
In this recipe, we use the results of the previous recipe to translate from a source language into a target language. The idea is very simple: a source sentence is given the two combined RNNs (encoder + decoder) as input . As soon as the sentence concludes, the decoder will emit logit values and we greedily emit the word associated with the maximum value. As an example, the word moi is emitted as the first token from the decoder because this word has the maximum logit value. After that, the word suis is emitted, and so on:
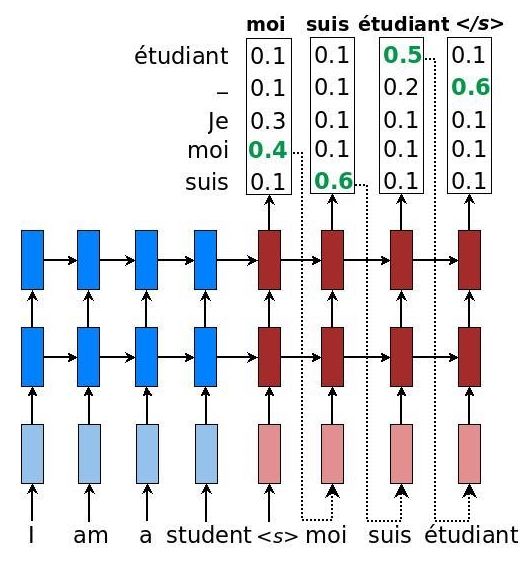
An example of sequence models for NMT with probabilities as seen in https://github.com/lmthang/thesis/blob/master/thesis.pdf
There are multiple strategies for using the output of a decoder:
- Greedy: The word corresponding to the maximum logit is emitted
- Sampling: A word is emitted by sampling the logit emitted by logits
- Beam Search: More than one prediction and therefore a tree of possible expansions is created