
Bernard Chazelle
Princeton University
Geometric Sampling•Optimal Cuttings
Point Location•Hopcroft’s Problem•Convex Hulls and Voronoi Diagrams•Range Searching
For divide-and-conquer purposes, it is often desirable to organize a set S of n numbers into a sorted list, or perhaps to partition it into two equal-sized groups with no element in one group exceeding any element in the other one. More generally, we might wish to break up S into k groups of size roughly n/k, with again a total ordering among the distinct groups. In the first case we sort; in the second one we compute the median; in the third one we compute quantiles. This is all well known and classical. Is it possible to generalize these ideas to higher dimension? Surprisingly the answer is yes. A geometric construction, known as an ɛ-cutting, provides a space partitioning technique that extends the classical notion of selection to any finite dimension. It is a powerful, versatile data structure with countless applications in computational geometry.
Let H be a set n hyperplanes in Rd. Our goal is to divide up Rd into simplices, none of which is cut by too many of the n hyperplanes. By necessity, of course, some of the simplices need to be unbounded. We choose a parameter ɛ > 0 to specify the coarseness of the subdivision. A set of closed full-dimensional simplices is called an ɛ-cutting for H (Figure 26.1) if:
1.The union of the simplices is Rd, and their interiors are mutually disjoint;
2.The interior of any simplex is intersected by at most ɛn hyperplanes of H.
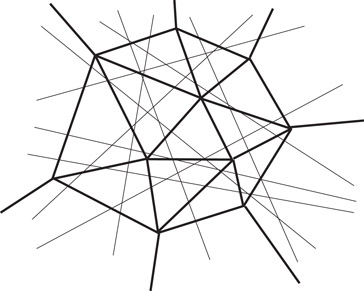
Figure 26.1A two-dimensional cutting.
Historically, the idea of using sparsely intersected simplices for divide and conquer goes back to Clarkson [1] and Haussler and Welzl [2], among others. The definition of an ɛ-cutting given above is essentially due to Matoušek [3]. Efficient but suboptimal constructions were given by Agarwal [4,5] for the two-dimensional case and Matoušek [3,6,7] for arbitrary dimension. The optimal ɛ-cutting construction cited in the theorem below, due to Chazelle [8], is a simplification of an earlier design by Chazelle and Friedman [9].
Theorem 26.1
Given a set H of n hyperplanes in Rd, for any 0 < ɛ < 1, there exists an ɛ-cutting for H of size O(ɛ−d), which is optimal. The cutting, together with the list of hyperplanes intersecting the interior of each simplex, can be found deterministically in O(nɛ1−d) time.
This section explains the main ideas behind the proof of Theorem 26.1. We begin with a quick overview of geometric sampling theory. For a comprehensive treatment of the subject, see References 10 and 11.
A set system is a pair , where X is a set and is a collection of subsets of X. In our applications, X ⊂ Rd and each is of the form X ∩ f(K), where K is a fixed region of Rd and f is any member of a fixed group F of transformations. For example, we might consider n points in the plane, together with the subsets lying inside any triangle congruent to a fixed triangle.
Given Y ⊆ X, we define the set system “induced by Y” to be , with . The VC-dimension (named for Vapnik and Chervonenkis [12]) of Σ is defined as the maximum size of any Y such that . For example, the VC-dimension of the infinite geometric set system formed by points in the plane and halfplanes is 3. The shatter function of the set system is the maximum number of subsets in the set system induced by any Y ⊆ X of size m. If is bounded by cmd, for some constants c, d > 0, then the set system is said to have a shatter function exponent of at most d. It was shown in References 12–14 that, if the shatter function exponent is O(1), then so is the VC-dimension. Conversely, if the VC-dimension is d ≥ 1 then, for any m ≥ d, .
We now introduce two fundamental notions: ɛ-nets and ɛ-approximations. For any 0 < ɛ < 1, a set N ⊆ X is called an ɛ-net for a finite set system if N ∩ R ≠ for any with |R|/|X| > ɛ. A finer (but more costly) sampling mechanism is provided by an ɛ-approximation for , which is a set A ⊆ X such that, given any ,
Some simple structural facts about nets and approximations:
Lemma 26.1
If X1, X2 are disjoint subsets of X of the same size, and A1, A2 are same-size ɛ-approximations for the subsystems induced by X1, X2 (respectively), then A1 ∪ A2 is an ɛ-approximation for the subsystem induced by X1 ∪ X2.
Lemma 26.2
If A is an ɛ-approximation for , then any ɛ′-approximation (resp. -net) for is also an (ɛ + ɛ′)-approximation (resp. -net) for .
In the absence of any restrictive assumption on the set system, it is natural to expect the sample size to depend on both the desired accuracy and the size of the set system itself.
Theorem 26.2
Given a set system , where |X| = n and , for any 1/n ≤ ɛ < 1, it is possible to find, in time O(nm), an ɛ-net for of size O(ɛ−1 log m) and an ɛ-approximation for of size O(ɛ−2 log m).
If we assume bounded VC-dimension, everything changes. In fact the key result in geometric sampling theory is that, for any given level of accuracy, the sample size need not depend on the size of the set system.
In practice, geometric set systems often are “accessible” via an oracle function that takes any Y ⊆ X as input and returns the list of sets in (each set represented explicitly). We assume that the time to do that is O(|Y|d+1), which is linear in the maximum possible size of the oracle’s output, where d is the shatter function exponent. For example, in the case of points and disks in the plane, we have d = 3, and so this assumes that, given n points, we can enumerate all subsets enclosed by a disk in time O(n4). To do this, enumerate all k-tuples of points (k ≤ 3) and, for each tuple, find which points lie inside the smallest disk enclosing the k points. The main result below is stated in terms of the shatter function exponent d, but the same results hold if d denotes the VC-dimension.
Theorem 26.3
Given a set system of shatter function exponent d, for any ɛ ≤ 1/2, an ɛ-approximation for of size O(dɛ−2 log dɛ−1) and an ɛ-net for of size O(dɛ−1 log dɛ−1) can be computed in time O(d)3d(ɛ−2 log dɛ−1)d|X|.
Vapnik and Chervonenkis [12] described a probabilistic construction of ɛ-approximations in bounded VC-dimension. The deterministic construction stated above is due to Chazelle and Matoušek [15], and builds on earlier work [3,6,7,9]. Haussler and Welzl [2] proved the upper bound on the size of ɛ-nets. The running time for computing an ɛ-net was improved to O(d)3d(ɛ−1 log dɛ−1)d|X| by Brönnimann, Chazelle, and Matoušek [16], using the concept of a sensitive ɛ-approximation. Komlós, Pach, and Woeginger [17] showed that, for any fixed d, the bound of O(ɛ−1 log ɛ−1) for ɛ-nets is optimal in the worst case (see also Reference 18). The situation is different with ɛ-approximations: if d > 1 is the VC dimension, then there exists an ɛ-approximation for of size O(ɛ−2+2/(d+1)) [19,20].
An important application of ɛ-approximations is for estimating how many vertices in an arrangement of hyperplanes in Rd lie within a given convex region. Let be the set system formed by a set H of hyperplanes in Rd, where each is the subset of H intersected by an arbitrary line segment. Let σ be a convex body (not necessarily full-dimensional). In the arrangement formed by H within the affine span of σ, let V (H, σ) be the set of vertices that lie inside σ. The following was proven in References 8 and 16.
Theorem 26.4
Given a set H of hyperplanes in Rd in general position, let A be an ɛ-approximation for . Given any convex body σ of dimension k ≤ d,
For convenience of exposition, we may assume that the set H of n hyperplanes in Rd is in general position. Let denote the arrangement formed by H. Obviously, no simplex of an ɛ-cutting can enclose more than O(ɛn)d vertices. Since itself has exactly vertices, we should expect to need at least on the order of ɛ−d simplices. But this is precisely the upper bound claimed in Theorem 26.1, which therefore is asymptotically tight.
Our starting point is an ɛ-net N for H, where the underlying set system is formed by a set X of hyperplanes and the collection of subsets obtained by intersecting X with all possible open d-simplices. Its VC-dimension is bounded, and so by Theorem 26.3 an ɛ-net N of size O(ɛ−1 log ɛ−1) can be found in nɛ−O(1) time.
We need to use a systematic way to triangulate the arrangement formed by the ɛ-net. We build a canonical triangulation of by induction on the dimension d (Figure 26.2). The case d = 1 is trivial, so we assume that d > 1.
1.Rank the vertices of by the lexicographic order of their coordinate sequences.
2.By induction, form a canonical triangulation of the (d − 1)-dimensional arrangement made by each hyperplane with respect to the n − 1 others.
3.For each cell (i.e., full-dimensional face) σ of , lift toward its lowest-ranked vertex v each k-simplex (k = 0,…, d − 2) on the triangulated boundary of σ that does not lie in a (d − 1)-face of that is incident to v.
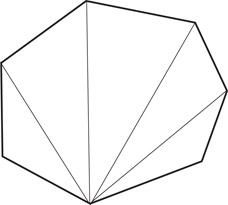
Figure 26.2A canonical triangulation.
It is not hard to see that the combinatorial complexity (i.e., number of all faces of all dimensions) of the canonical triangulation of is asymptotically the same as that of , which is O(ɛ−1 log ɛ−1)d. Therefore, the closures of its cells constitute an ɛ-cutting for H of size O(ɛ−1 log ɛ−1)d, which is good but not perfect. For optimality we must remove the log factor.
Assume that we have at our disposal an optimal method for building an ɛ0-cutting of size , for some suitably small constant ɛ0. To bootstrap this into an optimal ɛ-cutting construction for any ɛ, we might proceed as follows: Beginning with a constant-size cutting, we progressively refine it by producing several generations of finer and finer cuttings, , etc, where is an -cutting for H of size O(ɛ−dk). Specifically, assume that we have recursively computed the cutting for H. For each , we have the incidence list Hσ of the hyperplanes intersecting the interior of σ. To compute the next-generation cutting , consider refining each σ in turn as follows:
1.Construct an ɛ0-cutting for Hσ, using the algorithm whose existence is assumed.
2.Retain only those simplices that intersect σ and clip them outside of σ.
3.In case the clipping produces nonsimplicial cells within σ, retriangulate them “canonically” (Figure 26.3).
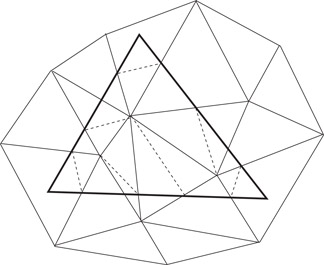
Figure 26.3Clip and retriangulate.
Let denote the collection of new simplices. A simplex of in σ is cut (in its interior) by at most ɛ0|Hσ| hyperplanes of Hσ, and hence of H. By induction, this produces at most cuts; therefore, is an -cutting. The only problem is that might be a little too big. The reason is that excess in size builds up from generation to generation. We circumvent this difficulty by using a global parameter that is independent of the construction; namely, the total number of vertices.
Note that we may assume that , since σ would otherwise already satisfy the requirement of the next generation. We distinguish between full and sparse simplices. Given a set X of hyperplanes and a d-dimensional (closed) simplex σ, let v(X, σ) be the number of vertices of in the interior of σ.
•The simplex is full if v(H, σ) ≥ c0|Hσ|d, where . If so, we compute an ɛ0-net for Hσ, and triangulate the portion of the net’s arrangement within σ to form an ɛ0-cutting of size . Its simplices form the elements of that lie within σ.
•A simplex σ that is not full is sparse. If so, we find a subset of Hσ that satisfies two conditions:
i.The canonically triangulated portion of that lies inside σ consists of a set of at most full-dimensional (closed) simplices.
ii.Each simplex of is intersected in its interior by at most ɛ0|Hσ| hyperplanes of H.
The elements of within σ are precisely the simplices of .
Lemma 26.3
is an -cutting of size .
Next, we explain how to enforce conditions (i) and (ii) for sparse simplices. To be able to distinguish between full and sparse simplices, we use a c0/2-approximation Aσ for Hσ of constant size, which we can build in O(|Hσ|) time (Theorem 26.3). It follows from Theorem 26.4 that
(26.1) |
|---|
therefore, we can estimate v(H, σ) in constant time with an error of at most , which for our purposes here is inconsequential.
How do we go about refining σ and how costly is it? If σ is a full simplex, then by Theorem 26.3, we can compute the required ɛ0-net in O(|Hσ|) time. Within the same amount of time, we can also find the new set of simplices in σ, together with all of their incidence lists.
The refinement of a sparse simplex σ is a little more involved. We begin with a randomized construction, from which we then remove all the randomness. We compute by choosing a random sample from Aσ of size , for some constant c1 large enough (independent of ɛ0). It can be shown that, with probability at least 2/3, the sample forms an (ɛ0/2)-net for Aσ. By Lemma 26.2, is a (c0/2 + ɛ0/2)-net for Hσ; therefore, we ensure that (ii) holds with probability at least 2/3. A slightly more complex analysis shows that (i) also holds with probability at least 2/3; therefore (i,ii) are both true with probability at least 1/3. We derandomize the construction in a trivial manner by trying out all possible samples, which takes constant time; therefore, the running time for refining σ is O(|Hσ|).
Putting everything together, we see that refining any simplex takes time proportional to the total size of the incidence lists produced. By Lemma 26.3, the time needed for building generation k + 1 is . The construction goes on until we reach the first generation such that . This establishes Theorem 26.1.
From the proof above it is not difficult to derive a rough estimate on the constant factor in the O(ɛ−d) bound on the size of an ɛ-cutting. A thorough investigation into the smallest possible constant was undertaken by Har-Peled [21] for the two-dimensional case.
Cuttings have numerous uses in computational geometry. We mention just a handful: point location, Hopcroft’s problem, convex hulls, Voronoi diagrams, and range searching. In many cases, cuttings allow us to derandomize existing probabilistic solutions, that is, to remove any need for random bits and thus produce deterministic algorithms. Many other applications are described in the survey [5].
How do we preprocess n hyperplanes in Rd, so that, given a query point q, we can quickly find the face of the arrangement formed by the hyperplanes that contains the point? For an answer, simply set ɛ = 1/n in Theorem 26.1, and use the nesting structure of , , etc, to locate q in . Note that this can be done in constant time once we know the location in .
Theorem 26.5
Point location among n hyperplanes can be done in O(log n) query time, using O(nd) preprocessing.
Observe that if we only wish to determine whether the point q lies on one of the hyperplanes, it is possible to cut down the storage requirement a little. To do that, we use an ɛ-cutting for ɛ = (log n)/n. The cells associated with the bottom of the hierarchy are each cut by O(log n) hyperplanes, which we can therefore check one by one. This reduces the storage to O(nd/(log n)d−1).
Given n points and n lines in R2, is there any incidence between points and lines? This is Hopcroft’s problem. It is self-dual; therefore dualizing it won’t help. A classical arrangement of n lines due to Erdös has the property that its n highest-degree vertices are each incident to Ω(n1/3) edges. By picking these n lines as input to Hopcroft’s problem and positioning the n points in the near vicinity of these high-degree vertices, we get a sense (not a proof) that to solve the problem should require checking each point against the Ω(n1/3) lines incident to their nearby vertex. This leads to an Ω(n4/3) running time, which under some realistic (though restrictive) conditions, can be made into a rigorous lower bound [22]. At the very least this line of reasoning suggests that to beat Ω(n4/3) is unlikely to be easy. This bound has almost been achieved by an algorithm of Matoušek [23] with, at its heart, a highly intricate and subtle use of cuttings.
Theorem 26.6
To decide whether n points and n lines in the plane are free of any incidence can be done in n4/3 2O(log*n) time.
26.3.3Convex Hulls and Voronoi Diagrams
Cuttings play a key role in computing convex hulls in higher dimension. Given n points in Rd, their convex hull is a bounded convex polytope with O(n⌊d/2⌋) vertices. Of course, it may have much fewer of them: for example, d + 1, if n − d − 1 points lie strictly inside the convex hull of the d + 1 others. It is notoriously difficult to design output-sensitive algorithms, the term designating algorithms whose running time is a function of both input and output sizes. In the “worst case” approach our goal is a simpler one: to design an optimal convex hull algorithm that runs in O(n logn + n⌊d/2⌋) time. (The extra term n log n is unavoidable because sorting is easily embedded as a convex hull problem.)
Computing the convex hull of n points is equivalent by duality to computing the intersection of n halfspaces. A naive approach to this problem is to insert each halfspace one after the other while maintaining the intersection of previously inserted halfspaces incrementally. This can be done without difficulty if we maintain a canonical triangulation of the current intersection polyhedron and update a bipartite graph indicating which hyperplane intersects which cell of the triangulation. A surprising fact, first proven by Clarkson and Shor [24], is that if the halfspaces are inserted in random order, then the expected running time of the algorithm can be made optimal. By using an elaborate mix of ɛ-nets, ɛ-approximations, and ɛ-cuttings, Chazelle [25] showed how to compute the intersection deterministically in optimal time; his algorithm was subsequently simplified by Brönnimann, Chazelle, and Matoušek [16]; a complete description is also given in the book [10]. This implies the two theorems below.
Theorem 26.7
The polyhedron formed by the intersection of n halfspaces in Rd can be computed in O(n log n + n⌊d/2⌋) time.
Not only does this result give us an optimal deterministic solution for convex hulls, but it also solves the Voronoi diagram problem. Indeed, recall [26,27] that a Voronoi diagram of n points in Rd can be “read off” from the facial structure of the convex hull of a lift of the n points into Rd + 1.
Theorem 26.8
The convex hull of a set of n points in Rd can be computed deterministically in O(n log n + n⌊d/2⌋) time. By duality, the Voronoi diagram (or Delaunay triangulation) of a set of n points in Ed can be computed deterministically in O(n log n + n⌈d/2⌉) time.
Simplex range searching refers to the problem of preprocessing a set P of n points in Rd so that, given a query (closed) simplex σ, the size of P ∩ σ can be quickly evaluated. Variants of the problem include reporting the points of P ∩ σ explicitly or, assuming that each point p has a weight w(p) ∈ R, computing . The most powerful data structure for solving simplex range searching, the simplicial partition, vividly illustrates the power of ɛ-cuttings. A collection {(Pi, Ri)} is called a simplicial partition if
•The collection {Pi} forms a partition of P; and
•Each Ri is a relatively open simplex that contains Pi.
The simplices Ri can be of any dimension and, in fact, need not even be disjoint; furthermore the Pi’s need not be equal to P ∩ Ri. A hyperplane is said to cut Ri if it intersects, but does not contain, Ri. The cutting number of the simplicial partition refers to the maximum number of Ri’s that can be cut by a single hyperplane. Matoušek [28] designed an optimal construction, which happens to be crucially based on ɛ-cuttings.
Lemma 26.4
Given a set P of n points in Rd (d > 1), for any integer 1 < r ≤ n/2, there exists a simplicial partition of cutting number O(r1 − 1/d) such that n/r ≤ |Pi| < 2n/r for each (Pi, Ri) in the partition.
To understand the usefulness of simplicial partitions for range searching, one needs to learn about partition trees. A partition tree for P is a tree whose root is associated with the point set P. The set P is partitioned into subsets P1,…, Pm, with each Pi associated with a distinct child vi of the root. To each vi corresponds a convex open set Ri, called the region of vi, that contains Pi. The regions Ri are not necessarily disjoint. If |Pi| > 1, the subtree rooted at vi is defined recursively with respect to Pi.
Armed with a partition tree, it is a simple matter to handle range search queries. In preprocessing, at each node we store the sum of the weights of the points associated with the corresponding region. To answer a query σ, we visit all the children vi of the root and check whether σ intersects the region Ri of vi: (i) if the answer is yes, but σ does not completely enclose the region Ri of vi, then we visit vi and recurse; (ii) if the answer is yes, but σ completely encloses Ri, we add to our current weight count the sum of the weights within Pi, which happens to be stored at vi; (iii) if the answer is no, then we do not recurse at vi.
It is straightforward to see that Lemma 26.4 can be used to construct partition trees. It remains for us to choose the branching factor. If we choose a large enough constant r, we end up with a partition tree that lets us answer simplex range search queries in O(n1 − 1/d + ɛ) time for any fixed ɛ > 0, using only O(n) storage. A more complex argument by Matoušek [28] removes the ɛ term from the exponent.
With superlinear storage, various space-time tradeoffs can be achieved. For example, as shown by Chazelle, Sharir, and Welzl [29], simplex range searching with respect to n points in Rd can be done in O(n1 + ɛ/m1/d) query time, using a data structure of size m, for any n ≤ m ≤ nd. Matoušek [23] slightly improved the query time to O(n( logm/n)d + 1/m1/d), for m/n large enough. These bounds are essentially optimal under highly general computational models [10].
This work was supported in part by NSF grant CCR-998817, and ARO Grant DAAH04-96-1-0181.
1.Clarkson, K.L. New applications of random sampling in computational geometry, Disc. Comput. Geom. 2, 1987, 195–222.
2.Haussler, D., Welzl, E. ɛ-nets and simplex range queries, Disc. Comput. Geom. 2, 1987, 127–151.
3.Matoušek, J. Cutting hyperplane arrangements, Disc. Comput. Geom. 6, 1991, 385–406.
4.Agarwal, P.K. Partitioning arrangements of lines II: Applications, Disc. Comput. Geom. 5, 1990, 533–573.
5.Agarwal, P.K. Geometric partitioning and its applications, in Computational Geometry: Papers from the DIMACS Special Year, eds., Goodman, J.E., Pollack, R., Steiger, W., Amer. Math. Soc., 1991.
6.Matoušek, J. Construction of ɛ-nets, Disc. Comput. Geom. 5, 1990, 427–448.
7.Matoušek, J. Approximations and optimal geometric divide-and-conquer, J. Comput. Syst. Sci. 50, 1995, 203–208.
8.Chazelle, B. Cutting hyperplanes for divide-and-conquer, Disc. Comput. Geom. 9, 1993, 145–158.
9.Chazelle, B., Friedman, J. A deterministic view of random sampling and its use in geometry, Combinatorica 10, 1990, 229–249.
10.Chazelle, B. The Discrepancy Method: Randomness and Complexity, Cambridge University Press, hardcover 2000, paperback 2001.
11.Matoušek, J. Geometric Discrepancy: An Illustrated Guide, Algorithms and Combinatorics, 18, Springer, 1999.
12.Vapnik, V.N., Chervonenkis, A.Ya. On the uniform convergence of relative frequencies of events to their probabilities, Theory of Probability and its Applications 16, 1971, 264–280.
13.Sauer, N. On the density of families of sets, J. Combinatorial Theory A 13, 1972, 145–147.
14.Shelah, S. A combinatorial problem; stability and order for models and theories in infinitary languages, Pac. J. Math. 41, 1972, 247–261.
15.Chazelle, B., Matoušek, J. On linear-time deterministic algorithms for optimization problems in fixed dimension, J. Algorithms 21, 1996, 579–597.
16.Brönnimann, H., Chazelle, B., Matoušek, J. Product range spaces, sensitive sampling, and derandomization, SIAM J. Comput. 28, 1999, 1552–1575.
17.Komlós, J., Pach, J., Woeginger, G. Almost tight bounds for ɛ-nets, Disc. Comput. Geom. 7, 1992, 163–173.
18.Pach, J., Agarwal, P.K. Combinatorial Geometry, Wiley-Interscience Series in Discrete Mathematics and Optimization, John Wiley & Sons, Inc., 1995.
19.Matoušek, J. Tight upper bounds for the discrepancy of halfspaces, Disc. Comput. Geom. 13, 1995, 593–601.
20.Matoušek, J., Welzl, E., Wernisch, L. Discrepancy and ɛ-approximations for bounded VC-dimension, Combinatorica 13, 1993, 455–466.
21.Har-Peled, S. Constructing planar cuttings in theory and practice, SIAM J. Comput. 29, 2000, 2016–2039.
22.Erickson, J. New lower bounds for Hopcroft’s problem, Disc. Comput. Geom. 16, 1996, 389–418.
23.Matoušek, J. Range searching with efficient hierarchical cuttings, Disc. Comput. Geom. 10, 1993, 157–182.
24.Clarkson, K.L., Shor, P.W. Applications of random sampling in computational geometry, II, Disc. Comput. Geom. 4, 1989, 387–421.
25.Chazelle, B. An optimal convex hull algorithm in any fixed dimension, Disc. Comput. Geom. 10, 1993, 377–409.
26.Edelsbrunner, H. Algorithms in Combinatorial Geometry, Springer-Verlag, Berlin, 1987.
27.Ziegler, G.M. Lectures on Polytopes, Graduate Texts in Mathematics, 152, Springer, New York, 1995.
28.Matoušek, J. Efficient partition trees, Disc. Comput. Geom. 8, 1992, 315–334.
29.Chazelle, B., Sharir, M., Welzl, E. Quasi-optimal upper bounds for simplex range searching and new zone theorems, Algorithmica 8, 1992, 407–429.
*This chapter has been reprinted from first edition of this Handbook, without any content updates.