
- We import the necessary modules. We are using the sys module's stdout.flush() to help us force Python to flush the data in the standard output (computer monitor in our case). The random module is used to derive random samples from the experience replay buffer (the buffer where we store the past experience). The datetime module is used to keep track of the time spent in training:
import gym
import sys
import random
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
from datetime import datetime
from scipy.misc import imresize
- We define the hyperparameters for the training; you can experiment by changing them. These parameters define the minimum and maximum size of the experience replay buffer and the number of episodes after which the target network is updated:
MAX_EXPERIENCES = 500000
MIN_EXPERIENCES = 50000
TARGET_UPDATE_PERIOD = 10000
IM_SIZE = 80
K = 4
- The class DQN is defined; its constructor builds the CNN network using the tf.contrib.layers.conv2d function and defines the cost and training ops:
class DQN:
def __init__(self, K, scope, save_path= 'models/atari.ckpt'):
self.K = K
self.scope = scope
self.save_path = save_path
with tf.variable_scope(scope):
# inputs and targets
self.X = tf.placeholder(tf.float32, shape=(None, 4, IM_SIZE, IM_SIZE), name='X')
# tensorflow convolution needs the order to be:
# (num_samples, height, width, "color")
# so we need to tranpose later
self.G = tf.placeholder(tf.float32, shape=(None,), name='G')
self.actions = tf.placeholder(tf.int32, shape=(None,), name='actions')
# calculate output and cost
# convolutional layers
Z = self.X / 255.0
Z = tf.transpose(Z, [0, 2, 3, 1])
cnn1 = tf.contrib.layers.conv2d(Z, 32, 8, 4, activation_fn=tf.nn.relu)
cnn2 = tf.contrib.layers.conv2d(cnn1, 64, 4, 2, activation_fn=tf.nn.relu)
cnn3 = tf.contrib.layers.conv2d(cnn2, 64, 3, 1, activation_fn=tf.nn.relu)
# fully connected layers
fc0 = tf.contrib.layers.flatten(cnn3)
fc1 = tf.contrib.layers.fully_connected(fc0, 512)
# final output layer
self.predict_op = tf.contrib.layers.fully_connected(fc1, K)
selected_action_values = tf.reduce_sum(self.predict_op * tf.one_hot(self.actions, K),
reduction_indices=[1]
)
self.cost = tf.reduce_mean(tf.square(self.G - selected_action_values))
self.train_op = tf.train.RMSPropOptimizer(0.00025, 0.99, 0.0, 1e-6).minimize(self.cost)
- The class has methods to set the session, set_session(), predict the action value function, predict(), update the network, update(), and select an action using Epsilon Greedy algorithm, sample_action():
def set_session(self, session):
self.session = session
def predict(self, states):
return self.session.run(self.predict_op, feed_dict={self.X: states})
def update(self, states, actions, targets):
c, _ = self.session.run(
[self.cost, self.train_op],
feed_dict={
self.X: states,
self.G: targets,
self.actions: actions
}
)
return c
def sample_action(self, x, eps):
"""Implements epsilon greedy algorithm"""
if np.random.random() < eps:
return np.random.choice(self.K)
else:
return np.argmax(self.predict([x])[0])
- We also define methods to load and save the network as the training can take time:
def load(self):
self.saver = tf.train.Saver(tf.global_variables())
load_was_success = True
try:
save_dir = '/'.join(self.save_path.split('/')[:-1])
ckpt = tf.train.get_checkpoint_state(save_dir)
load_path = ckpt.model_checkpoint_path
self.saver.restore(self.session, load_path)
except:
print("no saved model to load. starting new session")
load_was_success = False
else:
print("loaded model: {}".format(load_path))
saver = tf.train.Saver(tf.global_variables())
episode_number = int(load_path.split('-')[-1])
def save(self, n):
self.saver.save(self.session, self.save_path, global_step=n)
print("SAVED MODEL #{}".format(n))
- The method to copy the parameters of the main DQN network to the target network is as follows:
def copy_from(self, other):
mine = [t for t in tf.trainable_variables() if t.name.startswith(self.scope)]
mine = sorted(mine, key=lambda v: v.name)
others = [t for t in tf.trainable_variables() if t.name.startswith(other.scope)]
others = sorted(others, key=lambda v: v.name)
ops = []
for p, q in zip(mine, others):
actual = self.session.run(q)
op = p.assign(actual)
ops.append(op)
self.session.run(ops)
- We define a function learn(), which predicts the value function and updates the original DQN network:
def learn(model, target_model, experience_replay_buffer, gamma, batch_size):
# Sample experiences
samples = random.sample(experience_replay_buffer, batch_size)
states, actions, rewards, next_states, dones = map(np.array, zip(*samples))
# Calculate targets
next_Qs = target_model.predict(next_states)
next_Q = np.amax(next_Qs, axis=1)
targets = rewards + np.invert(dones).astype(np.float32) * gamma * next_Q
# Update model
loss = model.update(states, actions, targets)
return loss
- Now that we have all the ingredients defined in the main code, we use them to build and train a DQN network to play the game of Atari. The code is well commented and is an extension of the previous Q learning code with an addition of the Experience Replay buffer, so you should not have trouble understanding it:
if __name__ == '__main__':
# hyperparameters
gamma = 0.99
batch_sz = 32
num_episodes = 500
total_t = 0
experience_replay_buffer = []
episode_rewards = np.zeros(num_episodes)
last_100_avgs = []
# epsilon for Epsilon Greedy Algorithm
epsilon = 1.0
epsilon_min = 0.1
epsilon_change = (epsilon - epsilon_min) / 500000
# Create Atari Environment
env = gym.envs.make("Breakout-v0")
# Create original and target Networks
model = DQN(K=K, gamma=gamma, scope="model")
target_model = DQN(K=K, gamma=gamma, scope="target_model")
with tf.Session() as sess:
model.set_session(sess)
target_model.set_session(sess)
sess.run(tf.global_variables_initializer())
model.load()
print("Filling experience replay buffer...")
obs = env.reset()
obs_small = preprocess(obs)
state = np.stack([obs_small] * 4, axis=0)
# Fill experience replay buffer
for i in range(MIN_EXPERIENCES):
action = np.random.randint(0,K)
obs, reward, done, _ = env.step(action)
next_state = update_state(state, obs)
experience_replay_buffer.append((state, action, reward, next_state, done))
if done:
obs = env.reset()
obs_small = preprocess(obs)
state = np.stack([obs_small] * 4, axis=0)
else:
state = next_state
# Play a number of episodes and learn
for i in range(num_episodes):
t0 = datetime.now()
# Reset the environment
obs = env.reset()
obs_small = preprocess(obs)
state = np.stack([obs_small] * 4, axis=0)
assert (state.shape == (4, 80, 80))
loss = None
total_time_training = 0
num_steps_in_episode = 0
episode_reward = 0
done = False
while not done:
# Update target network
if total_t % TARGET_UPDATE_PERIOD == 0:
target_model.copy_from(model)
print("Copied model parameters to target network. total_t = %s, period = %s" % (
total_t, TARGET_UPDATE_PERIOD))
# Take action
action = model.sample_action(state, epsilon)
obs, reward, done, _ = env.step(action)
obs_small = preprocess(obs)
next_state = np.append(state[1:], np.expand_dims(obs_small, 0), axis=0)
episode_reward += reward
# Remove oldest experience if replay buffer is full
if len(experience_replay_buffer) == MAX_EXPERIENCES:
experience_replay_buffer.pop(0)
# Save the recent experience
experience_replay_buffer.append((state, action, reward, next_state, done))
# Train the model and keep measure of time
t0_2 = datetime.now()
loss = learn(model, target_model, experience_replay_buffer, gamma, batch_sz)
dt = datetime.now() - t0_2
total_time_training += dt.total_seconds()
num_steps_in_episode += 1
state = next_state
total_t += 1
epsilon = max(epsilon - epsilon_change, epsilon_min)
duration = datetime.now() - t0
episode_rewards[i] = episode_reward
time_per_step = total_time_training / num_steps_in_episode
last_100_avg = episode_rewards[max(0, i - 100):i + 1].mean()
last_100_avgs.append(last_100_avg)
print("Episode:", i,"Duration:", duration, "Num steps:", num_steps_in_episode,
"Reward:", episode_reward, "Training time per step:", "%.3f" % time_per_step,
"Avg Reward (Last 100):", "%.3f" % last_100_avg,"Epsilon:", "%.3f" % epsilon)
if i % 50 == 0:
model.save(i)
sys.stdout.flush()
#Plots
plt.plot(last_100_avgs)
plt.xlabel('episodes')
plt.ylabel('Average Rewards')
plt.show()
env.close()
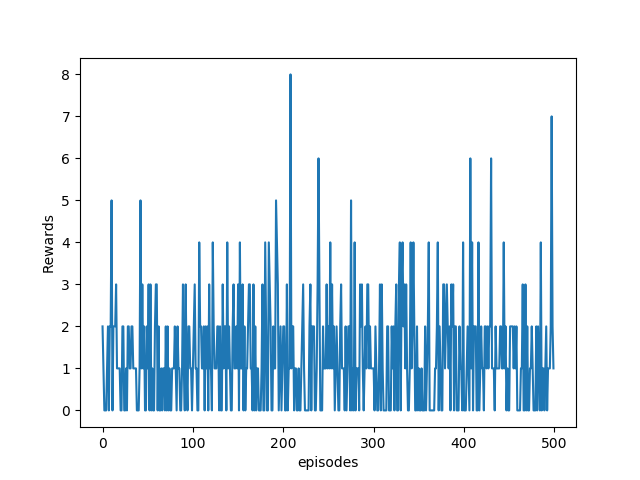
We can see from the preceding figure that the agent is reaching higher rewards with training, and the situation is clearer with the plot of average reward per 100 episodes:
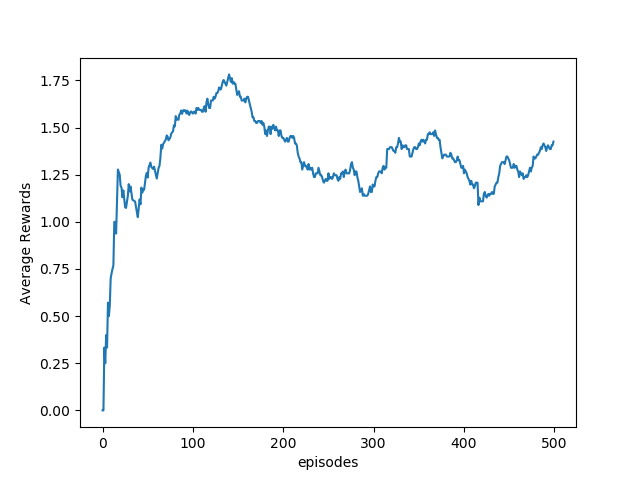
This is only after the first 500 episodes of training; for better results, you will need to train it much longer, ~10,000 episodes.