
The Naïve Bayes classification presumes that all attributes are independent; it simplifies the Bayes classification and doesn't need the related probability computation. The likelihood can be defined with the following equation:

Some of the characteristics of the Naïve Bayes classification are as follows:
The pseudocode of the Naïve Bayes classification algorithm, with minor differences from the Bayes classification algorithm, is as follows:

The R code for the Naïve Bayes classification is listed as follows:
1 NaiveBayesClassifier <- function(data,classes){
2 naive.bayes.model <- NULL
3
4 data.subsets <- SplitData(data,classes)
5 cards <- GetCardinality(data.subsets)
6 prior.p <- GetPriorProbability(cards)
7 means <- GetMeans(data.subsets,cards)
8 variances.m <- GetVariancesMatrix(data.subsets,cards,means)
9
10 AddCardinality(naive.bayes.model,cards)
11 AddPriorProbability(naive.bayes.model,prior.p)
12 AddMeans(naive.bayes.model,means)
13 AddVariancesMatrix(naive.bayes.model,variances.m)
14
15 return(naive.bayes.model)
16 }
17
18 TestClassifier <- function(x){
19 data <- GetTrainingData()
20 classes <- GetClasses()
21 naive.bayes.model <- NaiveBayesClassifier(data,classes)
22
23 y <- GetLabelForMaxPostProbability(bayes.model,x)
24
25 return(y)
26 }One example is chosen to apply the Naïve Bayes classification algorithm, in the following section.
E-mail spam is one of the major issues on the Internet. It refers to irrelevant, inappropriate, and unsolicited emails to irrelevant receivers, pursuing advertisement and promotion, spreading malware, and so on.
The increase in e-mail users, business e-mail campaigns, and suspicious usage of e-mail have resulted in a massive dataset of spam e-mails, which in turn necessitate high-efficiency solutions to detect e-mail spam:
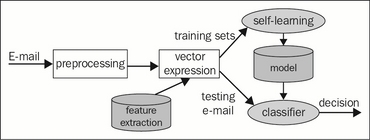
E-mail spam filters are automated tools that recognize spam and prevent further delivery. The classifier serves as a spam detector here. One solution is to combine inputs of a couple of e-mail spam classifiers to present improved classification effectiveness and robustness.
Spam e-mail can be judged from its content, title, and so on. As a result, the attributes of the e-mails, such as subject, content, sender address, IP address, time-related attributes, in-count /out-count, and communication interaction average, can be selected into the attributes set of the data instance in the dataset. Example attributes include the occurrence of HTML form tags, IP-based URLs, age of link-to domains, nonmatching URLs, HTML e-mail, number of links in the e-mail body, and so on. The candidate attributes include discrete and continuous types.
The training dataset for the Naïve Bayes classifier will be composed of the labeled spam e-mails and legitimate e-mails.