
In this age of Internet, everything available over the Internet is not useful for everyone. Different companies and entities use different approaches to find out relevant content for their audiences. People started building algorithms to construct a relevance score, based on which recommendations could be built and suggested to the users. In my day to day life, every time I see an image on Google, 3-4 other images are recommended to me by Google, every time I look for some videos on YouTube, 10 more videos are recommended to me, every time I visit Amazon to buy some products, 5-6 products are recommended to me, and, every time I read one blog or article, a few more articles and blogs are recommended to me. This is an evidence of algorithmic forces at play to recommend certain things based on user's preferences or choices, since the user's time is precious and content available over Internet is unlimited. Hence, recommendation engine helps organizations customize their offerings based on the user's preferences so that the user does not have to spend time in exploring what is required.
In this chapter, the reader will learn the following things and their implementation using R programming language:
- What is recommendation and how does that work
- Types and methods for performing recommendation
- Implementation of product recommendation using R
Recommendation is a method or technique by which an algorithm detects what the user is looking at. Recommendation can be of products, services, food, videos, audios, images, news articles, and so on. What recommendation is can be made much clearer if we look around and note what we observe over the Internet day in and day out. For example, consider news aggregator websites and how they recommend articles to users. They look at the tags, timing of the article loaded into Internet, number of comments, likes, and shares for that article, and of course geolocation, among other details, and then model the metadata information to arrive at a score. Based on that score, they start recommending articles to new users. Same thing happens when we watch a video on YouTube. Similarly, beer recommendation system also works; the user has to select any beer at random and based on the first product chosen, the algorithm recommends other beers based on similar users' historical purchase information. Same thing happens when we buy products from online e-commerce portals.
Broadly, there are four different types of recommendation systems that exist:
- Content-based recommendation method
- Collaborative filtering-based recommendation method
- Demographic segment-based recommendation method
- Association rule based-recommendation method
In content-based method, the terms, concepts which are also known as keywords, define the relevance. If the matching keywords from any page that the user is reading currently are found in any other content available over Internet, then start calculating the term frequencies and assign a score and based on that score whichever is closer represent that to the user. Basically, in content-based methods, the text is used to find the match between two documents so that the recommendation can be generated.
In collaborative filtering, there are two variants: user-based collaborative filtering and item-based collaborative filtering.
In user-based collaborative filtering method, the user-user similarity is computed by the algorithm and then based on their preferences the recommendation is generated. In item based collaborative filtering, item-item similarity is considered to generate recommendation.
In demographic segment based category, the age, gender, marital status, and location of the users, along with their income, job, or any other available feature, are taken into consideration to create customer segments. Once the segments are created then at a segment level the most popular product is identified and recommended to new users who belong to those respective segments.
To filter out abundant information available online and recommend useful information to the user at first hand is the prime motivation for creating recommendation engine. So how does the collaborative filtering work? Collaborative filtering algorithm generates recommendations based on a subset of users that are most similar to the active user. Each time a recommendation is requested, the algorithm needs to compute the similarity between the active user and all the other users, based on their co-rated items, so as to pick the ones with similar behaviour. Subsequently, the algorithm recommends items to the active user that are highly rated by his/her most similar users.
In order to compute the similarities between users, a variety of similarity measures have been proposed, such as Pearson correlation, cosine vector similarity, Spearman correlation, entropy-based uncertainty measure, and mean square difference. Let's look at the mathematical formula behind the calculation and implementation using R.
The objective of a collaborative filtering algorithm is to suggest new items or to predict the utility of a certain item for a particular user based on the user's previous likings and the opinions of other like-minded users.
Memory-based algorithms utilize the entire user-item database to generate a prediction. These systems employ statistical techniques to find a set of users, known as neighbours, who have a history of agreeing with the target user (that is, they either rate the same items similarly or they tend to buy similar sets of items). Once a neighbourhood of users is formed, these systems use different algorithms to combine the preferences of neighbours to produce a prediction or top-N recommendation for the active user. The techniques, also known as nearest-neighbour or user-based collaborative filtering, are very popular and widely used in practice.
Model-based collaborative filtering algorithms provide item recommendation by first developing a model of user ratings. Algorithms in this category take a probabilistic approach and envision the collaborative filtering process as computing the expected value of a user prediction, given his/her ratings on other items. The model building process is performed by different machine learning algorithms, such as Bayesian network, clustering, and rule-based approaches.
One critical step in the item-based collaborative filtering algorithm is to compute the similarity between items and then to select the most similar items. The basic idea in similarity computation between two items i and j is to first isolate the users who have rated both of these items and then to apply a similarity computation technique to determine the similarity S(i,j).
There are a number of different ways to compute the similarity between items. Here we present three such methods. These are cosine-based similarity, correlation-based similarity, and adjusted-cosine similarity:
- Cosine-based similarity: Two items are thought of as two vectors in the m dimensional user-space. The similarity between them is measured by computing the cosine of the angle between these two vectors:
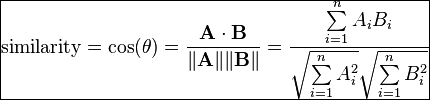
Preceding is the formula for computing cosine similarity between two vectors. Let's take a numerical example to compute the cosine similarity:
Cos (d1, d2) = 0.44
d1
d2
d1*d2
||d1||
||d2||
||d1||*||d2||
61636136400160053152592251221440500250200400462416365760500250300900616361365314310187711.9582610.04988Table 5: Results of cosine similarity
So cosine similarity between
d1andd2is 44%.Cos (d1, d2) = 0.441008707
- Correlation-based similarity: Similarity between two items i and j is measured by computing the Pearson-r correlation
corr. To make the correlation computation accurate, we must first isolate the co-rated cases. - Adjusted cosine similarity: One fundamental difference between the similarity computation in user-based CF and item-based CF is that in case of user-based CF the similarity is computed along the rows of the matrix, but in case of the item-based CF the similarity is computed along the columns, that is, each pair in the co-rated set corresponds to a different user. Computing similarity using basic cosine measure in item-based case has one important drawback - the difference in rating scale between different users is not taken into account. The adjusted cosine similarity offsets this drawback by subtracting the corresponding user average from each co-rated pair. The example is given in Table 1, where the co-rated set belongs to different users, users are in different rows of the table.