
3.11 COMMUNICATION BETWEEN PARALLEL PROCESSORS
We review in this section how parallel processors communicate and what type of communication strategies are available. Parallel processors need to exchange data among themselves in order to complete the tasks assigned to them.
3.11.1 Types of Communication
We can identify the following types of communication modes:
1. One to one (unicast)
2. One to many (multicast)
3. One to all (broadcast)
4. Gather
5. Reduce
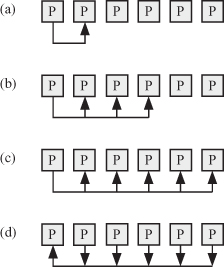
Figure 3.8 shows the different types of modes of communications.
Figure 3.8 The different types or modes of communication among processors: (a) one to one, (b) one to many, (c) broadcast (one to all), and (d) gather and reduce.
One to One (Unicast)
One-to-one operation involves a pair of processors: the sender and the receiver. This mode is sometimes referred to as point-to-point communication. We encounter this type of communication often in SIMD machines where each processor exchanges data with its neighbor. Figure 3.8a shows the one-to-one mode of communication between processors. The figure only shows communication among a pair of processors, but typically, all processors could be performing the one-to-one communication at the same time. This operation is typically performed in each iteration and therefore must be done efficiently. Most of the time, a simple exchange of data between the source and the destination register is used, assuming clock synchronization between the adjacent processors is accomplished. In other cases, two-way (i.e., data–acknowledge) or even four-way handshaking (i.e., request–grant–data–acknowledge) might be required.
One to Many (Multicast)
One-to-many operation involves one sender processor and several receiver processors. Figure 3.8b shows the one-to-many mode of communication between processors. The figure only shows communication of one source processor to multiple receiving processors, but typically, all processors could be performing the one-to-many communication at the same time. The number of receiving processors depends on the details of the algorithm and how the mapping of tasks to processors was accomplished. This operation is typically performed in each iteration and therefore must be done efficiently. Most of the time, a simple exchange of data between the source and the destination register is used assuming clock synchronization between the adjacent processors is accomplished. In other cases, two-way (i.e., data–acknowledge) or even four-way handshaking (i.e., request–grant–data–acknowledge) might be required.
One to All (Broadcast)
Broadcast operation involves sending the same data to all the processors in the system. Figure 3.8c shows the broadcast mode of communication between processors. This mode is useful in supplying data to all processors. It might also imply one processor acting as the sender and the other processors receiving the data. We will see this type of communication in systolic arrays and also in SIMD machines.
Gather
Gather operation involves collecting data from several or all processors of the system. Figure 3.8d shows the gather mode of communication between processors. Assuming we have P processors, the time needed to gather the data could be estimated as
(3.2)
![]()
where τc is the time needed to transmit–receive–process one data item.
Reduce
Reduce operation is similar to gather operation except that some operation is performed on the gathered data. Figure 3.8d shows the reduce mode of communication between processors. An example of the reduce operation is when all data produced by all the processors must be added to produce one final value. This task might take a long time when there are many data to be reduced. Assuming we have P processors producing data to be added, the total time is estimated as
(3.3)
![]()
where τc is the time needed by the processor to process a pair of received data items. It might be worthwhile to perform the reduce operation hierarchically. In that case, the reduce delay time might be
(3.4)
![]()
3.11.2 Message Passing (MP) Communication Mechanism
MP is used mainly in distributed-memory machines. Passing a message between two processes involves using send() and recv() library calls. The programmer uses the send(destination, message) library call to specify the ID of the destination processor or process and the data to be sent. The programmer must also use the recv(source, message type) library call to specify the ID of the source processor or process and the type of data to be received.
In order for two processors to communicate using MP, two operations need to be performed:
1. Establish a communication link between them. Link establishment depends on the nature of the interconnection network. We can think of the link in terms of its physical properties (hardware) or its logical properties (addressing, unidirectional or bidirectional, capacity, message size, etc.)
2. Exchange messages via the send() and recv() library calls.
The MPI is a standard developed to improve the use and portability of MP mechanism.
MP synchronization ensures proper communication between the processors. Synchronization must be treated with care by the programmer since the execution of send() and recv() library calls is under the control of the operating system or systems running the processors. There are two types of synchronization strategies:
- Synchronous or blocking, where the sender halts execution after it executes the send() library call until the message is received. Also, the receiver halts after it executes the recv() library call until the message is available.
- Asynchronous or nonblocking, where the sender continues execution after it executes the send() library call. Also, the receiver continues execution after it executes the recv() library call.
MPI standard supports one-to-one and broadcast modes of communication.