workflow. For a physician office, it is likely to include the workflow and integration of the IT system.
For each system or process, failure (and how it can be detected or measured) should be defined and then reliability goals associated with the desired improvement or outcome should be set according to a reliability analysis. For example, in the emergency room, one measure of failure is the percentage of patients receiving the wrong diagnosis, treatment, or medication. A reliability analysis can be conducted at the system or component level. All analyses should include the software, hardware, physical, and employee components as discussed previously.
Understanding the relationship between reliability and healthcare is critical as IT systems are increasingly integrated into the clinical workflow.
Availability
System availability is the property of the system being accessible and usable upon demand by an authorized entity.2 Simply put, availability is the proportion of time a system is functioning.
The availability of a system is typically measured as a factor of its reliability—as reliability increases, so does availability. No system can guarantee 100 percent reliability; therefore, no system can assure 100 percent availability.
Availability as a Component of Data Security
There are three main components, or goals, of data security (together, these are commonly called the “CIA” of data security):
• Confidentiality
• Integrity
• Availability
Information or data security is concerned with the confidentiality, integrity, and availability of data regardless of the form it may take—electronic, print, or other forms.
With respect to electronic health data, data availability is a critical issue. For any healthcare IT system to serve its purpose, the information (for example, patient data and ancillary data, decision support data, references, alerts, etc.) must be available when it is needed. This means that the computing systems used to store and process the information, the security controls used to protect it, and the communication channels used to access it must be functioning correctly. The goal of high-availability systems is to remain available at all times, preventing service disruptions due to power outages, hardware failures, and system upgrades. Ensuring availability also involves preventing denial-of-service attacks (attacks meant to disrupt system and/or data access by users). There are several categories of security controls used to ensure/protect data availability:
• Technical Security controls (i.e., safeguards or countermeasures) for an information system that are primarily implemented and executed by the information system through mechanisms contained in the hardware, software, or firmware components of the system.3
Examples include firewalls and data encryption.
• Administrative (Operational) The security controls (i.e., safeguards or countermeasures) for an information system that are primarily implemented and executed by people (as opposed to systems).3
Examples include organizational policies and procedures.
• Physical Physical measures, policies, and procedures to protect a covered entity’s electronic information systems and related buildings and equipment from natural and environmental hazards, and unauthorized intrusion.4Examples include any doors, locks, and security guards.
Maintainability
Maintainability for IT systems can be defined as the capability of the software product to be modified. Modifications may include corrections, improvements, or adaptation of the software to changes in environment, requirements, and/or functional specifications.1 Maintainability affects both reliability and availability of IT systems and components.
Scalability
Scalability is the ability of a system, network, or process to handle a growing amount of work in a capable manner or the ability of a system, network, or process to be enlarged to accommodate that growth.5 When an organization is considering its design or purchase requirements for healthcare IT systems, it should also consider its ability to easily and quickly enhance the system by adding new functionality and/or storage capacity. A system that can easily “scale” to meet new requirements enables an organization to invest in technology based on current needs without having to replace the system when requirements change.
The term cloud computing is defined by the National Institute of Standards and Technology (NIST) as “a model for enabling ubiquitous, convenient, on-demand network access to a shared pool of configurable computing resources (e.g., networks, servers, storage, applications, and services) that can be rapidly provisioned and released with minimal management effort or service provider interaction.”6 Healthcare organizations are beginning to take advantage of the ability to “outsource to the cloud” (contract for IT services or system usage) in order to address the scalability issue. This allows the organizations to facilitate rapid provisioning of additional computing, application, and storage resources and avoid some capital expenditures.
Scalability can also be thought of as a measure of how well a system or application can grow to meet increasing performance demands. In thinking this way, one can see that scalability is a factor for both availability and reliability.
Safety
“Safety” in medicine is often used to mean patient safety. The Institute of Medicine (IOM), which is now called the Academy of Medicine (NAM), has defined patient safety as “the prevention of harm to patients.”7 An event during an episode of care that causes harm to a patient is called an adverse event. Patient safety overlaps in many ways with privacy, security, and technology concerns, which we will discuss later in this chapter.
With respect to system and software design, safety means that a life-critical system behaves as needed even when some components fail. Systems that are to be used in healthcare should be designed so that if failure occurs, it will not cause a patient to be physically harmed.
Considerations for Healthcare IT Systems
Ideally, in the early design of a system, the design is analyzed to determine what faults can possibly occur. That analysis is then used to identify the safety requirements.

TIP The most common method used to identify possible faults is the failure mode and effects analysis (FMEA).8
The FMEA (see IEC 60812) provides for an evaluation of potential failure modes for processes and their likely effect on outcomes and/or product performance. Once failure modes are established, risk reduction can be used to eliminate, contain, reduce, or control the potential failures. The effects of the failure mode are described and assigned a probability based on the predicted failure rate and failure mode ratio of the system or components. Failure modes with identical or similar effects can be combined and summarized in a failure-mode effects summary. When combined with criticality analysis, FMEA is known as failure mode, effects, and criticality analysis (FMECA).
In general terms, once a failure mode is identified, it can usually be mitigated by adding extra or redundant equipment to the system. Ongoing maintenance actions are also important safety-related actions. With regard to maintenance activities, considerations must be taken to reduce operational risk by ensuring acceptable levels of operational readiness and availability.
The overall patient-safety concerns of a healthcare organization can be met only by defining system safety requirements early on in the design and/or acquisition process of a healthcare IT system and performing a FMEA and/or FMECA to identify and mitigate faults.
Safety analysis is focused on safety-critical systems or components. Reliability analysis has a broader scope than safety analysis, because noncritical failures must also be considered. Higher failure rates may be considered acceptable for noncritical systems.
Considerations for Medical Devices
Medical devices are considered safety-critical devices. They are regulated as such by the U.S. Food and Drug Administration (FDA).
TIP The FDA reviews applications from medical-device manufacturers and approves them to sell medical devices on the open market. It also reviews any substantial changes to the medical-device system, software, or other components.
The FDA also monitors reports of adverse events and other problems with medical devices and alerts health professionals and the public when needed to ensure proper use of devices and the health and safety of patients. The FDA posts lists of recent medical-device recalls and other FDA safety communications on its safety web site, https://www.fda.gov/safety.
The FDA has also recently begun to oversee the deployment and use of mobile medical devices and mobile medical applications (apps). A mobile medical device is a device that exchanges data with other devices or computers over a wireless network. Mobile apps are software programs that run on smartphones and other mobile communications devices and in most cases communicate over a cellular network. Development of mobile medical apps is opening new and innovative ways for technology to improve health and healthcare.
Consumers use mobile medical apps to manage their own health and wellness. Healthcare professionals are using these apps to improve and facilitate patient care. These apps include a wide range of functions, from allowing individuals to monitor and input their blood levels for diabetes maintenance to allowing doctors to view a patient’s X-rays on their mobile communications device. The FDA encourages further development of mobile medical apps that improve healthcare and provide consumers and healthcare professionals with valuable health information very quickly.
The FDA has a public health responsibility to oversee the safety and effectiveness of a small subset of mobile medical apps that present a potential risk to patients if they do not work as intended. In order to balance patient safety with innovation, the FDA has published guidance for manufacturers and developers of mobile medical apps, including clear and predictable outlines of FDA expectations during the approval process. The guidance, released on February 9, 2015, defines a small subset of mobile medical apps that may impact the performance or functionality of currently regulated medical devices and therefore will require FDA oversight.9
Beginning in 2020, the FDA requires a Unique Device Identification (UDI).10 When fully implemented, the UDI will add to security in providing a secure distribution chain of devices globally, helping to address counterfeiting and prepare for medical emergencies. Further, UDIs will provide a standard to document device use in electronic health records, clinical information systems, claim data sources, and registries.
Considerations for Design of High-Reliability Healthcare Systems
In the design of safety-critical systems, one of the first tasks is to adequately specify the reliability and maintainability requirements as defined by the stakeholders in terms of their overall availability needs. There are several design techniques that are important to employ when designing or evaluating an IT system or component.
Fail-Safe Design
A fail-safe system is designed to return to a safe condition in the event of a failure or malfunction. A fail-safe or fail-secure medical system or device is one that, in the event of failure, responds in a way that is predictable and will cause no harm to other devices or danger to patients or personnel.
A system is fail-safe not because failure is impossible or improbable but because the system’s design prevents or remediates unsafe consequences of the system’s failure—that is, if a system fails, it remains safe, or at least no less safe than when it is operating correctly.11
It is important to note also that a fail-safe design may indicate that, under certain circumstances, a component should be shut down (forced to violate its functional specification) in order to avoid harming someone.
A fail-secure component of a system secures that system (or at least the portion to which the component is dedicated) in the event of a failure either of that component or elsewhere in the system.
Fail-safe designs are particularly critical for medical devices that are connected to patients and would be part of the safety testing by the FDA.
Fault Tolerance
Fault tolerance (sometimes called graceful degradation) is the capability of the software product to maintain a specified level of performance in cases of software faults or of infringement of its specified interface.1
For an individual system, fault tolerance can be achieved by anticipating conditions outside normal operating parameters and building the system to deal with them—in general, aiming for self-stabilization so that the system converges toward a safe state. However, if the consequences of a system failure are catastrophic, or the cost of making it sufficiently reliable is very high, a better solution may be to use some form of duplication or redundancy (discussed next). Fault tolerance is particularly sought after in high-availability or life-critical systems.
Redundancy and Failover
One of the most important design techniques is redundancy. Redundancy refers to the ability to continue operations in the event of component failures through managed component repetition. In the case of information technology, it can be applied to infrastructure components such as hardware, power supply, software, and information itself. Component repetition for the purpose of providing redundancy is geared toward the avoidance of single points of failure.12 Designing with redundant or duplicate components or resources requires creating alternate operational paths, such as backups or duplicate systems or components, that will be used if particular parts of the system fail.
Failover refers to the process of automatically switching to a different, redundant system upon failure or abnormal termination of the currently active system. Failover can be applied to a cluster of servers, to network or storage components, or to any other set of redundant devices that must provide high availability because downtime would be expensive or inconvenient. It may be implemented in hardware, software, or in a combination of hardware and software.13
Failover and switchover are essentially the same operations, except that failover is automatic and usually operates without warning, while the term switchover means that the process requires human intervention. Failover capability is designed into systems requiring continuous availability and a high degree of reliability. Failover in the context of information technology refers to the process of changing the status of a standby system to become the primary system in the case of a failure in the original primary system. Failover is commonly used in database systems as part of a high-availability and disaster-recovery (HADR) design. Failover provides a high level of fault tolerance and high availability that is transparent to the end user.13
Simplicity
The simpler the system or component design, the more easily or predictably the system can fail and/or recover. Simplicity in design can be seen as the opposite of complexity. For example, complex software means more lines of code, more interfaces, and so on. The greater the number of code lines and/or interfaces, the greater the possibility of unforeseen errors and unsafe consequences. Complex design also results in more security concerns, because coding errors, bugs, and other factors can create greater vulnerability to security threats.
In order for a system or component to meet reliability and availability requirements and avoid security vulnerabilities, a “design-for-simplicity” approach should be used. Designs should purposefully be designed for simplicity at the component, interface, and system level and the design-review process should include consideration of simplicity.
Chapter Review
This chapter described the importance of using architectural safeguards in designing, building, purchasing, and implementing safe and secure IT systems and medical devices. When designing or building an IT system, all aspects of the system’s architecture—its individual hardware and software components—must be considered. The IT system design-and-build process mandates that various architectural considerations related to the components’ features, functions, and desired performance are defined in the requirements. The overall goal is to design, build, purchase, and implement safe and secure IT systems and components for use in healthcare. The reader should understand the relationships between reliability, availability, scalability, and safety. In addition, the chapter discussed the basic design considerations of a reliable system, including fail-safe design, fault tolerance, redundancy and failover, and simplicity.
Questions
To test your comprehension of the chapter, answer the following questions and then check your answers against the list of correct answers that follows the questions.
1. Which of the following is an example of an administrative control?
A. Firewall
B. Fence
C. Organizational policy
D. Security guard
2. How is a system’s, product’s, or component’s reliability defined?
A. The degree to which a system, product, or component performs specified functions under specified conditions for a specified period of time.
B. The measure of the product’s safety, efficiency, and effectiveness
C. Its ease of use
D. Assurance that the product is without fault
3. Which of the following can directly affect a system’s reliability?
A. Organizational policies
B. Employee training
C. Poor coding practices
D. Unauthorized access
4. What does FMEA stand for?
A. Federal management event archives
B. Failure management event archive
C. Failure mode and effects analysis
D. None of the above
5. For which reason would a government agency be concerned about mobile devices/apps used to treat or monitor patients?
A. The mobile device may be too expensive for the patient.
B. The reliability and effectiveness of a mobile app used with a patient could present a potential risk to patient safety.
C. Use of mobile medical devices is not yet reimbursable by Medicare.
D. Use of a mobile medical app is not consistent with medical guidelines.
6. What should systems be designed to do if they fail?
A. Roll over to a different system
B. Do no harm to the patient
C. Contain backups
D. Contain an audit of failures
7. How is a system’s maintainability defined?
A. It can be modified.
B. It is fail-safe.
C. It is redundant.
D. It is rolled over.
8. How is scalability defined?
A. A system that allows integration of multiple patient records
B. A system capable of growth
C. A system that is geographically diverse
D. A system that provides multiple layers
Answers
1. C. An organizational policy is an example of an administrative control.
2. A. Reliability is the “degree to which a system, product, or component performs specified functions under specified conditions for a specified period of time.”
3. C. Poor coding practices can create vulnerabilities that can affect system reliability.
4. C. FMEA is the acronym used for failure mode and effects analysis.
5. B. A government agency would be concerned with the reliability and effectiveness of a mobile app to ensure that it doesn’t present a potential risk to patient safety.
6. B. If a system fails, it should be designed to do no harm to the patient.
7. A. Maintainability is defined as a system’s ability to be modified.
8. B. Scalability means a system is capable of growth.
References
1. ISO. (2001). Software engineering—Product quality: Part 1, Quality model. ISO/IEC 9126-1:2001. Accessed on March 9, 2017, from. https://www.iso.org/standard/35733.html.
2. ISO. (1989). Information processing systems—Open systems—Basic reference model: Part 2, Security architecture. ISO 7498-2:1989. Accessed on August 4, 2016, from https://www.iso.org/standard/14256.html.
3. National Institute of Standards and Technology (NIST). (2012, September). Guide for conducting risk assessments: Information security. SP 800-30, revision 1. Accessed on August 4, 2016, from http://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-30r1.pdf.
4. U.S. Department of Health and Human Services (HHS). (2012). HIPAA FAQs for professionals: What does the Security Rule mean by physical safeguards? Accessed on August 4, 2016, from https://www.hhs.gov/hipaa/for-professionals/faq/2012/what-does-the-security-rule-mean-by-physical-safeguards/index.html.
5. Bondi, A. B. (2000). Characteristics of scalability and their impact on performance. Proceedings of the 2nd International Workshop on Software and Performance (pp. 195–201), Ottawa, Ontario, Canada.
6. NIST. (2011, September). The NIST definition of cloud computing (SP 800-145). Accessed on August 4, 2016, from http://nvlpubs.nist.gov/nistpubs/Legacy/SP/nistspecialpublication800-145.pdf.
7. Mitchell, P. H. (2008). Defining patient safety and quality care. In R. G. Hughes (Ed.), Patient safety and quality: An evidence-based handbook for nurses. Agency for Healthcare Research and Quality. Accessed on August 4, 2016, from https://www.ncbi.nlm.nih.gov/books/NBK2681.
8. International Electrotechnical Commision (IEC). (2006). Analysis techniques for system reliability: Procedure for failure mode and effects analysis (FMEA), second edition. IEC 60812. Accessed on August 4, 2016, from https://www.saiglobal.com/PDFTemp/Previews/OSH/iec/iec60000/60800/iec60812%7Bed2.0%7Den_d.pdf.
9. FDA. (2015, Feb. 9). Guidance for Industry and Food and Drug Administration staff: Mobile medical applications. Accessed on August 4, 2016, from https://www.fda.gov/downloads/medicaldevices/deviceregulationandguidance/guidancedocuments/ucm263366.pdf.
10. FDA. (2015, May 6). Benefits of a Unique Device Identification (UDI) system. Accessed on August 5, 2016, from https://www.fda.gov/MedicalDevices/DeviceRegulationandGuidance/UniqueDeviceIdentification/BenefitsofaUDIsystem/default.htm.
11. Krutz, R. L., & Fry, A. J. (2009). The CSSLP prep guide: Mastering the certified security software lifecycle professional. John Wiley and Sons.
12. Schmidt, K. (2006). High availability and disaster recovery: Concepts, design, implementation. Springer.
13. Chen, W., Otsuki, M., Descovich, P., Arumuggharaj, S., Kubo, T., & Bi, J. Y. (2009). High availability and disaster recovery options for DB2 on Linux, Unix, and Windows. IBM Redbooks.