
In this chapter, you will learn about the top classification algorithms written in the R language. You will also learn the ways to improve the classifier.
We will cover the following topics:
- Ensemble methods
- Biological traits and Bayesian belief network
- Protein classification and the k-Nearest Neighbors algorithm
- Document retrieval and Support Vector Machine
- Text classification using sentential frequent itemsets and classification using frequent patterns
- Classification using the backpropagation algorithm
To improve the accuracy of classification, EM methods are developed. The accuracy is dramatically improved by at least one grade compared to its base classifiers, because the EM methods make mistakes only when at least half of the result of the base classifiers are wrong.
The concept structure of EM methods is illustrated in the following diagram:
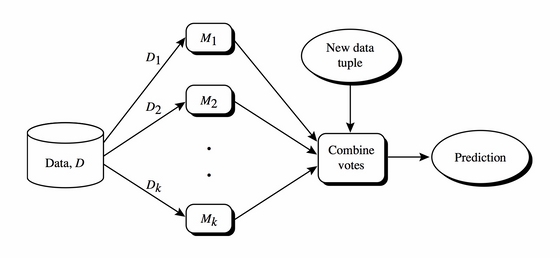
The label for the new data tuple is the result of the voting of a group of base classifiers. A combined classifier is created based on several base classifiers. Each classifier is trained with a different dataset or training set re-sampled with the replacement of the original training dataset.
Three popular EM methods are discussed in the successive sections:
- Bagging
- Boosting
- Random forests
Here is a concise description of the bagging algorithm (noted as the bootstrap aggregation), followed by the summarized pseudocode. For iteration i (![]() ), a training set,
), a training set, ![]() , of d tuples is sampled with replacement from the original set of tuples, D. Any training set is sampled by employing bootstrap sampling (with replacement) for it, which in turn is used to learn a classifier model,
, of d tuples is sampled with replacement from the original set of tuples, D. Any training set is sampled by employing bootstrap sampling (with replacement) for it, which in turn is used to learn a classifier model, ![]() . To classify an unknown or test tuple, X, each classifier,
. To classify an unknown or test tuple, X, each classifier, ![]() , returns its class prediction, which counts as one vote. Assume the number of classifiers as follows, which predicts the same class,
, returns its class prediction, which counts as one vote. Assume the number of classifiers as follows, which predicts the same class, ![]() , given the test tuple X:
, given the test tuple X:
The bagged classifier, ![]() , counts the votes and assigns the class with the most votes to X. Each vote has the same weight in the equation;
, counts the votes and assigns the class with the most votes to X. Each vote has the same weight in the equation;
About the prediction of continuous values, the average value of each prediction for a given test tuple is used as the result. The algorithm reduces the variance, given a more correct result than the base classifiers.
The input parameters for bagging algorithm are as follows:
- D: This is the training tuples dataset
- K: This is the number of classifiers combined
- S: This is a classification learning algorithm or scheme to learning base classifier
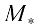 : This is the ensemble classifier, which is the output of the algorithm
: This is the ensemble classifier, which is the output of the algorithm
The summarized pseudocode for the bagging algorithm is as follows:

As opposed to an ensemble algorithm, the bagging algorithm is the weighted voting and weighted sample training tuple dataset for each base classifier. The base classifiers are learned iteratively. Once a classifier is learned, the relative weights are updated with a certain algorithm for the next learning of the base classifiers. The successive model learning will emphasize the tuples misclassified by the former classifier. As a direct result, the accuracy of a certain classifier will play an important role in the voting of the final label once an unknown test tuple is provided for the combined classifier.
Adaptive Boosting or AdaBoost is one of the boosting algorithms. If it contains K base classifiers, then the AdaBoost will be performed as K passes. Given the tuple dataset ![]() and its corresponding classifier
and its corresponding classifier ![]() , the error rate
, the error rate ![]() of classifier
of classifier ![]() is defined as follows:
is defined as follows:
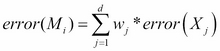
The new classifier ![]() will be discarded once the error (
will be discarded once the error (![]() ) is bigger than 0.5. The training tuples set will be resampled for this classifier and perform the training of this classifier from scratch.
) is bigger than 0.5. The training tuples set will be resampled for this classifier and perform the training of this classifier from scratch.
For tuple ![]() , the error function is as follows:
, the error function is as follows:
All the weights of the tuples in the training tuples dataset ![]() are initialized with
are initialized with ![]() . When the classifier
. When the classifier ![]() is learned from the training tuples set
is learned from the training tuples set ![]() , the weight for the tuple, which is correctly classified, is multiplied by
, the weight for the tuple, which is correctly classified, is multiplied by 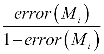 . After the updates, the weights for all tuples are normalized, which means the weight of the classified tuple increases and the weight of the others decreases.
. After the updates, the weights for all tuples are normalized, which means the weight of the classified tuple increases and the weight of the others decreases.
The weight of the vote of classifier ![]() is as follows:
is as follows:
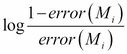
We defined ![]() as the weight of the vote for class
as the weight of the vote for class ![]() upon the K classifiers,
upon the K classifiers, ![]() representing the weight of the ith classifier:
representing the weight of the ith classifier:
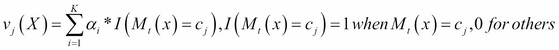
The AdaBoost combined classifier, ![]() , counts the votes with their respective weights multiplied and assigns the class with the most votes to
, counts the votes with their respective weights multiplied and assigns the class with the most votes to X. Each vote has the same weight in the equation:
The input parameters for the AdaBoost algorithm are as follows:
- D, which denotes a set of training tuples
- k, which is the number of rounds
- A classification learning algorithm
The output of the algorithm is a composite model. The pseudocode of AdaBoost is listed here:

Random forests algorithm is an ensemble method to combine a group of decision trees, which is generated by a strategy of applying a random selection of attributes at each node that will be split. Given an unknown tuple, each classifier votes, and the most popular one decides the final result. The pseudocode for the ForestRI algorithm to generate a forest is as follows:

T denotes a total order of the variables in line 2. In line 5, ![]() denotes the set of variables preceding
denotes the set of variables preceding ![]() . Prior knowledge is required for line 6.
. Prior knowledge is required for line 6.
Instead of random selection of attributes on splitting the node, for another algorithm, ForestRC, the random linear combination strategy of the existing attributes is used to split the task. New attributes are built by the random linear combination of the original attributes set. With a couple of new attributes added, the best split is searched over the updated attributes set including the new and original attributes.
Here we provide three R implementations, bagging, AdaBoost, and Random forests. Please look up the R codes file ch_04_bagging.R, ch_04_adaboost.R, ch_04_forestrc.R, and ch_04_forestri.R from the bundle of R codes for the previously mentioned algorithms. The codes can be tested with the following commands:
> source("ch_04_bagging.R") > source("ch_04_adaboost.R") > source("ch_04_forestrc.R") > source("ch_04_forestri.R")
The following algorithm is the parallelized AdaBoost algorithm, which depends on a couple of workers to construct boosting classifiers. The dataset for the pth worker is defined using the following formula, where, ![]() denoting its size is
denoting its size is ![]() :
:
The classifier ![]() is defined in the following format, with
is defined in the following format, with ![]() as the weight:
as the weight:
The output is the final classifier. The input is the training dataset of M workers ![]() .
.
