
As mentioned in the previous recipe, Q learning to balance CartPole, for Atari games such as Pac-Man or Breakout, we need to preprocess the observation state space, which consists of 33,600 pixels with 3 RGB values. Each of these pixels can take any value between 0 and 255. Our preprocess function should be able to quantize the pixel possible values and, at the same time, reduce the observation state space.
We make use of Scipy's imresize function to downsample the image. The following functions preprocess the image before it is fed to the DQN:
def preprocess(img):
img_temp = img[31:195] # Choose the important area of the image
img_temp = img_temp.mean(axis=2) # Convert to Grayscale#
# Downsample image using nearest neighbour interpolation
img_temp = imresize(img_temp, size=(IM_SIZE, IM_SIZE), interp='nearest')
return img_temp
IM_SIZE is a global parameter--in the code, we take its value to be 80. The function has comments describing each process. Here, you can see the observation space before and after the preprocessing:
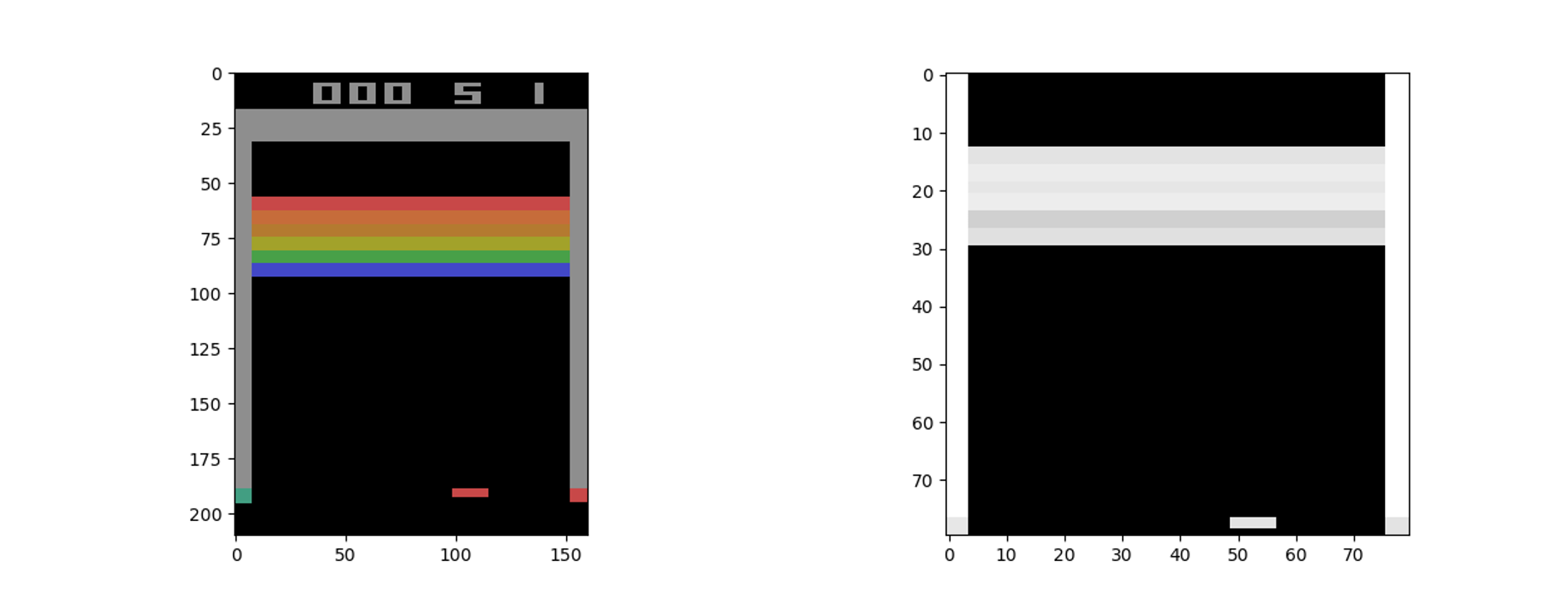
Another important thing to note is that the present observation space does not give a complete picture of the game; for example, seeing the preceding figure, you cannot determine whether the paddle was moving toward left or right. Thus, to completely understand the present state of the game, we need to consider the sequences of actions and observations. In the recipe, we consider four sequences of actions and observations to determine the current situation and train the agent. This is accomplished with the help of the state_update function, which appends the present observation state to the previous state, thus generating a sequence of states:
def update_state(state, obs):
obs_small = preprocess(obs)
return np.append(state[1:], np.expand_dims(obs_small, 0), axis=0)
Lastly, to deal with the stability issues while training, we use the concept of target_network, which is a copy of the DQN but is not updated as often. We use the target network to generate the target value function for the DQN network, while the DQN is updated at each step/episode and the target_network is updated (made the same as DQN) after a regular interval. As all updates take place within the TensorFlow session, we use the name scope to differentiate the target_network and DQN network.