
5.7 Software Performance Optimization
In this section we will look at several techniques for optimizing software performance, including both loop and cache optimizations as well as more generic strategies.
5.7.1 Loop Optimizations
Loops are important targets for optimization because programs with loops tend to spend a lot of time executing those loops. There are three important techniques in optimizing loops: code motion, induction variable elimination, and strength reduction.
Code motion lets us move unnecessary code out of a loop. If a computation’s result does not depend on operations performed in the loop body, then we can safely move it out of the loop. Code motion opportunities can arise because programmers may find some computations clearer and more concise when put in the loop body, even though they are not strictly dependent on the loop iterations. A simple example of code motion is also common. Consider this loop:
for (i = 0; i < N*M; i++) {
z[i] = a[i] + b[i];
}
The code motion opportunity becomes more obvious when we draw the loop’s CDFG as shown in Figure 5.22. The loop bound computation is performed on every iteration during the loop test, even though the result never changes. We can avoid N × M − 1 unnecessary executions of this statement by moving it before the loop, as shown in the figure.
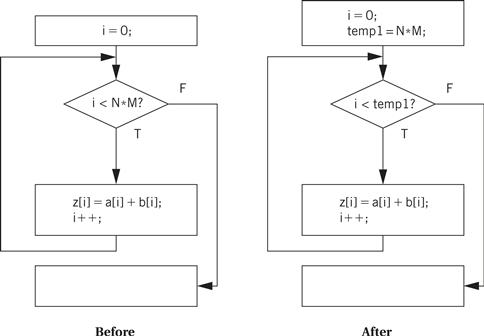
Figure 5.22 Code motion in a loop.
An induction variable is a variable whose value is derived from the loop iteration variable’s value. The compiler often introduces induction variables to help it implement the loop. Properly transformed, we may be able to eliminate some variables and apply strength reduction to others.
A nested loop is a good example of the use of induction variables. Here is a simple nested loop:
for (i = 0; i < N; i++)
for (j = 0; j < M; j++)
z[i][j] = b[i][j];
The compiler uses induction variables to help it address the arrays. Let us rewrite the loop in C using induction variables and pointers. (Later, we use a common induction variable for the two arrays, even though the compiler would probably introduce separate induction variables and then merge them.)
for (i = 0; i < N; i++)
for (j = 0; j < M; j++) {
zbinduct = i*M + j;
*(zptr + zbinduct) = *(bptr + zbinduct);
}
In the above code, zptr and bptr are pointers to the heads of the z and b arrays and zbinduct is the shared induction variable. However, we do not need to compute zbinduct afresh each time. Because we are stepping through the arrays sequentially, we can simply add the update value to the induction variable:
zbinduct = 0;
for (i = 0; i < N; i++) {
for (j = 0; j < M; j++) {
*(zptr + zbinduct) = *(bptr + zbinduct);
zbinduct++;
}
}
This is a form of strength reduction because we have eliminated the multiplication from the induction variable computation.
Strength reduction helps us reduce the cost of a loop iteration. Consider this assignment:
y = x * 2;
In integer arithmetic, we can use a left shift rather than a multiplication by 2 (as long as we properly keep track of overflows). If the shift is faster than the multiply, we probably want to perform the substitution. This optimization can often be used with induction variables because loops are often indexed with simple expressions. Strength reduction can often be performed with simple substitution rules because there are relatively few interactions between the possible substitutions.
5.7.2 Cache Optimizations
A loop nest is a set of loops, one inside the other. Loop nests occur when we process arrays. A large body of techniques has been developed for optimizing loop nests. Rewriting a loop nest changes the order in which array elements are accessed. This can expose new parallelism opportunities that can be exploited by later stages of the compiler, and it can also improve cache performance. In this section we concentrate on the analysis of loop nests for cache performance.
The next example looks at two cache-oriented loop nest optimizations.
Programming Example 5.6 Data Realignment and Array Padding
Assume we want to optimize the cache behavior of the following code:
for (j = 0; j < M; j++)
for (i = 0; i < N; i++)
a[j][i] = b[j][i] * c;
Let us also assume that the a and b arrays are sized with M at 265 and N at 4 and a 256-line, four-way set-associative cache with four words per line. Even though this code does not reuse any data elements, cache conflicts can cause serious performance problems because they interfere with spatial reuse at the cache line level.
Assume that the starting location for a[] is 1024 and the starting location for b[] is 4099. Although a[0][0] and b[0][0] do not map to the same word in the cache, they do map to the same block.
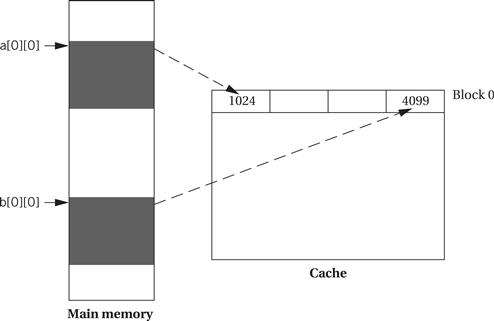
As a result, we see the following scenario in execution:
• The access to a[0][0] brings in the first four words of a[].
• The access to b[0][0] replaces a[0][0] through a[0][3] with b[0][3] and the contents of the three locations before b[].
• When a[0][1] is accessed, the same cache line is again replaced with the first four elements of a[].
Once the a[0][1] access brings that line into the cache, it remains there for the a[0][2] and a[0][3] accesses because the b[] accesses are now on the next line. However, the scenario repeats itself at a[1][0] and every four iterations of the cache.
One way to eliminate the cache conflicts is to move one of the arrays. We do not have to move it far. If we move b’s start to 4100, we eliminate the cache conflicts.
However, that fix won’t work in more complex situations. Moving one array may only introduce cache conflicts with another array. In such cases, we can use another technique called padding. If we extend each of the rows of the arrays to have four elements rather than three, with the padding word placed at the beginning of the row, we eliminate the cache conflicts. In this case, b[0][0] is located at 4100 by the padding. Although padding wastes memory, it substantially improves memory performance. In complex situations with multiple arrays and sophisticated access patterns, we have to use a combination of techniques—relocating arrays and padding them—to be able to minimize cache conflicts.
5.7.3 Performance Optimization Strategies
Let’s look more generally at how to improve program execution time. First, make sure that the code really needs to run faster. Performance analysis and measurement will give you a baseline for the execution time of the program. Knowing the overall execution time tells you how much it needs to be improved. Knowing the execution time of various pieces of the program helps you identify the right locations for changes to the program.
You may be able to redesign your algorithm to improve efficiency. Examining asymptotic performance is often a good guide to efficiency. Doing fewer operations is usually the key to performance. In a few cases, however, brute force may provide a better implementation. A seemingly simple high-level-language statement may in fact hide a very long sequence of operations that slows down the algorithm. Using dynamically allocated memory is one example, because managing the heap takes time but is hidden from the programmer. For example, a sophisticated algorithm that uses dynamic storage may be slower in practice than an algorithm that performs more operations on statically allocated memory.
Finally, you can look at the implementation of the program itself. Here are a few hints on program implementation:
• Try to use registers efficiently. Group accesses to a value together so that the value can be brought into a register and kept there.
• Make use of page mode accesses in the memory system whenever possible. Page mode reads and writes eliminate one step in the memory access. You can increase use of page mode by rearranging your variables so that more can be referenced contiguously.
• Analyze cache behavior to find major cache conflicts. Restructure the code to eliminate as many of these as you can as follows:
• For instruction conflicts, if the offending code segment is small, try to rewrite the segment to make it as small as possible so that it better fits into the cache. Writing in assembly language may be necessary. For conflicts across larger spans of code, try moving the instructions or padding with NOPs.
• For scalar data conflicts, move the data values to different locations to reduce conflicts.
• For array data conflicts, consider either moving the arrays or changing your array access patterns to reduce conflicts.