
In this recipe, we will learn how to answer questions about the content of a specific image. This is a powerful form of Visual Q&A based on a combination of visual features extracted from a pre-trained VGG16 model together with word clustering (embedding). These two sets of heterogeneous features are then combined into a single network where the last layers are made up of an alternating sequence of Dense and Dropout. This recipe works on Keras 2.0+.
Therefore, this recipe will teach you how to:
- Extract features from a pre-trained VGG16 network.
- Use pre-built word embeddings for mapping words into a space where similar words are adjacent.
- Use LSTM layers for building a language model. LSTM will be discussed in Chapter 6 and for now we will use them as black boxes.
- Combine different heterogeneous input features to create a combined feature space. For this task, we will use the new Keras 2.0 functional API.
- Attach a few additional Dense and Dropout layers for creating a multi-layer perceptron and increasing the power of our deep learning network.
For the sake of simplicity we will not re-train the combined network in 5 but, instead, will use a pre-trained set of weights already available online (https://avisingh599.github.io/deeplearning/visual-qa/) . The interested reader can re-train the network on his own train dataset made up of N images, N questions, and N answers. This is left as an optional exercise. The network is inspired by the paper VQA: Visual Question Answering, Aishwarya Agrawal, Jiasen Lu, Stanislaw Antol, Margaret Mitchell, C. Lawrence Zitnick, Dhruv Batra, Devi Parikh, 2015. (http://arxiv.org/pdf/1505.00468v4.pdf) :
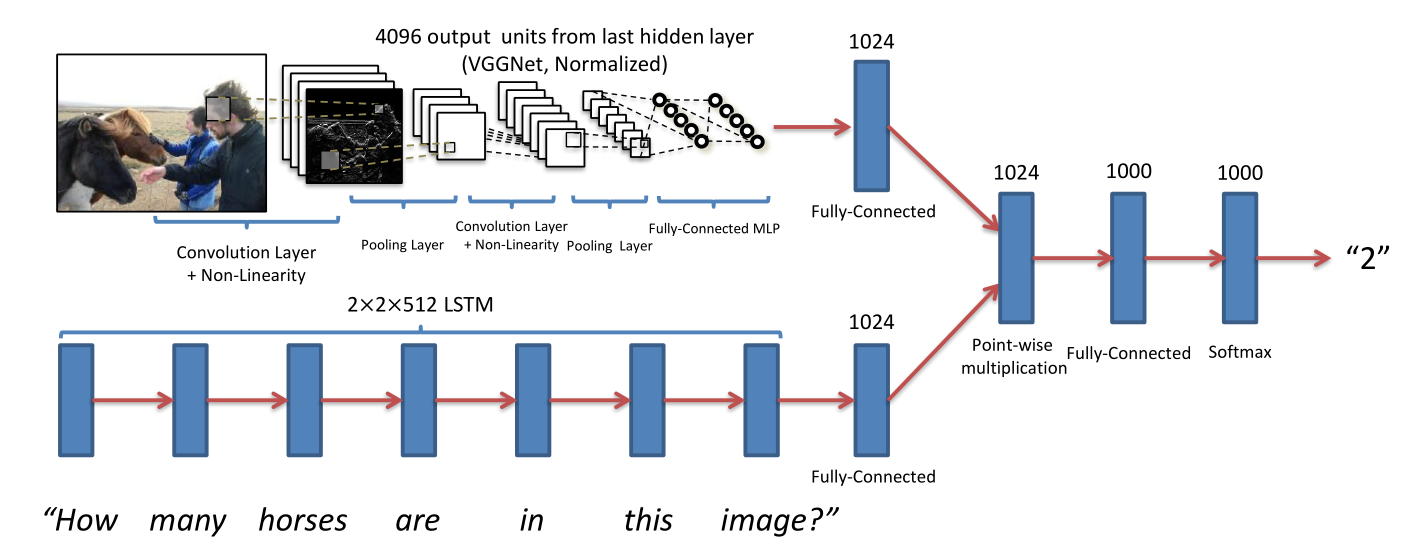
The only difference in our case is that we will concatenate the features produced by the image layer with the features produced by the language layer.