
2.7 INSTRUCTION-LEVEL PARALLELISM (ILP) AND SUPERSCALAR PROCESSORS
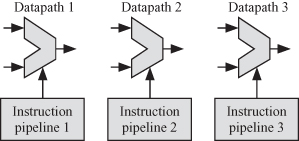
A superscalar processor is able to simultaneously execute several instructions from independent instruction pipelines [18]. Superscalar processors have a dynamic scheduler that examines the instructions in the instruction cache/memory and decides which ones to be issued to each instruction pipeline. Dynamic scheduling allows out-of-order instruction issue and execution. Figure 2.17 shows a general organization of a three-way superscalar processor where the processor contains three instruction pipelines operating on three independent datapath units. A superscalar computer has several instruction pipelines and datapath units that can work in parallel to execute instructions issued to them from the CPU. Using this technique, the instruction execution rate will be greater than the clock rate. For a three-way superscalar architecture with an instruction pipeline, up to three instructions could be executed per clock cycle.
Figure 2.17 General organization of a three-way superscalar processor.
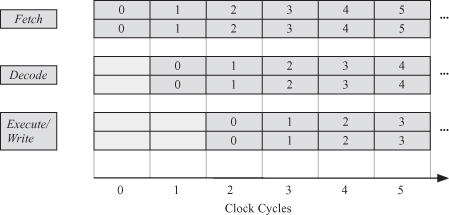
The instruction pipeline for a two-way superscalar processor shown in Fig. 2.18, which is a modification of Fig. 2.14, indicates the fact that we now have two instruction pipelines.
Figure 2.18 Instruction pipelines for a two-way superscalar processor.
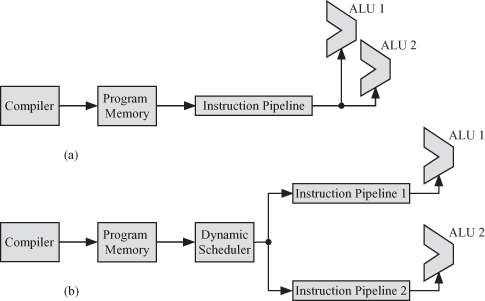
At this point, it is worthwhile to explain the difference between VLIW and superscalar processors. Both techniques rely on the presence of several ALUs to perform several operations in parallel. The main difference lies in how the instructions are issued. Figure 2.19 shows the flow of program instructions starting from the compilation stage all the way to the instruction execution by the parallel ALUs for VLIW and superscalar processors.
Figure 2.19 Comparing program execution on VLIW and superscalar processors. (a) VLIW processor. (b) Superscalar processor.
The key idea in superscalar processors is the ability to execute multiple instructions in parallel. Compilation and hardware techniques are used to maximize the number of instructions that can be used issued in parallel. However, there are limitations to achieving this level of speedup [3, 18, 20, 25]:
- True data dependencies
- Procedural dependencies
- Resource conflicts
- Output dependencies
- Antidependencies
2.7.1 True Data Dependency: Read after Write (RAW)
RAW implies that instruction i should read a new value from a register after another instruction j has performed a write operation.
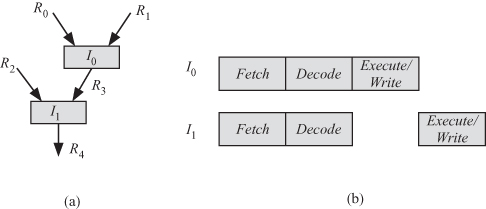
Assume instruction I0 produces some result and instruction I1 uses that result. We say that I1 has true data dependency on I0 and the execution of I1 must be delayed until I0 is finished. We can represent this true data dependency or dependence as shown in Fig. 2.20a. The figure shows that I0 reads its input arguments from registers R0 and R1 and the output result is stored in R2. If I0 is a load from memory instruction, then it might have a large delay or latency. In that case, the execute phase of I1 would have to be delayed by more than one clock cycle.
Figure 2.20 True data dependency between two instructions. (a) Dependence graph. (b) Pipeline processing of the two instructions.
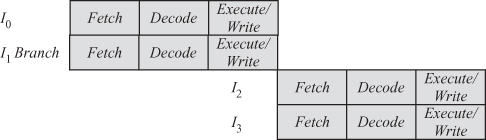
2.7.2 Procedural Dependencies
A major problem with computer instructions is the presence of branch instructions. Figure 2.21 shows the instruction pipeline has two instructions I0 and I1. However, I1 is a branch instruction and it is not possible to determine which instruction to execute until I1 produces its output. Therefore, the fetch phase of the next instruction has to be delayed as shown in Fig. 2.21.
Figure 2.21 Procedural dependency.
2.7.3 Resource Conflicts
A resource conflict arises when two or more instructions require the same processor resource. Examples of shared processor resources are memory, cache, buses, register file, and so on. A resource conflict is resolved when the execution of the competing instructions is delayed. Figure 2.20 can be used to visualize the effect of resource conflict on the instruction pipeline. One should note that, unlike true data dependencies, a resource conflict can be eliminated by duplicating the shared resource. This might be an expensive or impractical solution. For example, eliminating floating-point unit conflicts might involve designing two floating-point units associated with each ALU. This might require a small amount of silicon real estate. Cache conflicts might be eliminated by designing a dual-ported cache or duplicating the cache. Both these options might not be practical though.
2.7.4 Output Dependencies: Write after Write (WAW)
WAW implies that instruction i writes an operand after instruction j has written another operand in the register. The sequence is important since the register should contain the value written by instruction j after both instructions i and j have finished an execution.
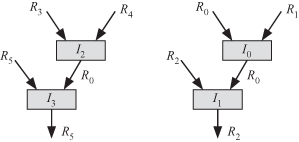
An output dependency occurs when two instructions, I0 and I1, store their output result in the same register. In that case, the register content at a given time depends on which instruction finished last, I0 or I1. We illustrate this using the following register transfer language (RTL) code fragment where op indicates any binary operation [18] requiring two input registers:
I0: R0 ← R0 op R1
I1: R2 ← R0 op R2
I2: R0 ← R3 op R4
I3: R5 ← R0 op R5
Figure 2.22 shows the dependence graph of the instructions. The figure shows two instances of true data dependencies: I1 depends on I0 and I3 depends on I2. Instructions I0 and I2 show output dependency since both instructions store their results in register R0. The sequence of instructions as they are written in the RTL code fragment above indicates that our intention is that I1 uses the content of R0 after instruction I0 is completed. Similarly, instruction I3 uses the content of R0 after I2 is completed. We must ensure that I2 starts its execution phase after I0 has finished its execution phase.
Figure 2.22 Output dependency.
2.7.5 Antidependencies: Write after Read (WAR)
WAR implies that instruction i writes an operand after instruction j has read the contents of the register. Antidependency is illustrated with the help of the RTL code fragment used to explain output dependencies as shown in Fig. 2.22. We note here that instruction I1 uses content of register R0 as an input operand. We must ensure that I1 completes its execution before I2 begins its execution so that the content of R0 is not disturbed while I1 is using it.