
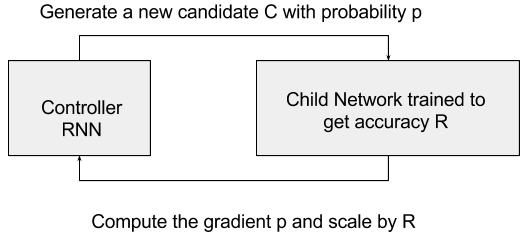
The key idea to tackle this problem is to have a controller network which proposes a child model architecture with probability p, given a particular network given in input. The child is trained and evaluated for the particular task to be solved (say for instance that the child gets accuracy R). This evaluation R is passed back to the controller which, in turn, uses R to improve the next candidate architecture. Given this framework, it is possible to model the feedback from the candidate child to the controller as the task of computing the gradient of p and then scale this gradient by R. The controller can be implemented as a Recurrent Neural Network (see the following figure). In doing so, the controller will tend to privilege iteration after iterations candidate areas of architecture that achieve better R and will tend to assign a lower probability to candidate areas that do not score so well.
For instance, a controller recurrent neural network can sample a convolutional network. The controller can predict many hyper-parameters such as filter height, filter width, stride height, stride width, and the number of filters for one layer and then can repeat. Every prediction can be carried out by a softmax classifier and then fed into the next RNN time step as input. This is well expressed by the following images taken from Neural Architecture Search with Reinforcement Learning, Barret Zoph, Quoc V. Le, https://arxiv.org/abs/1611.01578:

Predicting hyperparameters is not enough as it would be optimal to define a set of actions to create new layers in the network. This is particularly difficult because the reward function describing the new layers is most likely not differentiable and therefore it would not be possible to optimize it with standard techniques such as SGD. The solution comes from reinforcement learning and it consists of adopting a policy gradient network similar to the one described in our Chapter 9, Reinforcement Learning.
Besides that, parallelism can be used for optimizing the parameters of the controller RNN. Quoc Le & Barret Zoph proposed to adopt a parameter-server scheme where we have a parameter server of S shards, that store the shared parameters for K controller replicas. Each controller replica samples m different child architectures that are trained in parallel as illustrated in the following images, taken from Neural Architecture Search with Reinforcement Learning, Barret Zoph, Quoc V. Le, https://arxiv.org/abs/1611.01578:

Quoc and Barret applied AutoML techniques for Neural Architecture Search to the Penn Treebank dataset (https://en.wikipedia.org/wiki/Treebank), a well-known benchmark for language modeling. Their results improve the manually designed networks currently considered the state-of-the-art. In particular, they achieve a test set perplexity of 62.4 on the Penn Treebank, which is 3.6 perplexity better than the previous state-of-the-art model. Similarly, on the CIFAR-10 dataset (https://www.cs.toronto.edu/~kriz/cifar.html), starting from scratch, the method can design a novel network architecture that rivals the best human-invented architecture in terms of test set accuracy. The proposed CIFAR-10 model achieves a test error rate of 3.65, which is 0.09 percent better and 1.05x faster than the previous state-of-the-art model that used a similar architectural scheme.