
Statistics Measuring Centrality
Centrality Revisited
As mentioned in Chapter 3, when looking at a variable, centrality is the most representative
data point in the spread of data. The type of centrality measure depends on the type
of variable as discussed next.
Centrality for Continuous Variables
Means/Averages
For interval or ratio data we most commonly use the mean/average like the statistics in the “Mean” column of the summary Figure 7.1 Example of a final descriptive statistics table and the “Mean” column of the SAS output in Figure 7.3 Example of descriptive statistics output via SAS PROC MEANS.
To get the average of a set of scores add all the scores together and divide by the
number of data points. For example, the average of the set 2,3,5,5,6,6,6,7,8,10 is
(2 + 3 + 5 + 5 + 6 + 6 + 6 + 7 + 8 + 10)/10 = 5.8. (We divided by 10 because there
are 10 datapoints). Of course, any computer program from Microsoft Excel to SAS will
do this for you.
Note the following about averages:
-
You should usually use an average only if the data is continuous (interval or ratio), that is, the data should represent something that naturally runs from small to big so that scores can be compared in terms of magnitude between them (e.g. scores where 1 is worse than 3, and where the difference of 1 point between someone who got a 10 versus a 9 means something in itself).
-
Averages should not be used if the data is ordinal or just arbitrary codes that do not have a special order in comparison to each other (categorical data).
-
There are other kinds of averages (for instance, a geometric average) that are used for certain data situations. Generally the outcome is the same (a central score felt to be the representative middle of the data spread).
Medians
For a continuous data centrality statistic you should always also estimate the median. The median is the score that 50% of sample lies both above and below. It is also
known as the 50th percentile. Figure 7.1 Example of a final descriptive statistics table has a median column for each variable too.
To get the median of a set of scores, arrange all the scores together from low to
high and estimate the middle score (the score that half the data lies above and half
lies below). For example, if we have five scores arranged from low to high 12,15,17,23,24
then the middle score (median) is 17 since half the scores lie above it and half below[1] . Of course, once again the computer will calculate this for you.
It is always a good idea to ask for both the median and the mean when evaluating the centrality
of continuous variables
Always Use Both Medians & Averages for Continuous Variables
With continuous variables, the median and the mean can differ if the data are not
equally spread out around the mean. If you have unusually large or small data points
compared to the others, this will affect the average. For instance, I once did business-to-business
research in which an important variable was size of the supplier (Lee, 2010). Average
supplier size was estimated at 1,108 employees. However, the median supplier size was only 60. What was happening? Simply, the sample mostly comprised small suppliers with around
60 employees. However, at the far end there were a few extremely large suppliers with
10,000 or even far more employees. These few very large suppliers make the average
far larger.
You should therefore always ask for both statistics when evaluating any continuous
variable. If there exist large differences in the mean and median then find out why
(usually we would look at the overall distribution of the variable as discussed below),
and decide what to do with this information.
Centrality for Ordinal Variables
With ordinal variables we would usually use only the median. Many people do mistakenly
use averages, which is usually methodologically incorrect, as means don’t always make
sense in the context of ordinal variables. For instance, say you ask consumers to
rank five characteristics of cars from most to least important. How important is the
Price characteristic then for Female consumers versus Male? You may average the rank
given by Males versus Females and find that men rate Price as an average of 1.8 while
women rank it 2.6. However, in reality, no man or woman could have given a rank of
1.8 or 2.6 since ranks are whole numbers like 1 (= most important), 2 (second most
important) and the like. Median ranks would lie on a whole number rank, and be a better
reflection. In addition, because ordinal data is often not normally distributed, the
average would be incorrect.
Centrality for Categorical Variables
There is not really a centrality measure per se for categorical data. However, you
can report either the percentage or number of responses in each group (e.g. percentage males versus females). You can use the SAS PROC FREQ
module for this. The mode represents the most common response, and can be found in all the descriptive statistics
modules in SAS including MEANS, UNIVARIATE and FREQ.
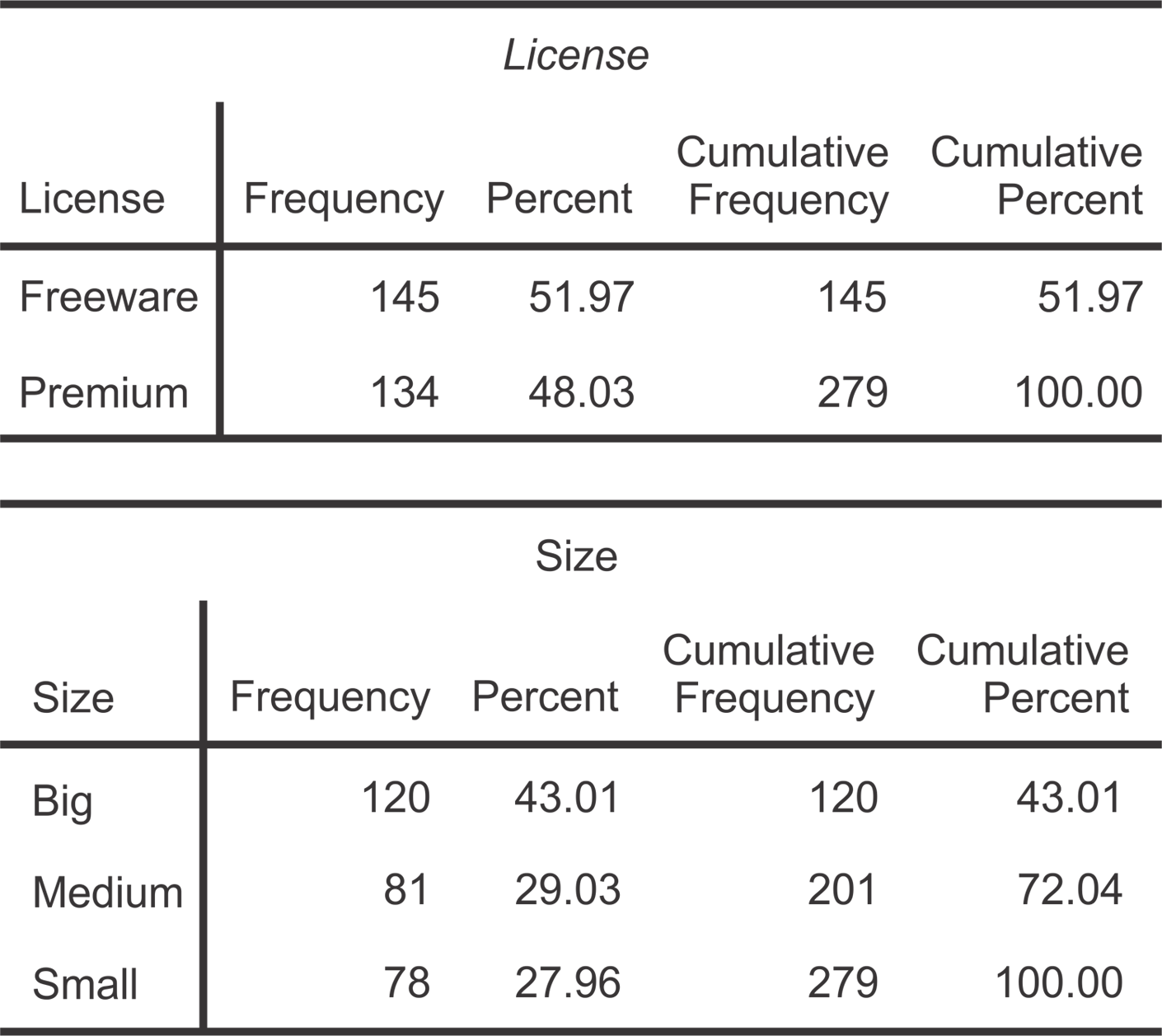
Your first question when you do basic summary statistics on categorical variables
is how many and what percentages of observations fall into each category. In our case
example, what number (frequency) and percentage of the customers have freeware versus
premium licenses, or are small, medium or big in size? To see this example of categorical
variable frequencies for our data, open and run the file “Code07c Categorical frequency”
which is based on the dataset “Data02_Cleaned”. You should get the output from Figure 7.4 Example of frequency analysis of categorical data in SAS.
As you can see from Figure 7.4 Example of frequency analysis of categorical data in SAS, if you have categorical data you can really only calculate how many of each category
there are. The ‘central’ data point is then the one which occurs most often (e.g.
the 43.01% of Big firms in Figure 7.4 Example of frequency analysis of categorical data in SAS). This most common response is the “mode.”
You should then arrange the frequencies in a good tabular format, like that in Figure 7.1 Example of a final descriptive statistics table.
Figure 7.4 Example of frequency analysis of categorical data in SAS
Next, we discuss in detail the analysis of the third characteristic of variables,
namely variable spread.
Last updated: April 18, 2017
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.