
1.9 AMDAHL’S LAW FOR MULTIPROCESSOR SYSTEMS
Assume an algorithm or a task is composed of parallizable fraction f and a serial fraction 1 − f. Assume the time needed to process this task on one single processor is given by
(1.21)
![]()
where the first term on the right-hand side (RHS) is the time the processor needs to process the serial part. The second term on RHS is the time the processor needs to process the parallel part. When this task is executed on N parallel processors, the time taken will be given by
(1.22)
![]()
where the only speedup is because the parallel part now is distributed over N processors. Amdahl’s law for speedup S(N), achieved by using N processors, is given by
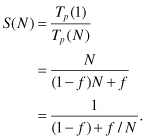
To get any speedup, we must have
This inequality dictates that the parallel portion f must be very close to unity especially when N is large.
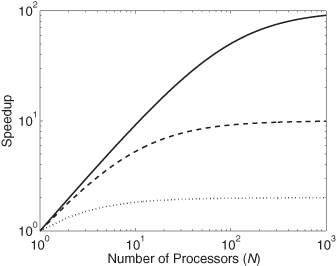
Figure 1.8 shows the speedup versus f for different values of N. The solid line is for f = 0.99; the dashed line is for f = 0.9; and the dotted line is for f = 0.5. We note from the figure that speedup is affected by the value of f. As expected, larger f results in more speedup. However, note that the speedup is most pronounced when f > 0.5. Another observation is that speedup saturates to a given value when N becomes large.
Figure 1.8 Speedup according to Amdahl’s law. The solid line is for f = 0.99; the dashed line is for f = 0.9; and the dotted line is for f = 0.5.
For large values of N, the speedup in Eq. 1.23 is approximated by
(1.25)
![]()
This result indicates that if we are using a system with more than 10 processors, then any speedup advantage is dictated mainly by how clever we are at discovering the parallel parts of the program and how much we are able to execute those parallel parts simultaneously. The figure confirms these expectations.
For extreme values of f, Eq. 1.23 becomes
(1.26)
![]()
(1.27)
![]()
The above equation is obvious. When the program is fully parallel, speedup will be equal to the number of parallel processors we use.
What do we conclude from this? Well, we must know or estimate the value of the fraction f for a given algorithm at the start. Knowing f will give us an idea on what system speedup could be expected on a multiprocessor system. This alone should enable us to judge how much effort to spend trying to improve speedup by mapping the algorithm to a multiprocessor system.