
6.9 Example Real-Time Operating Systems
In this section we look at two example real-time operating systems. First, we look at the POSIX standard for Unix-style operating systems such as Linux. We then introduce Windows CE.
6.9.1 POSIX
POSIX is a version of the Unix operating system created by a standards organization. POSIX-compliant operating systems are source-code compatible—an application can be compiled and run without modification on a new POSIX platform assuming that the application uses only POSIX-standard functions. While Unix was not originally designed as a real-time operating system, POSIX has been extended to support real-time requirements. Many RTOSs are POSIX-compliant and it serves as a good model for basic RTOS techniques. The POSIX standard has many options; particular implementations do not have to support all options. The existence of features is determined by C preprocessor variables; for example, the FOO option would be available if the _POSIX_FOO preprocessor variable were defined. All these options are defined in the system include file unistd.h.
Linux
The Linux operating system has become increasing popular as a platform for embedded computing. Linux is a POSIX-compliant operating system that is available as open source. However, Linux was not originally designed for real-time operation [Yag08, Hal11]. Some versions of Linux may exhibit long interrupt latencies, primarily due to large critical sections in the kernel that delay interrupt processing. Two methods have been proposed to improve interrupt latency. A dual-kernel approach uses a specialized kernel, the co-kernel, for real-time processes and the standard kernel for non-real-time processes. All interrupts must go through the co-kernel to ensure that real-time operations are predictable. The other method is a kernel patch that provides priority inheritance to reduce the latency of many kernel operations. These features are enabled using the PREEMPT_RT mode.
Processes in POSIX
Creating a process in POSIX requires somewhat cumbersome code although the underlying principle is elegant. In POSIX, a new process is created by making a copy of an existing process. The copying process creates two different processes both running the same code. The complication comes in ensuring that one process runs the code intended for the new process while the other process continues the work of the old process.
A process makes a copy of itself by calling the fork() function. That function causes the operating system to create a new process (the child process) which is a nearly exact copy of the process that called fork() (the parent process). They both share the same code and the same data values with one exception, the return value of fork(): the parent process is returned the process ID number of the child process, while the child process gets a return value of 0. We can therefore test the return value of fork() to determine which process is the child:
childid = fork();
if (childid== 0) { /* must be the child */
/* do child process here */
}
However, it would be clumsy to have both processes have all the code for both the parent and child processes. POSIX provides the exec facility for overloading the code in a process. We can use that mechanism to overlay the child process with the appropriate code. There are several versions of exec; execv() takes a list of arguments to the process in the form of an array, just as would be accepted by a typical UNIX program from the shell. So here is the process call with an overlay of the child’s code on the child process:
childid = fork();
if (childid== 0) { /* must be the child */
execv(“mychild”,childargs);
perror(“execv”);
exit(1);
}
The execv() function takes as argument the name of the file that holds the child’s code and the array of arguments. It overlays the process with the new code and starts executing it from the main() function. In the absence of an error, execv() should never return. The code that follows the call to perror() and exit(), take care of the case where execv() fails and returns to the parent process. The exit() function is a C function that is used to leave a process; it relies on an underlying POSIX function that is called _exit().
The parent process should use one of the POSIX wait functions before calling exit() for itself. The wait functions not only return the child process’s status, in many implementations of POSIX they make sure that the child’s resources (namely memory) are freed. So we can extend our code as follows:
childid = fork();
if (childid== 0) { /* must be the child */
execv(“mychild”,childargs);
perror(“execl”);
exit(1);
}
else { /* is the parent */
parent_stuff(); /* execute parent functionality */
wait(&cstatus);
exit(0);
}
The parent_stuff() function performs the work of the parent function. The wait() function waits for the child process; the function sets the integer cstatus variable to the return value of the child process.
The POSIX process model
POSIX does not implement lightweight processes. Each POSIX process runs in its own address space and cannot directly access the data or code of other processes.
Real-time scheduling in POSIX
POSIX supports real-time scheduling in the _POSIX_PRIORITY_SCHEDULING resource. Not all processes have to run under the same scheduling policy. The sched_setscheduler() function is used to determine a process’s scheduling policy and other parameters:
#include <sched.h>
int i, my_process_id;
struct sched_param my_sched_params;
…
i = sched_setscheduler(my_process_id,SCHED_FIFO,&sched_params);
This call tells POSIX to use the SCHED_FIFO policy for this process, along with some other scheduling parameters.
POSIX supports rate-monotonic scheduling in the SCHED_FIFO scheduling policy. The name of this policy is unfortunately misleading. It is a strict priority-based scheduling scheme in which a process runs until it is preempted or terminates. The term FIFO simply refers to the fact that, within a priority, processes run in first-come first-served order.
We already saw the sched_setscheduler() function that allows a process to set a scheduling policy. Two other useful functions allow a process to determine the minimum and maximum priority values in the system:
minval = sched_get_priority_min(SCHED_RR);
maxval = sched_get_priority_max(SCHED_RR);
The sched_getparams() function returns the current parameter values for a process and sched_setparams() changes the parameter values:
int i, mypid;
struct sched_param my_param;
mypid = getpid();
i = sched_getparam(mypid,&my_params);
my_params.sched_priority = maxval;
i = sched_setparam(mypid,&my_params);
Whenever a process changes its priority, it is put at the back of the queue for that priority level. A process can also explicitly move itself to the end of its priority queue with a call to the sched_yield() function.
SCHED_RR is a combination of real-time and interactive scheduling techniques: within a priority level, the processes are timesliced. Interactive systems must ensure that all processes get a chance to run, so time is divided into quanta. Processes get the CPU in multiple of quanta. SCHED_RR allows each process to run for a quantum of time, then gives the CPU to the next process to run for its quantum. The length of the quantum can vary with priority level.
The SCHED_OTHER is defined to allow non-real-time processes to intermix with real-time processes. The precise scheduling mechanism used by this policy is not defined. It is used to indicate that the process does not need a real-time scheduling policy.
Remember that different processes in a system can run with different policies, so some processes may run SCHED_FIFO while others run SCHED_RR.
POSIX semaphores
POSIX supports semaphores but it also supports a direct shared memory mechanism.
POSIX supports counting semaphores in the _POSIX_SEMAPHORES option. A counting semaphore allows more than one process access to a resource at a time. If the semaphore allows up to N resources, then it will not block until N processes have simultaneously passed the semaphore; at that point, the blocked process can resume only after one of the processes has given up its semaphore. The simplest way to think about counting semaphores is that they count down to 0—when the semaphore value is 0, the process must wait until another process gives up the semaphore and increments the count.
Because there may be many semaphores in the system, each one is given a name. Names are similar to file names except that they are not arbitrary paths—they should always start with “/” and should have no other “/”. Here is how you create a new semaphore called /sem1, then close it:
int i, oflags;
sem_t *my_semaphore; /* descriptor for the semaphore */
my_semaphore = sem_open(“/sem1”,oflags);
/* do useful work here */
i = sem_close(my_semaphore);
The POSIX names for P and V are sem_wait() and sem_post() respectively. POSIX also provides a sem_trywait() function that tests the semaphore but does not block. Here are examples of their use:
int i;
i = sem_wait(my_semaphore); /* P */
/* do useful work */
i = sem_post(my_semaphore); /* V */
/* sem_trywait tests without blocking */
i = sem_trywait(my_semaphore);
POSIX shared memory is supported under the _POSIX_SHARED_MEMORY_OBJECTS option. The shared memory functions create blocks of memory that can be used by several processes.
The shm_open() function opens a shared memory object:
objdesc = shm_open(“/memobj1”,O_RDWR);
This code creates a shared memory object called /memobj1 with read/write access; the O_RDONLY mode allows reading only. It returns an integer which we can use as a descriptor for the shared memory object. The ftruncate() function allows a process to set the size of the shared memory object:
if (ftruncate(objdesc,1000) < 0) { /* error */ }
Before using the shared memory object, we must map it into the process memory space using the mmap() function. POSIX assumes that shared memory objects fundamentally reside in a backing store such as a disk and are then mapped into the address space of the process. The value returned by shm_open(), objdesc, is the origin of the shared memory in the backing store. mmap allows the process to map in a subset of that space starting at the offset. The length of the mapped space is len. The start of the block in the process’s memory space is addr. mmap() also requires you to set the protection mode for the mapped memory (O_RDWR, etc.). Here is a sample call to mmap():
if (mmap(addr,len,O_RDWR,MAP_SHARED,objdesc,0) == NULL) {
/* error*/
}
The MAPS_SHARED parameter tells mmap to propagate all writes to all processes that share this memory block. You use the munmap() function to unmap the memory when the process is done with it:
if (munmap(startadrs,len) < 0) { /* error */ }
This function unmaps shared memory from startadrs to startadrs+len. Finally, the close() function is used to dispose of the shared memory block:
close(objdesc);
Only one process calls shm_open() to create the shared memory object and close() to destroy it; every process (including the one that created the object) must use mmap() and mummap() to map it into their address space.
POSIX pipes
The pipe is very familiar to Unix users from its shell syntax:
% foo file1 | baz > file2
In this command, the output of foo is sent directly to the baz program’s standard input by the operating system. The vertical bar (|) is the shell’s notation for a pipe; programs use the pipe() function to create pipes.
A parent process uses the pipe() function to create a pipe to talk to a child. It must do so before the child itself is created or it won’t have any way to pass a pointer to the pipe to the child. Each end of a pipe appears to the programs as a file—the process at the head of the pipe writes to one file descriptor while the tail process reads from another file descriptor. The pipe() function returns an array of file descriptors, the first for the write end and the second for the read end.
Here is an example:
if (pipe(pipe_ends) < 0) { /* create the pipe, check for errors */
perror(“pipe”);
break;
}
/* create the process */
childid = fork();
if (childid== 0) { /* the child reads from pipe_ends[1]*/
childargs[0] = pipe_ends[1];
/* pass the read end descriptor to the new incarnation of child */
execv(“mychild”,childargs);
perror(“execv”);
exit(1);
}
else { /* the parent writes to pipe_ends[0] */
…
}
POSIX message queues
POSIX also supports message queues under the _POSIX_MESSAGE_PASSING facility. The advantage of a queue over a pipe is that, because queues have names, we don’t have to create the pipe descriptor before creating the other process using it, as with pipes.
The name of a queue follows the same rules as for semaphores and shared memory: it starts with a “/” and contains no other “/” characters. In this code, the O_CREAT flag to mq_open() causes it to create the named queue if it doesn’t yet exist and just opens the queue for the process if it does already exist:
struct mq_attr mq_attr; /* attributes of the queue */
mqd_t myq; /* the queue descriptor */
mq_attr.mq_maxmsg = 50; /* maximum number of messages */
mq_attr.mq_msgsize = 64; /* maximum size of a message */
mq_attr.mq_flags = 0; /* flags */
myq = mq_open(“/q1”,O_CREAT | RDWR,S_IRWXU,&mq_attr);
We use the queue descriptor myq to enqueue and dequeue messages:
char data[MAXLEN], rcvbuf[MAXLEN];
if (mq_send(myq,data,len,priority) < 0) { /* error */ }
nbytes = mq_receive(myq,rcvbuf,MAXLEN,&prio);
Messages can be prioritized, with a priority value between 0 and MQ_PRIO_MAX (there are at least 32 priorities available). Messages are inserted into the queue such that they are after all existing messages of equal or higher priority and before all lower-priority messages.
When a process is done with a queue, it calls mq_close():
i = mq_close(myq);
6.9.2 Windows CE
Windows CE [Bol07, Ken11] supports devices such as smartphones, electronic instruments, etc. Windows CE is designed to run on multiple hardware platforms and instruction set architectures. Some aspects of Windows CE, such as details of the interrupt structure, are determined by the hardware architecture and not by the operating system itself. We will concentrate on Windows CE 6.
WinCE architecture
Figure 6.22 shows a layer diagram for Windows CE. Applications run under the shell and its user interface. The Win32 APIs manage access to the operating system. A variety of services and drivers provide the core functionality. The OEM Adaption Layer (OAL) provides an interface to the hardware in much the same way that a HAL does in other software architecture. The architecture of the OAL is shown in Figure 6.23. The hardware provides certain primitives such as a real-time clock and an external connection. The OAL itself provides services such as a real-time clock, power management, interrupts, and a debugging interface. A Board Support Package (BSP) for a particular hardware platform includes the OAL and drivers.
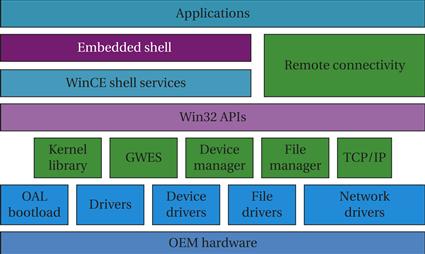
Figure 6.22 Windows CE layer diagram.
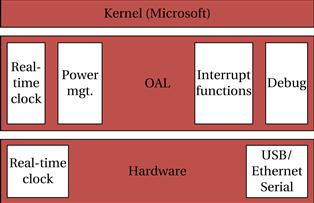
Figure 6.23 OAL architecture in Windows CE.
WinCe memory space
Windows CE provides support for virtual memory with a flat 32-bit virtual address space. A virtual address can be statically mapped into main memory for key kernel-mode code; an address can also be dynamically mapped, which is used for all user-mode and some kernel-mode code. Flash as well as magnetic disk can be used as a backing store.
Figure 6.24 shows the division of the address space into kernel and user with 2 GB for the operating system and 2 GB for the user. Figure 6.25 shows the organization of the user address space. The top 1 GB is reserved for system elements such as DLLs, memory mapped files, and shared system heap. The bottom 1 GB holds user elements such as code, data, stack, and heap.
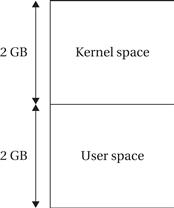
Figure 6.24 Kernel and user address spaces in Windows CE.

Figure 6.25 User address space in Windows CE.
WinCE threads and drivers
WinCE supports two kernel-level units of execution: the thread and the driver. Threads are defined by executable files while drivers are defined by dynamically-linked libraries (DLLs). A process can run multiple threads. All the threads of a process share the same execution environment. Threads in different processes run in different execution environments. Threads are scheduled directly by the operating system. Threads may be launched by a process or a device driver. A driver may be loaded into the operating system or a process. Drivers can create threads to handle interrupts.
WinCE scheduling
Each thread is assigned an integer priority. Lower-valued priorities signify higher priority: 0 is the highest priority and 255 is the lowest possible priority. Priorities 248 through 255 are used for non-real-time threads while the higher priorities are used for various categories of real-time execution. The operating system maintains a queue of ready processes at each priority level. Execution is divided into time quanta. Each thread can have a separate quantum, which can be changed using the API. If the running process does not go into the waiting state by the end of its time quantum, it is suspended and put back into the queue. Execution of a thread can also be blocked by a higher-priority thread.
Tasks may be scheduled using either of two policies: a thread runs until the end of its quantum; or a thread runs until a higher-priority thread is ready to run. Within each priority level, round-robin scheduling is used.
WinCE supports priority inheritance. When priorities become inverted, the kernel temporarily boosts the priority of the lower-priority thread to ensure that it can complete and release its resources. However, the kernel will apply priority inheritance to only one level. If a thread that suffers from priority inversion in turn causes priority inversion for another thread, the kernel will not apply priority inheritance to solve the nested priority inversion.
WinCE interrupts
Interrupt handling is divided among three entities:
• The interrupt service handler (ISH) is a kernel service that provides the first response to the interrupt.
• The ISH selects an interrupt service routine (ISR) to handle the interrupt. The ISH runs in the kernel with interrupts turned off; as a result, it should be designed to do as little direct work as possible.
• The ISR in turn calls an interrupt service thread (IST) which performs most of the work required to handle the interrupt. The IST runs in the OAL and so can be interrupted by a higher-priority interrupt.
Several different scenarios can be used to respond to an interrupt. Figure 6.26 shows one of the responses. The interrupt causes the ISH to vector the interrupt to the appropriate ISR. The ISR in turn determines which IST to use to handle the interrupt and requests the kernel to schedule that thread. The ISH then performs its work and signals the application about the updated device status as appropriate.
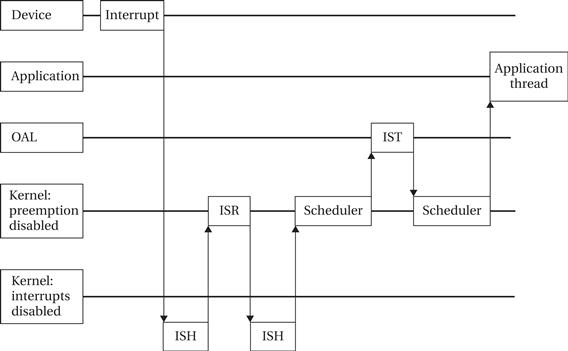
Figure 6.26 Sequence diagram for an interrupt.
Windows CE 6.0 also supports kernel-mode drivers. These drivers run inside the kernel protection layer and so eliminate some of the overhead of user-mode drivers. However, kernel-mode and user-mode drivers use the same API.