
6.5 COMPUTE UNIFIED DEVICE ARCHITECTURE (CUDA)
CUDA is a software architecture that enables the graphics processing unit (GPU) to be programmed using high-level programming languages such as C and C++. The programmer writes a C program with CUDA extensions, very much like Cilk++ and OpenMP as previously discussed. CUDA requires an NVIDIA GPU like Fermi, GeForce 8XXX/Tesla/Quadro, and so on. Source files must be compiled with the CUDA C compiler NVCC.
A CUDA program uses kernels to operate on the data streams. Examples of data streams are vectors of floating point numbers or a group of frame pixels for video data processing. A kernel is executed in a GPU using parallel threads. CUDA provides three key mechanisms to parallelize programs [71]: thread group hierarchy, shared memories, and barrier synchronization. These mechanisms provide fine-grained parallelism nested within coarse-grained task parallelism.
The following definitions define the terms used in CUDA parlance:
Definition 6.1
The host or central processing unit (CPU) is the computer that interfaces with the user and controls the device used to execute the data-parallel, compute-intensive portion of an application. The host is responsible for executing the serial portion of the application.
Definition 6.2
The GPU is a general-purpose graphics processor unit capable of implementing parallel algorithms.
Definition 6.3
Device is the GPU connected to the host computer to execute the data-parallel, compute-intensive portion of an application. The device is responsible for executing the parallel portion of the application.
Definition 6.4
Kernel is a function callable from the host computer and executed in parallel on the CUDA device by many CUDA threads.
The kernel is executed simultaneously by many (thousands of) threads. An application or library function might consist of one or more kernels [72]. Fermi can run several kernels at a time provided the kernels belong to the same application context [73]. A kernel can be written in C language with additional key words to express parallelism.
The thread and memory hierarchies are shown in Fig. 6.4.
1. A thread at the lowest level of the hierarchy
2. A block composed of several concurrently executing threads
3. A grid composed of several concurrently executing thread blocks
4. Per-thread local memory visible only to a thread
5. Per-block shared memory visible only to threads in a given block
6. Per-device global memory
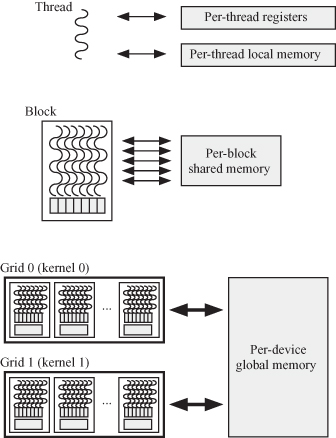
Notice that each thread has its own local memory as well as registers, as shown at the top of the diagram. The registers are on-chip and have small access time. The per-thread local memory and registers are shown by the shaded areas below each thread. The local memory is off-chip and is a bit slower than the registers.
A thread block in the middle of the diagram has its own off-chip shared memory for fast and scalable interthread communication. The shared memory is private to that block.
A grid is a set of thread blocks as shown at the bottom of the figure. A grid has its per-device global memory. This is in addition to the per-block and per-thread shared and local memories, respectively. The device global memory communicates with the host memory and is the means of communicating data between the host and the general-purpose graphics processor unit (GPGPU) device.
6.5.1 Defining Threads, Blocks, and Grids in CUDA
The programmer must specify the number of threads in a block and the number of blocks in the grid. The number of blocks in the grid is specified by the variable gridDim. We can arrange our blocks into one-dimensional array and the number of blocks would be
gridDim.x = k.
For example, if k = 10, then we have 10 blocks in the grid.
We can arrange the threads into a one-dimensional array of m threads per block:
blockDim.x = m.
Each block is given a unique ID called blockIdx that spans the range 0 ≤ blockId < gridDim.
A picture of the thread array in each block and the block array in the grid is shown in Fig. 6.5.
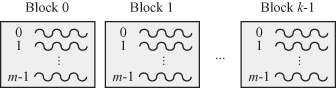
To allocate a thread to the ith vector component, we need to specify which block the thread belongs to and the location of the thread within that block:
i = blockIdx.x × blockDim + threadIdx.x.
The variables gridDim and blockIdx are automatically defined and are of type dim3. The blocks in the grid could be arranged in one, two, or three dimensions. Each dimension is accessed by the constructs blockIdx.x, blockId.y, and blockId.z. The following CUDA command specifies the number of blocks in the x, y, and z dimensions:
dim3 dimGrid(4, 8, 1);
Essentially, the above command defines 32 blocks arranged in a two-dimensional array with four rows and eight columns.
The number of threads in a block is specified by the variable blockDim. Each thread is given a unique ID called threadIdx that spans the range 0 ≤ threadIdx < blockDim. The variables blockDim and threadIdx are automatically defined and are of type dim3. The threads in a block could be arranged in one, two, or three dimensions.
Each dimension is accessed by the constructs threadIdx.x, threadIdx.y, and threadIdx.z. The following CUDA command specifies the number of threads in the x, y, and z dimensions:
dim3 dimBlock(100, 1, 1);
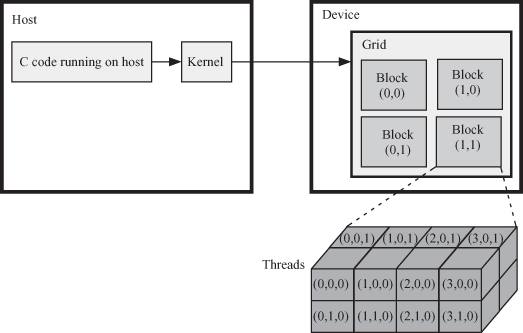
Essentially, the above command defines 100 threads arranged in an array with 100 components. Figure 6.6 shows the organization and relations between the kernel, grid, blocks, and threads. The figure indicates that each kernel is associated with a grid in the device. The choice of thread and block dimensionality is dictated by the nature of the application and the data it is dealing with. The objective is for the programmer to use natural means of simplifying access to data.
6.5.2 Assigning Functions for Execution by a Kernel in CUDA
To define a function that will be executed as a kernel, the programmer modifies the C code for the function prototype by placing the key word _global_ before the function prototype declaration:
1: _global_ void kernel_function_name(function_ argument_list);
2: {
3: ![]()
4: }
Note that the _global_ function qualifier must return void. The programmer now needs to instruct the NVCC to launch the kernel for execution on the device. The programmer modifies the C code specifying the structure of the blocks in the grid and the structure of the threads in a block by placing the declaration ![]() gridDim, blockDim
gridDim, blockDim![]() between the function name and the function argument list as shown in line 7 of the following listing:
between the function name and the function argument list as shown in line 7 of the following listing:
1: int main()
2: {
3: ![]()
4: // Serial portion of code
5: ![]()
6: // Start of parallel portion of code
7: kernel_function_name![]() gridDim, blockDim
gridDim, blockDim ![]() (function_argument_list);
(function_argument_list);
8: // End of parallel portion of code
9: ![]()
10: // Serial portion of code
11: ![]()
12: }
6.5.3 Communication between Host and CUDA Device
The host computer has its own memory hierarchy and the device has its own separate memory hierarchy also. Exchange of data between the host and the device is accomplished by copying data between the host dynamic random access memory (DRAM) and the device global DRAM memory. Similar to C programming, the user must allocate memory on the device global memory for the data in the device and free this memory after the application is finished. The CUDA runtime system calls summarized in Table 6.3 provide the function calls necessary to do these operations.
Table 6.3 Some CUDA Runtime Functions
| Function | Comment |
| cudaThreadSynchronize( ) | Blocks until the device has completed all preceding requested tasks |
| cudaChooseDevice( ) | Returns device matching specified properties |
| cudaGetDevice( ) | Returns which device is currently being used |
| cudaGetDeviceCount( ) | Returns number of devices with compute capability |
| cudaGetDeviceProperties( ) | Returns information about the compute device |
| cudaMaloc( ) | Allocates an object in the device global memory; requires two parameters: address of a pointer to the object and the size of the object |
| cudaFree( ) | Free object from device global memory |
| cudaMemcpy( ) | Copies data from host to device; requires four parameters: destination pointer, source pointer, number of bytes, and transfer type |
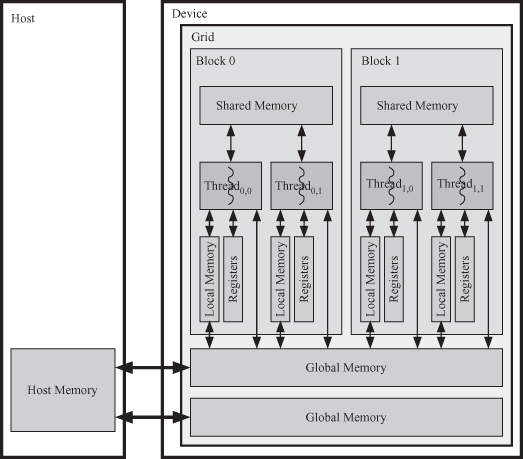
Figure 6.7 shows the memory interface between the device and the host [74, 75]. The global memory at the bottom of the figure is the means of communicating data between the host and the device. The contents of the global memory are visible to all threads, as the figure shows. The per-block shared memory is visible to all threads in the block. Of course, the per-thread local memory is visible only to the associated thread.
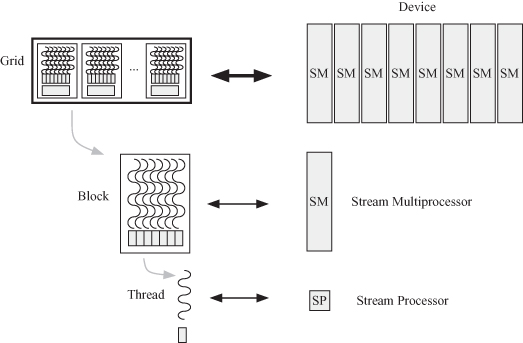
The host launches a kernel function on the device as shown in Fig. 6.8. The kernel is executed on a grid of thread blocks. Several kernels can be processed by the device at any given time. Each thread block is executed on a streaming multiprocessor (SM). The SM executes several thread blocks at a time. Copies of the kernel are executed on the streaming processors (SPs) or thread processors, which execute the threads that evaluate the function. Each thread is allocated to an SM.
Figure 6.8 Execution of a CUDA kernel function on the device using blocks and threads courtesy of NVIDIA Corporation.
6.5.4 Synchronization and Communication for CUDA Threads
When a parallel application is running in the device, synchronization and communication among the threads must be accomplished at different levels. Synchronization and communication can be accomplished at different levels:
1. Kernels and grids
2. Blocks
3. Threads
6.5.5 Kernels and Grids
At any given time, several kernels are executing on the device. The following listing illustrates this point:
1: void main () {
2: ![]()
3: kernel_1![]() nblocks_1, blocksize_1
nblocks_1, blocksize_1![]() (function_ argument_list_1);
(function_ argument_list_1);
4: kernel_2![]() nblocks_2, blocksize_2
nblocks_2, blocksize_2![]() (function_ argument_list_2);
(function_ argument_list_2);
5: ![]()
Kernel_1 will run first on the device and will define a grid that contains dimGrid blocks, and each block will contain dimblock threads. All threads will run the same code specified by the kernel. When kernel_1 is completed, kernel_2 will be forwarded to the device for execution.
Communication between the different grids is indirect through leaving data in the host or device global memory to be used by the next kernel.
6.5.6 Blocks
At any given time, several blocks are executing on the device. All blocks in a grid execute independent of each other. There is no synchronization mechanism between blocks. When a grid is launched, the blocks are assigned to the SM in arbitrary order and the issue order of the blocks is undefined.
Communication among the threads within a block is accomplished through the per-block shared memory. A variable is declared to be shared by threads in the same blocks by preceding the variable declaration with the keyword _shared_. Such variable will be stored in the per-block shared memory. During kernel execution, a private version of this variable is created in the per-thread local memory.
The per-block shared memory is on the same chip as the cores executing the thread communication is relatively fast since the static random access memory (SRAM) is a faster than the off-chip DRAM memories. Each thread has a direct access to its own on-chip registers and its off-chip per-thread local memory. Registers are much faster than the local memory since they are essentially a DRAM. Each thread can also access the per-device global memory. Communication with the off-chip local and global memories suffers from the usual interchip communication penalties (e.g., delay, power, and bandwidth).
6.5.7 Threads
At any given time, a large number of threads are executing on the device. A block that is assigned to an SM is divided into 32-thread warps. Each SM can handle several warps simultaneously, and when some of the warps stall due to memory access, the SM schedules another warp. Threads in a block can be synchronized using the _synchthreads() synchronization barrier. A thread cannot proceed beyond this barrier until all other threads in the block have reached it.
Each thread uses its on-chip per-thread registers and on-chip per-thread local memory. Both of these use SRAM technology, which implies small memory size but fast, low-power communication. Each thread also uses the off-chip global memory, which is slow since it is DRAM based.
6.5.8 CUDA C Language Extensions
A good place to explore the CUDA library is NVIDIA [76]. The following subsections illustrate some of the useful key words with example codes.
Declarations specify where things will live, as shown in Table 6.4.
Table 6.4 Declaration Specifiers
| Declaration | Comment |
| global void function(··· ); | Define kernel function to run on device |
| device int var; | Store variable in device global memory |
| shared int var; | Store variable in per-block shared memory |
| local int var; | Store variable in per-block shared memory |
| constant int const; | Store constant in per-block constant memory |
The CUDA runtime application program interface (API) serves for management of threads, device, and memory. The runtime API also controls the execution of the threads. Some of the runtime functions to control the operation of CUDA were listed in Table 6.3. The CUDA library documentation can be found in NVIDIA [76].