
In this recipe, we present the attention methodology, a state-of-the-art solution for neural network translation. The idea behind attention was introduced in 2015 in the paper, Neural Machine Translation by Jointly Learning to Align and Translate, by Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio (ICLR, 2015, https://arxiv.org/abs/1409.0473) and it consists of adding additional connections between the encoder and the decoder RNNs. Indeed, connecting the decoder only with the latest layer of the encoder imposes an information bottleneck and does not necessarily allow the passing of the information acquired by the previous encoder layers. The solution adopted with attention is illustrated in the following figure:
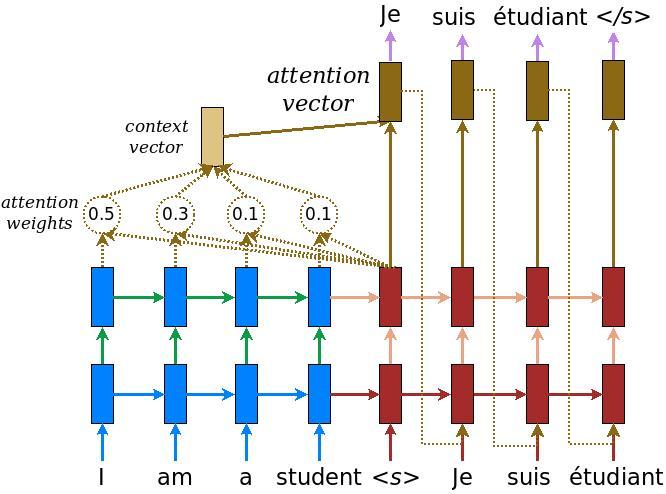
There are three aspects to consider:
- First, the current target hidden state is used together with all previous source states to derive attention weights which are used to pay more or less attention to tokens previously seen in the sequence
- Second, a context vector is created to summarize the results of the attention weights
- Third, the context vector is combined with the current target hidden state to obtain the attention vector