- The code for this recipe is based on the Andrej Karpathy blog (http://karpathy.github.io/2016/05/31/rl/) and a part of it has been adapted from code by Sam Greydanus (https://gist.github.com/karpathy/a4166c7fe253700972fcbc77e4ea32c5).
- We have the usual imports:
import numpy as np
import gym
import matplotlib.pyplot as plt
import tensorflow as tf
- We define our PolicyNetwork class. During the class construction, the model hyperparameters are also initialized. The __init__ method defines the placeholders for input state, self.tf_x; predicted action, self.tf.y; corresponding reward, self.tf_epr; network weights; and ops to predict action value, training, and updating. You can see that the class construction also initiates an interactive TensorFlow session:
class PolicyNetwork(object):
def __init__(self, N_SIZE, h=200, gamma=0.99, eta=1e-3, decay=0.99, save_path = 'models2/pong.ckpt' ):
self.gamma = gamma
self.save_path = save_path
# Placeholders for passing state....
self.tf_x = tf.placeholder(dtype=tf.float32, shape=[None, N_SIZE * N_SIZE], name="tf_x")
self.tf_y = tf.placeholder(dtype=tf.float32, shape=[None, n_actions], name="tf_y")
self.tf_epr = tf.placeholder(dtype=tf.float32, shape=[None, 1], name="tf_epr")
# Weights
xavier_l1 = tf.truncated_normal_initializer(mean=0, stddev=1. / N_SIZE, dtype=tf.float32)
self.W1 = tf.get_variable("W1", [N_SIZE * N_SIZE, h], initializer=xavier_l1)
xavier_l2 = tf.truncated_normal_initializer(mean=0, stddev=1. / np.sqrt(h), dtype=tf.float32)
self.W2 = tf.get_variable("W2", [h, n_actions], initializer=xavier_l2)
# Build Computation
# tf reward processing (need tf_discounted_epr for policy gradient wizardry)
tf_discounted_epr = self.tf_discount_rewards(self.tf_epr)
tf_mean, tf_variance = tf.nn.moments(tf_discounted_epr, [0], shift=None, name="reward_moments")
tf_discounted_epr -= tf_mean
tf_discounted_epr /= tf.sqrt(tf_variance + 1e-6)
# Define Optimizer, compute and apply gradients
self.tf_aprob = self.tf_policy_forward(self.tf_x)
loss = tf.nn.l2_loss(self.tf_y - self.tf_aprob)
optimizer = tf.train.RMSPropOptimizer(eta, decay=decay)
tf_grads = optimizer.compute_gradients(loss, var_list=tf.trainable_variables(), grad_loss=tf_discounted_epr)
self.train_op = optimizer.apply_gradients(tf_grads)
# Initialize Variables
init = tf.global_variables_initializer()
self.session = tf.InteractiveSession()
self.session.run(init)
self.load()
- We define a method to calculate the discounted rewards. This ensures that the agent takes into account not only the present reward, but also future rewards. The discounted reward at any time t is given by Rt = ∑γkrt+k, where the summation is over k ∈ [0,∞], and γ is the discount factor with value lying between 0 and 1. In our code, we have used gamma = 0.99:
def tf_discount_rewards(self, tf_r): # tf_r ~ [game_steps,1]
discount_f = lambda a, v: a * self.gamma + v;
tf_r_reverse = tf.scan(discount_f, tf.reverse(tf_r, [0]))
tf_discounted_r = tf.reverse(tf_r_reverse, [0])
return tf_discounted_r
- We define a tf_policy_forward method to provide the probability of moving the paddle UP, given an input observation state. We implement it using a two-layer NN. The network takes the processed image of the state of the game and generates a single number denoting the probability of moving the paddle UP. In TensorFlow, as the network graph is computed only in the TensorFlow session, we therefore define another method, predict_UP, to compute the probability:
def tf_policy_forward(self, x): #x ~ [1,D]
h = tf.matmul(x, self.W1)
h = tf.nn.relu(h)
logp = tf.matmul(h, self.W2)
p = tf.nn.softmax(logp)
return p
def predict_UP(self,x):
feed = {self.tf_x: np.reshape(x, (1, -1))}
aprob = self.session.run(self.tf_aprob, feed);
return aprob
- The PolicyNetwork agent updates the weights using the update method:
def update(self, feed):
return self.session.run(self.train_op, feed)
- We define a helper function to preprocess the observation state space:
# downsampling
def preprocess(I):
""" prepro 210x160x3 uint8 frame into 6400 (80x80) 1D float vector """
I = I[35:195] # crop
I = I[::2,::2,0] # downsample by factor of 2
I[I == 144] = 0 # erase background (background type 1)
I[I == 109] = 0 # erase background (background type 2)
I[I != 0] = 1 # everything else (paddles, ball) just set to 1
return I.astype(np.float).ravel()
- The rest is simple--we create a game environment, define arrays to hold (state, action, reward, state), and make the agent learn for a very large number of episodes (with a break or continuously, depending solely on your computational resources). An important thing to note here is that the agent is not learning per action step. Instead, the agent uses the complete set of (state, action, reward, state) of one episode to correct its policy. This can be memory-expensive:
if __name__ == '__main__':
# Create Game Environment
env_name = "Pong-v0"
env = gym.make(env_name)
env = wrappers.Monitor(env, '/tmp/pong', force=True)
n_actions = env.action_space.n # Number of possible actions
# Initializing Game and State(t-1), action, reward, state(t)
xs, rs, ys = [], [], []
obs = env.reset()
prev_x = None
running_reward = None
running_rewards = []
reward_sum = 0
n = 0
done = False
n_size = 80
num_episodes = 500
#Create Agent
agent = PolicyNetwork(n_size)
# training loop
while not done and n< num_episodes:
# Preprocess the observation
cur_x = preprocess(obs)
x = cur_x - prev_x if prev_x is not None else np.zeros(n_size*n_size)
prev_x = cur_x
#Predict the action
aprob = agent.predict_UP(x) ; aprob = aprob[0,:]
action = np.random.choice(n_actions, p=aprob)
#print(action)
label = np.zeros_like(aprob) ; label[action] = 1
# Step the environment and get new measurements
obs, reward, done, info = env.step(action)
env.render()
reward_sum += reward
# record game history
xs.append(x) ; ys.append(label) ; rs.append(reward)
if done:
# update running reward
running_reward = reward_sum if running_reward is None else running_reward * 0.99 + reward_sum * 0.01
running_rewards.append(running_reward)
feed = {agent.tf_x: np.vstack(xs), agent.tf_epr: np.vstack(rs), agent.tf_y: np.vstack(ys)}
agent.update(feed)
# print progress console
if n % 10 == 0:
print ('ep {}: reward: {}, mean reward: {:3f}'.format(n, reward_sum, running_reward))
else:
print (' ep {}: reward: {}'.format(n, reward_sum))
# Start next episode and save model
xs, rs, ys = [], [], []
obs = env.reset()
n += 1 # the Next Episode
reward_sum = 0
if n % 50 == 0:
agent.save()
done = False
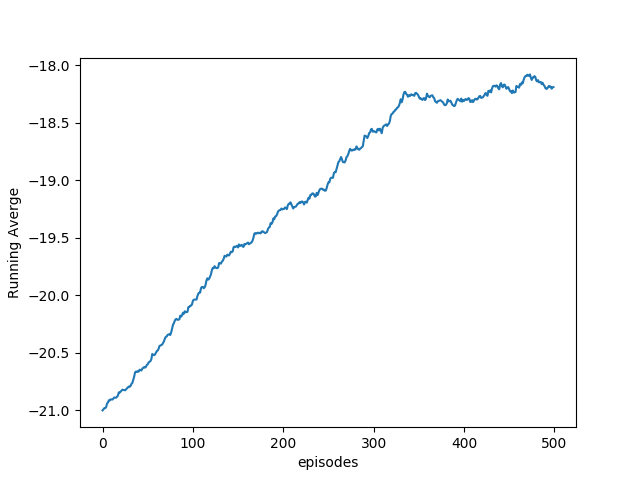
plt.plot(running_rewards)
plt.xlabel('episodes')
plt.ylabel('Running Averge')
plt.show()
env.close()
The following figure shows the average running reward as the agent learns for the first 500 episodes: