
3.8 Design Example: Data Compressor
Our design example for this chapter is a data compressor that takes in data with a constant number of bits per data element and puts out a compressed data stream in which the data is encoded in variable-length symbols. Because this chapter concentrates on CPUs, we focus on the data compression routine itself.
3.8.1 Requirements and Algorithm
We use the Huffman coding technique, which is introduced in Application Example 3.4. We require some understanding of how our compression code fits into a larger system. Figure 3.20 shows a collaboration diagram for the data compression process. The data compressor takes in a sequence of input symbols and then produces a stream of output symbols. Assume for simplicity that the input symbols are one byte in length. The output symbols are variable length, so we have to choose a format in which to deliver the output data. Delivering each coded symbol separately is tedious, because we would have to supply the length of each symbol and use external code to pack them into words. On the other hand, bit-by-bit delivery is almost certainly too slow. Therefore, we will rely on the data compressor to pack the coded symbols into an array. There is not a one-to-one relationship between the input and output symbols, and we may have to wait for several input symbols before a packed output word comes out.

Figure 3.20 UML collaboration diagram for the data compressor.
Application Example 3.4 Huffman Coding for Text Compression
Text compression algorithms aim at statistical reductions in the volume of data. One commonly used compression algorithm is Huffman coding [Huf52], which makes use of information on the frequency of characters to assign variable-length codes to characters. If shorter bit sequences are used to identify more frequent characters, then the length of the total sequence will be reduced.
In order to be able to decode the incoming bit string, the code characters must have unique prefixes: No code may be a prefix of a longer code for another character. As a simple example of Huffman coding, assume that these characters have the following probabilities P of appearance in a message:
| Character | P |
| a | 0.45 |
| b | 0.24 |
| c | 0.11 |
| d | 0.08 |
| e | 0.07 |
| f | 0.05 |
We build the code from the bottom up. After sorting the characters by probability, we create a new symbol by adding a bit. We then compute the joint probability of finding either one of those characters and re-sort the table. The result is a tree that we can read top down to find the character codes. Here is the coding tree for our example:

Reading the codes off the tree from the root to the leaves, we obtain the following coding of the characters:
| Character | Code |
| a | 1 |
| b | 01 |
| c | 0000 |
| d | 0001 |
| e | 0010 |
| f | 0011 |
Once the code has been constructed, which in many applications is done off-line, the codes can be stored in a table for encoding. This makes encoding simple, but clearly the encoded bit rate can vary significantly depending on the input character sequence. On the decoding side, because we do not know a priori the length of a character’s bit sequence, the computation time required to decode a character can vary significantly.
The data compressor as discussed above is not a complete system, but we can create at least a partial requirements list for the module as seen below. We used the abbreviation N/A for not applicable to describe some items that don’t make sense for a code module.
| Name | Data compression module |
| Purpose | Code module for Huffman data compression |
| Inputs | Encoding table, uncoded byte-size input symbols |
| Outputs | Packed compressed output symbols |
| Functions | Huffman coding |
| Performance | Requires fast performance |
| Manufacturing cost | N/A |
| Power | N/A |
| Physical size and weight | N/A |
3.8.2 Specification
Let’s refine the description of Figure 3.20 to come up with a more complete specification for our data compression module. That collaboration diagram concentrates on the steady-state behavior of the system. For a fully functional system, we have to provide some additional behavior:
• We have to be able to provide the compressor with a new symbol table.
• We should be able to flush the symbol buffer to cause the system to release all pending symbols that have been partially packed. We may want to do this when we change the symbol table or in the middle of an encoding session to keep a transmitter busy.

Figure 3.21 Definition of the data-compressor class.
A class description for this refined understanding of the requirements on the module is shown in Figure 3.21. The class’s buffer and current-bit behaviors keep track of the state of the encoding, and the table attribute provides the current symbol table. The class has three methods as follows:
• encode performs the basic encoding function. It takes in a one-byte input symbol and returns two values: a boolean showing whether it is returning a full buffer and, if the boolean is true, the full buffer itself.
• new-symbol-table installs a new symbol table into the object and throws away the current contents of the internal buffer.
• flush returns the current state of the buffer, including the number of valid bits in the buffer.
We also need to define classes for the data buffer and the symbol table. These classes are shown in Figure 3.22. The data-buffer will be used to hold both packed symbols and unpacked ones (such as in the symbol table). It defines the buffer itself and the length of the buffer. We have to define a data type because the longest encoded symbol is longer than an input symbol. The longest Huffman code for an eight-bit input symbol is 256 bits. (Ending up with a symbol this long happens only when the symbol probabilities have the proper values.) The insert function packs a new symbol into the upper bits of the buffer; it also puts the remaining bits in a new buffer if the current buffer is overflowed. The Symbol-table class indexes the encoded version of each symbol. The class defines an access behavior for the table; it also defines a load behavior to create a new symbol table. The relationships between these classes are shown in Figure 3.23—a data compressor object includes one buffer and one symbol table.
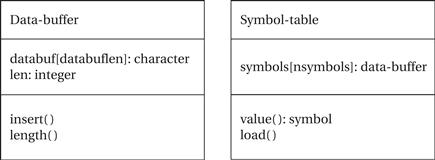
Figure 3.22 Additional class definitions for the data compressor.

Figure 3.23 Relationships between classes in the data compressor.
Figure 3.24 shows a state diagram for the encode behavior. It shows that most of the effort goes into filling the buffers with variable-length symbols. Figure 3.25 shows a state diagram for insert. It shows that we must consider two cases—the new symbol does not fill the current buffer or it does.

Figure 3.24 State diagram for encode behavior.
3.8.3 Program Design
Because we are only building an encoder, the program is fairly simple. We will use this as an opportunity to compare object-oriented and non-OO implementations by coding the design in both C++ and C.
OO design in C++
First is the object-oriented design using C++, because this implementation most closely mirrors the specification.
The first step is to design the data buffer. The data buffer needs to be as long as the longest symbol. We also need to implement a function that lets us merge in another data_buffer, shifting the incoming buffer by the proper amount.
const int databuflen = 8; /* as long in bytes as longest symbol */
const int bitsperbyte = 8; /* definition of byte */
const int bytemask = 0xff; /* use to mask to 8 bits for safety */
const char lowbitsmask[bitsperbyte] = { 0, 1, 3, 7, 15, 31, 63, 127}; /* used to keep low bits in a byte */
typedef char boolean; /* for clarity */
#define TRUE 1
#define FALSE 0
class data_buffer {
char databuf[databuflen] ;
int len;
int length_in_chars() { return len/bitsperbyte; } /* length inbytes rounded down--used in implementation */
public:
void insert(data_buffer, data_buffer&);
int length() { return len; } /* returns number of bits insymbol */
int length_in_bytes() { return (int)ceil(len/8.0); }
void initialize(); /* initializes the data structure */
void data_buffer::fill(data_buffer, int); /* puts upper bits
of symbol into buffer */
void operator = (data_buffer&); /* assignment operator */
data_buffer() { initialize(); } /* C++ constructor */
~data_buffer() { } /* C++ destructor */
};
data_buffer empty_buffer; /* use this to initialize other data_buffers */
void data_buffer::insert(data_buffer newval, data_buffer& newbuf) {
/* This function puts the lower bits of a symbol (newval)
into an existing buffer without overflowing the buffer. Puts
spillover, if any, into newbuf. */
int i, j, bitstoshift, maxbyte;
/* precalculate number of positions to shift up */
bitstoshift = length() – length_in_bytes()*bitsperbyte;
/* compute how many bytes to transfer--can’t run past end
of this buffer */
maxbyte = newval.length() + length() > databuflen*bitsperbyte ?
databuflen : newval.length_in_chars();
for (i = 0; i < maxbyte; i++) {
/* add lower bits of this newval byte */
databuf[i + length_in_chars()] |= (newval.databuf[i] << bitstoshift) & bytemask;
/* add upper bits of this newval byte */
databuf[i + length_in_chars() + 1] |= (newval.databuf[i] >> (bitsperbyte – bitstoshift)) & lowbitsmask[bitsperbyte – bitstoshift];
}
/* fill up new buffer if necessary */
if (newval.length() + length() > databuflen*bitsperbyte) {
/* precalculate number of positions to shift down */
bitstoshift = length() % bitsperbyte;
for (i = maxbyte, j = 0; i++, j++; i < = newval.length_in_chars()) {
newbuf.databuf[j] = (newval.databuf[i] >> bitstoshift) & bytemask;
newbuf.databuf[j] |= newval.databuf[i + 1] & lowbitsmask[bitstoshift];
}
}
/* update length */
len = len + newval.length() > databuflen*bitsperbyte ? databuflen*bitsperbyte : len + newval.length();
}
data_buffer& data_buffer::operator=(data_buffer& e) {
/* assignment operator for data buffer */
int i;
/* copy the buffer itself */
for (i = 0; i < databuflen; i++)
databuf[i] = e.databuf[i];
/* set length */
len = e.len;
/* return */
return e;
}
void data_buffer::fill(data_buffer newval, int shiftamt) {
/* This function puts the upper bits of a symbol (newval) into
the buffer. */
int i, bitstoshift, maxbyte;
/* precalculate number of positions to shift up */
bitstoshift = length() – length_in_bytes()*bitsperbyte;
/* compute how many bytes to transfer--can’t run past end
of this buffer */
maxbyte = newval.length_in_chars() > databuflen ? databuflen : newval.length_in_chars();
for (i = 0; i < maxbyte; i++) {
/* add lower bits of this newval byte */
databuf[i + length_in_chars()] = newval.databuf[i] << bitstoshift;
/* add upper bits of this newval byte */
databuf[i + length_in_chars() + 1] = newval.databuf[i] >> (bitsperbyte – bitstoshift);
}
}
void data_buffer::initialize() {
/* Initialization code for data_buffer. */
int i;
/* initialize buffer to all zero bits */
for (i = 0; i < databuflen; i++)
databuf[i] = 0;
/* initialize length to zero */
len = 0;
}
The code for data_buffer is relatively complex, and not all of its complexity was reflected in the state diagram of Figure 3.25. That doesn’t mean the specification was bad, but only that it was written at a higher level of abstraction.

Figure 3.25 State diagram for insert behavior.
The symbol table code can be implemented relatively easily:
const int nsymbols = 256;
class symbol_table {
data_buffer symbols[nsymbols];
public:
data_buffer* value(int i) { return &(symbols[i]); }
void load(symbol_table&);
symbol_table() { } /* C++ constructor */
~symbol_table() { } /* C++ destructor */
};
void symbol_table::load(symbol_table& newsyms) {
int i;
for (i = 0; i < nsymbols; i++) {
symbols[i] = newsyms.symbols[i];
}
}
Now let’s create the class definition for data_compressor:
typedef char boolean; /* for clarity */
class data_compressor {
data_buffer buffer;
int current_bit;
symbol_table table;
public:
boolean encode(char, data_buffer&);
void new_symbol_table(symbol_table newtable)
{ table = newtable; current_bit = 0;
buffer = empty_buffer; }
int flush(data_buffer& buf)
{ int temp = current_bit; buf = buffer;
buffer = empty_buffer; current_bit = 0; return temp; }
data_compressor() { } /* C++ constructor */
~data_compressor() { } /* C++ destructor */
};
Now let’s implement the encode() method. The main challenge here is managing the buffer.
boolean data_compressor::encode(char isymbol, data_buffer& fullbuf) {
data_buffer temp;
int overlen;
/* look up the new symbol */
temp = *(table.value(isymbol)); /* the symbol itself */
/* will this symbol overflow the buffer? */
overlen = temp.length() + current_bit – buffer.length(); /*amount of overflow */
if (overlen > 0) { /* we did in fact overflow */
data_buffer nextbuf;
buffer.insert(temp,nextbuf);
/* return the full buffer and keep the next partial buffer */
fullbuf = buffer;
buffer = nextbuf;
return TRUE;
} else { /* no overflow */
data_buffer no_overflow;
buffer.insert(temp,no_overflow); /* won’t use this argument */
if (current_bit == buffer.length()) { /* return current buffer */
fullbuf = buffer;
buffer.initialize(); /* initialize the buffer */
return TRUE;
}
else return FALSE; /* buffer isn’t full yet */
}
}
Non–object-oriented implementation
We may not have the luxury of coding the algorithm in C++. While C is almost universally supported on embedded processors, support for languages that support object orientation such as C++ or Java is not so universal. How would we have to structure C code to provide multiple instantiations of the data compressor? If we want to strictly adhere to the specification, we must be able to run several simultaneous compressors, because in the object-oriented specification we can create as many new data-compressor objects as we want. To be able to run multiple data compressors simultaneously, we cannot rely on any global variables—all of the object state must be replicable. We can do this relatively easily, making the code only a little more cumbersome. We create a structure that holds the data part of the object as follows:
struct data_compressor_struct {
data_buffer buffer;
int current_bit;
sym_table table;
}
typedef struct data_compressor_struct data_compressor,
*data_compressor_ptr; /* data type declaration for convenience */
We would, of course, have to do something similar for the other classes. Depending on how strict we want to be, we may want to define data access functions to get to fields in the various structures we create. C would permit us to get to those struct fields without using the access functions, but using the access functions would give us a little extra freedom to modify the structure definitions later.
We then implement the class methods as C functions, passing in a pointer to the data_compressor object we want to operate on. Appearing below is the beginning of the modified encode method showing how we make explicit all references to the data in the object.
typedef char boolean; /* for clarity */
#define TRUE 1
#define FALSE 0
boolean data_compressor_encode(data_compressor_ptr mycmprs,
char isymbol, data_buffer *fullbuf) {
data_buffer temp;
int len, overlen;
/* look up the new symbol */
temp = mycmprs->table[isymbol].value; /* the symbol itself */
len = mycmprs->table[isymbol].length; /* its value */
…
(For C++ afficionados, the above amounts to making explicit the C++ this pointer.)
If, on the other hand, we didn’t care about the ability to run multiple compressions simultaneously, we can make the functions a little more readable by using global variables for the class variables:
static data_buffer buffer;
static int current_bit;
static sym_table table;
We have used the C static declaration to ensure that these globals are not defined outside the file in which they are defined; this gives us a little added modularity. We would, of course, have to update the specification so that it makes clear that only one compressor object can be running at a time. The functions that implement the methods can then operate directly on the globals as seen below.
boolean data_compressor_encode(char isymbol,
data_buffer& fullbuf){
data_buffer temp;
int len, overlen;
/* look up the new symbol */
temp = table[isymbol].value; /* the symbol itself */
len = table[isymbol].length; /* its value */
…
Notice that this code does not need the structure pointer argument, making it resemble the C++ code a little more closely. However, horrible bugs will ensue if we try to run two different compressions at the same time through this code.
What can we say about the efficiency of this code? Efficiency has many aspects covered in more detail in Chapter 5. For the moment, let’s consider instruction selection, that is, how well the compiler does in choosing the right instructions to implement the operations. Bit manipulations such as we do here often raise concerns about efficiency. But if we have a good compiler and we select the right data types, instruction selection is usually not a problem. If we use data types that don’t require data type transformations, a good compiler can select the right instructions to efficiently implement the required operations.
3.8.4 Testing
How do we test this program module to be sure it works? We consider testing much more thoroughly in Section 5.11. In the meantime, we can use common sense to come up with some testing techniques.
One way to test the code is to run it and look at the output without considering how the code is written. In this case, we can load up a symbol table, run some symbols through it, and see whether we get the correct result. We can get the symbol table from outside sources or by writing a small program to generate it ourselves. We should test several different symbol tables. We can get an idea of how thoroughly we are covering the possibilities by looking at the encoding trees—if we choose several very different looking encoding trees, we are likely to cover more of the functionality of the module. We also want to test enough symbols for each symbol table. One way to help automate testing is to write a Huffman decoder. As illustrated in Figure 3.26, we can run a set of symbols through the encoder, and then through the decoder, and simply make sure that the input and output are the same. If they are not, we have to check both the encoder and decoder to locate the problem, but because most practical systems will require both in any case, this is a minor concern.
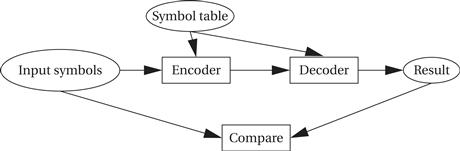
Figure 3.26 A test of the encoder.
Another way to test the code is to examine the code itself and try to identify potential problem areas. When we read the code, we should look for places where data operations take place to see that they are performed properly. We also want to look at the conditionals to identify different cases that need to be exercised. Here are some of the issues that we need to consider in testing:
• Is it possible to run past the end of the symbol table?
• What happens when the next symbol does not fill up the buffer?
• What happens when the next symbol exactly fills up the buffer?
• What happens when the next symbol overflows the buffer?
• Do very long encoded symbols work properly? How about very short ones?
Testing the internals of code often requires building scaffolding code. For example, we may want to test the insert method separately, which would require building a program that calls the method with the proper values. If our programming language comes with an interpreter, building such scaffolding is easier because we don’t have to create a complete executable, but we often want to automate such tests even with interpreters because we will usually execute them several times.