
In this section, we will look at a number of practical things you can do to ensure your geo-spatial databases work as efficiently and effectively as possible.
As we've seen in earlier chapters, different sets of geo-spatial data use different coordinate systems, datums, and projections. Consider, for example, the following two geometry objects:
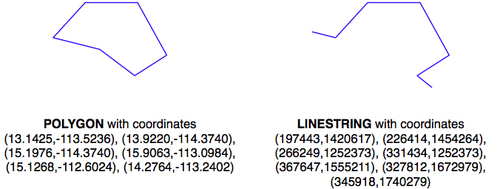
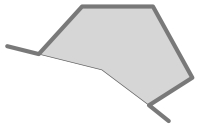
The geometries are represented as a series of coordinates, which are nothing more than numbers. By themselves, these numbers aren't particularly useful—you need to position these coordinates onto the Earth's surface by identifying the spatial reference (coordinate system, datum, and projection) used by the geometry. In this case, the POLYGON is using unprojected lat/long coordinates in the WGS84 datum, while the LINESTRING is using coordinates defined in meters using the UTM Zone 12N projection. Once you know the spatial reference, you can place the two geometries onto the Earth's surface. This reveals that the two geometries actually overlap:
In all but the most trivial databases, it is recommended that you store the spatial reference for each feature directly in the database itself. This makes it easy to keep track of which spatial reference is used by each feature. It also allows the queries and database commands you write to be aware of the spatial reference, and enables you to transform geometries from one spatial reference to another as necessary in your spatial queries.
Spatial references are generally referred to using a simple integer value called a Spatial Reference Identifier or SRID. While you could choose arbitrary SRID values to represent various spatial references, it is strongly recommended that you use the European Petroleum Survey Group (EPSG) numbers as standard SRID values. Using this internationally-recognized standard makes your data interchangeable with other databases, and allows tools such as OGR and Mapnik to identify the spatial reference used by your data.
To learn more about EPSG numbers, and SRID values in general, please refer to:
You have seen SRID values before. For example, in the Using SpatiaLite section of this chapter, we encountered the following SQL statement:
SELECT AddGeometryColumn('cities','geom',4326,'POLYGON',2)
The value 4326 is the SRID used to identify a particular spatial reference, in this case the WGS84 Long Lat reference (unprojected lat/long coordinates using the WGS84 datum).
Both PostGIS and SpatiaLite add a special table to your spatially-enabled database called spatial_ref_sys. This table comes pre-loaded with a list of over 3,000 commonly-used spatial references, all identified by EPSG number. Because the SRID value is the primary key into this table, tools that access the database can refer to this table to perform on-the-fly coordinate transformations using the PROJ.4 library. Even if you are using MySQL, which doesn't provide a spatial_ref_sys table or other direct support for coordinate transformations, you should be using standard EPSG numbers for your spatial references.
Note that all three open source spatial databases allow you to associate an SRID value with a geometry when importing from WKT:
- MySQL:
GeometryFromText(wkt, [srid]) - PostGIS:
ST_GeometryFromText(wkt, [srid]) - SpatiaLite:
GeometryFromText(wkt, [srid])
While the SRID value is optional, you should use this wherever possible to tell the database which spatial reference your geometry is using. In fact, both PostGIS and SpatiaLite require you to use the correct SRID value if a column has been set up to use a particular SRID. This prevents you from mixing the spatial references within a table.
When you import spatial data into your database, it will be in a particular spatial reference. This doesn't mean, though, that it has to stay in that spatial reference. In many cases, it will be more efficient and accurate to transform your data into the most appropriate spatial reference for your particular needs. Of course, "appropriate" depends on what you want to achieve.
With the exception of PostGIS and its new Geography type, all three spatial databases assume that coordinates exist on a cartesian plane—that is, that you are using projected coordinates. If you store unprojected coordinates (latitude and longitude values) in the database, you will be limited in what you can do. Certainly, you can use unprojected geographic coordinates in a database to compare two features (for example, to see if one feature intersects with another), and you will be able to store and retrieve geo-spatial data quickly. However, any calculation that involves area or distance will be all but meaningless.
Consider, for example, what would happen if you asked MySQL to calculate the length of a LINESTRING geometry:
mysql SELECT GLength(geom) FROM roads WHERE id=9513; +-------------------+ | GLength(geom) | +-------------------+ | 192.3644911426572 | +-------------------+
If your data was in unprojected lat/long coordinates, the resulting "length" would be a number in decimal degrees. Unfortunately, this number is not particularly useful. You can't assume a simple relationship between the decimal degree length and the actual length on the Earth's surface, for example multiplying by some constant to yield the true length in meters. The only thing this so-called "length" value would be useful for would be to give a very rough estimate of the true length, as we did in the previous chapter to filter out features obviously too far away.
If you do need to perform length and area calculations on your geo-spatial data (and it is likely that you will need to do this at some stage), you have three options:
- Use a database that supports unprojected coordinates
- Transform the features into projected coordinates before performing the length or distance calculation
- Store your geometries in projected coordinates from the outset
Let's consider each of these options in more detail.
Of the open source databases we are considering, only PostGIS has the ability to work directly with unprojected coordinates, through the use of the relatively-new Geography type. Unfortunately, the Geography type has some major limitations that make this a less than ideal solution:
- Performing calculations on unprojected coordinates takes approximately an order of magnitude longer than performing the same calculations using projected (cartesian) coordinates
- The Geography type only supports lat/long values on the WGS84 datum (SRID 4326)
- Many of the functions available for projected coordinates are not yet supported by the Geography type
For these reasons, as well as the fact that the they are only supported by PostGIS, we will not be using Geography columns in this book.
Another possibility is to store your data in unprojected lat/long coordinates, and transform the coordinates into a projected coordinate system before you calculate the distance or area. While this will work, and will give you accurate results, you should beware of doing this because you may well forget to transform into a projected coordinate system before making the calculation. Also, performing on-the-fly transformations of large numbers of geometries is very time-consuming.
Despite these problems, there are situations where storing unprojected coordinates makes sense. We will look at this shortly.
Because transforming features from one spatial reference to another is rather time-consuming, it often makes sense to do this once, at the time you import your data, and store it in the database already converted to a projected coordinate system.
Doing this, you will be able to perform your desired spatial calculations quickly and accurately. However, there are situations where this is not the best option, as we will see in the next section.
As we saw in Chapter 2, projecting features from the three-dimensional surface of the Earth onto a two-dimensional cartesian plane can never be done perfectly. It is a mathematical truism that there will always be errors in any projection.
Different map projections are generally chosen to preserve values such as distance or area for a particular portion of the Earth's surface. For example, the Mercator projection is accurate at the tropics, but distorts features closer to the Poles.
Because of this inevitable distortion, projected coordinates work best when your geo-spatial data only covers a part of the Earth's surface. If you are only dealing with data for Austria, then a projected coordinate system will work very well indeed. But, if your data includes features in both Austria and Australia, then using the same projected coordinates for both sets of features will once again produce inaccurate results.
For this reason, it is generally best to use a projected coordinate system for data that covers only part of the Earth's surface, but unprojected coordinates will work best if you need to store data covering large parts of the Earth.
Of course, using unprojected coordinates leads to problems of its own, as discussed above. This is why it's recommended that you use the appropriate spatial reference for your particular needs; what is appropriate for you depends on what data you need to store and how you intend to use it.
Imagine that you have a cities table with a geom column containing POLYGON geometries in UTM 12N projection (EPSG number 32612). Being a competent geo-spatial developer, you have set up a spatial index on this column.
Now, imagine that you have a variable named pt that holds a POINT geometry in unprojected WGS84 coordinates (EPSG number 4326). You might want to find the city that contains this point, so you issue the following reasonable-looking query:
SELECT * FROM cities WHERE
Contains(Transform(geom, 4326), pt);
This will give you the right answer, but it will take an extremely long time. Why? Because the Transform(geom, 4326) expression is converting every geometry in the table from UTM 12N to long-lat WGS84 coordinates before the database can check to see if the point is inside the geometry. The spatial index is completely ignored as it is in the wrong coordinate system.
Compare this with the following query:
SELECT * FROM cities WHERE
Contains(geom, Transform(pt, 32612));
A very minor change, but a dramatically different result. Instead of taking hours, the answer should come back almost immediately. Can you see why? The transformation is being done on a variable that does not change from one record to the next, so the Transform(pt, 32612) expression is being called just once, and the Contains() call can make use of your spatial index to quickly find the matching city.
The lesson here is simple—be aware of what you are asking the database to do, and make sure you structure your queries to avoid on-the-fly transformations of large numbers of geometries.
While we are discussing database queries that can cause the database to perform a huge amount of work, consider the following (where poly is a polygon):
SELECT * FROM cities WHERE
NOT ST_IsEmpty(ST_Intersection(outline, poly));
In a sense, this is perfectly reasonable: identify all cities that have a non-empty intersection between the city's outline and the given polygon. And, the database will indeed be able to answer this query—it will just take an extremely long time to do so. Hopefully, you can see why: the ST_Intersection() function creates a new geometry out of two existing geometries. This means that for every row in the database table, a new geometry is created, and is then passed to ST_IsEmpty(). As you can imagine, these types of operations are extremely inefficient. To avoid creating a new geometry each time, you can rephrase your query like this:
SELECT * FROM cities WHERE ST_Intersects(outline, poly);
While this example may seem obvious, there are many cases where spatial developers have forgotten this rule, and have wondered why their queries were taking so long to complete. A common example is to use the ST_Buffer() function to see if a point is within a given distance of a polygon, like this:
SELECT * FROM cities WHERE
ST_Contains(ST_Buffer(outline, 100), pt);
Once again, this query will work, but will be painfully slow. A much better approach would be to use the ST_DWithin() function:
SELECT * FROM cities WHERE ST_DWithin(outline, pt, 100);
As a general rule, remember that you never want to call any function that returns a Geometry object (or one of its subclasses) within the WHERE portion of a SELECT statement.
Just like ordinary database indexes can make an immense difference to the speed and efficiency of your database, spatial indexes are also an extremely powerful tool for speeding up your database queries. Like all powerful tools, though, they have their limits:
- If you don't explicitly define a spatial index, the database can't use it. Conversely, if you have too many spatial indexes, the database will slow down because each index needs to be updated every time a record is added, updated, or deleted. Thus, it is crucial that you define the right set of spatial indexes: index the information you are going to search on, and nothing more.
- Because spatial indexes work on the geometries' bounding boxes, the index itself can only tell you which bounding boxes actually overlap or intersect; they can't tell you if the underlying points, lines, or polygons have this relationship. Thus, they are really only the first step in searching for the information you want. With PostGIS and SpatiaLite, the database itself can further refine the search by comparing the individual geometries for you; with MySQL, you have to do this yourself, as we saw earlier.
- Spatial indexes are most efficient when dealing with lots of relatively small geometries. If you have large polygons consisting of many thousands of vertices, the polygon's bounding box is going to be so large that it will intersect with lots of other geometries, and the database will have to revert to doing full polygon calculations rather than just the bounding box. If your geometries are huge, these calculations can be very slow indeed—the entire polygon will have to be loaded into memory and processed one vertex at a time. If possible, it is generally better to split large polygons (and in particular large multipolygons) into smaller pieces so that the spatial index can work with them more efficiently.
When you send a query to the database, it automatically attempts to optimize the query to avoid unnecessary calculations and to make use of any available indexes. For example, if you issued the following (non-spatial) query:
SELECT * FROM people WHERE name=Concat("John ","Doe");
The database would know that Concat("John ","Doe") yields a constant, and so would only calculate it once before issuing the query. It would also look for a database index on the name column, and use it to speed up the operation.
This type of query optimization is very powerful, and the logic behind it is extremely complex. In a similar way, spatial databases have a spatial query optimizer that looks for ways to pre-calculate values and make use of spatial indexes to speed up the query. For example, consider this spatial query from the previous section:
select * from cities where ST_DWithin(outline, pt, 12.5);
In this case, the PostGIS function ST_DWithin() is given one geometry taken from a table (outline), and a second geometry that is specified as a fixed value (pt), along with a desired distance (12.5 "units", whatever that means in the geometry's spatial reference). The query optimizer knows how to handle this efficiently, by first pre-calculating the bounding box for the fixed geometry plus the desired distance (pt ±12.5), and then using a spatial index to quickly identify the records that may have their outline geometry within that extended bounding box.
While there are times when the database's query optimizer seems to be capable of magic, there are many other times when it is incredibly stupid. Part of the art of being a good database developer is to have a keen sense of how your database's query optimizer works, when it doesn't—and what to do about it.
Let's see how you can find out more about the query optimization process in each of our three spatial databases.
MySQL provides a command, EXPLAIN SELECT, that tells you how the query optimizer has tried to process your query. For example:
mysql> EXPLAIN SELECT * FROM cities
WHERE MBRContains(geom,
GeomFromText(pt))G
*********************** 1. row ***********************
id: 1
select_type: SIMPLE
table: cities
type: range
possible_keys: geom
key: geom
key_len: 34
ref: NULL
rows: 1
Extra: Using where
1 row in set (0.00 sec)
Note
Don't worry about the G at the end of the command; this just formats the output in a way that makes it easier to read.
This command tells you that this query involves a simple search against the cities table, searching for a range of records using the geom spatial index to speed up the results. The rows:1 tells you that the query optimizer thinks it only needs to read a single row from the table to find the results.
This is good. Compare it with:
mysql> EXPLAIN SELECT * FROM cities
WHERE MBRContains(Envelope(geom),
GeomFromText(pt))G
*********************** 1. row ***********************
id: 1
select_type: SIMPLE
table: cities
type: ALL
possible_keys: NULL
key: NULL
key_len: NULL
ref: NULL
rows: 34916
Extra: Using where
1 row in set (0.00 sec)
This query uses the Envelope() function to create a new geometry, which is then checked to see if it contains the given point. As explained in the Don't Create Geometries Within a Query section, previously, the database has to create a new geometry for every row in the table. In this case, the query optimizer cannot use an index, as shown by the NULL value for possible_keys and key. It also tells you that it would have to scan through 34,916 records to find the matching points—not exactly an efficient query. Indeed, running this query could take several minutes to complete.
MySQL uses a theoretical approach to query optimization, looking only at the query itself to see how it could be optimized. PostGIS, on the other hand, takes into account the amount of information in the database and how it is distributed. In order to work well, the PostGIS query optimizer needs to have up-to-date statistics on the database's contents. It then uses a sophisticated genetic algorithm to determine the most effective way to run a particular query.
Because of this approach, you need to regularly run the VACUUM ANALYZE command, which gathers statistics on the database so that the query optimizer can work as effectively as possible. If you don't run VACUUM ANALYZE, the optimizer simply won't be able to work.
Here is how you can run the VACUUM ANALYZE command from Python:
import psycopg2
connection = psycopg2.connect("dbname=... user=...")
cursor = connection.cursor()
old_level = connection.isolation_level
connection.set_isolation_level(0)
cursor.execute("VACUUM ANALYZE")
connection.set_isolation_level(old_level)
Don't worry about the isolation_level logic here; that just allows you to run the VACUUM ANALYZE command from Python using the transaction-based psycopg2 adapter.
Tip
It is possible to set up an autovacuum daemon that runs automatically after a given period of time, or after a table's contents has changed enough to warrant another vacuum. Setting up an autovacuum daemon is beyond the scope of this book.
Once you have run the VACUUM ANALYZE command, the query optimizer will be able to start optimizing your queries. As with MySQL, you can see how the query optimizer works using the EXPLAIN SELECT command:
psql> EXPLAIN SELECT * FROM cities
WHERE ST_Contains(geom,pt);
QUERY PLAN
--------------------------------------------------------
Seq Scan on cities (cost=0.00..7.51 rows=1 width=2619)
Filter: ((geom && '010100000000000000000000000000000000000000'::geometry) AND _st_contains(geom, '010100000000000000000000000000000000000000'::geometry))
(2 rows)
Don't worry about the Seq Scan part; there are only a few records in this table, so PostGIS knows that it can do a sequential scan of the entire table faster than it can read through an index. When the database gets bigger, it will automatically start using the index to quickly identify the desired records.
The cost= part is an indication of how much this query will "cost", measured in arbitrary units that by default are relative to how long it takes to read a page of data from disk. The two numbers represent the "start up cost" (how long it takes before the first row can be processed), and the estimated total cost (how long it would take to process every record in the table). Since reading a page of data from disk is quite fast, a total cost of 7.51 is very quick indeed.
The most interesting part of this explanation is the Filter. Let's take a closer look at what the EXPLAIN SELECT command tells us about how PostGIS will filter this query. The first part:
(geom && '010100000000000000000000000000000000000000'::geometry)
makes use of the&& operator, which searches for matching records using the bounding box defined in the spatial index. The second part of the filter condition:
_st_contains(geom, '010100000000000000000000000000000000000000'::geometry)
uses the ST_Contains() function to identify the exact geometries that actually contain the desired point. This two-step process (first filtering by bounding box, then by the geometry itself) is exactly what we had to implement manually when using MySQL. As you can see, PostGIS does this for us automatically, resulting in a quick but also accurate search for geometries that contain a given point.
One of the disadvantages of using a lightweight database such as SpatiaLite is that the query optimizer is rather naïve. In particular, the SpatiaLite query optimizer will only make use of B*Tree indexes; you can create a spatial R-Tree index, but it won't be used unless you explicitly include it in your query.
For example, consider the following SQL statements:
CREATE TABLE cities (id INTEGER PRIMARY KEY AUTOINCREMENT,
name CHAR(255));
SELECT AddGeometryColumn('cities','geom',4326,'POLYGON',2);
INSERT INTO cities (name,geom)
VALUES ('London', GeomFromText(wkt, 4326);
This creates a cities table, defines a spatial index, and inserts a record into the table. Because SpatiaLite uses triggers to automatically update the spatial index as records are added, updated, or deleted, the above statements would correctly create the spatial index and update it as the new record is inserted. However, if we then issue the following query:
SELECT * FROM cities WHERE Contains(geom, pt);
The SpatiaLite query optimizer won't know about the spatial index, and so will ignore it. We can confirm this using the EXPLAIN QUERY PLAN command, which shows the indexes used by the query:
sqlite> EXPLAIN QUERY PLAN SELECT * FROM cities
WHERE id < 100;
0|0|TABLE cities USING PRIMARY KEY
sqlite> EXPLAIN QUERY PLAN SELECT * FROM cities
WHERE Contains(geom, pt);
0|0|TABLE cities
The first query (WHERE id < 100) makes use of a B*Tree index, and so the query optimizer knows to use the primary key to index the query. The second query (WHERE Contains(geom, pt)) uses the spatial index that the query optimizer doesn't know about. In this case, the cities table will be scanned sequentially, without any index at all. This will be acceptable for small numbers of records, but for large databases this will be very slow indeed.
To use the spatial index, we have to include it directly in the query:
SELECT * FROM cities WHERE id IN
(SELECT pkid FROM idx_cities_geom WHERE xmin <= X(pt)
AND X(pt) <= xmax AND ymin <= Y(pt) AND Y(pt) <= ymax);
The EXPLAIN QUERY PLAN command tells us that this query would indeed use the database indexes to speed up the query:
sqlite> EXPLAIN QUERY PLAN SELECT * FROM cities
WHERE id IN (SELECT pkid FROM idx_cities_geom
WHERE xmin <= X(pt) AND X(pt) <= xmax
AND ymin <= Y(pt) AND Y(pt) <= ymax);
0|0|TABLE cities USING PRIMARY KEY
0|0|TABLE idx_cities_geom VIRTUAL TABLE INDEX 2:BaDbBcDd
This is an unfortunate consequence of using SpatiaLite—you have to include the indexes explicitly in every spatial query you make, or they won't be used at all. This can make creating your spatial queries more complicated, though the performance of the end result will be excellent.