
Data mining is the discovery of a model in data; it's also called exploratory data analysis, and discovers useful, valid, unexpected, and understandable knowledge from the data. Some goals are shared with other sciences, such as statistics, artificial intelligence, machine learning, and pattern recognition. Data mining has been frequently treated as an algorithmic problem in most cases. Clustering, classification, association rule learning, anomaly detection, regression, and summarization are all part of the tasks belonging to data mining.
The data mining methods can be summarized into two main categories of data mining problems: feature extraction and summarization.
This is to extract the most prominent features of the data and ignore the rest. Here are some examples:
- Frequent itemsets: This model makes sense for data that consists of baskets of small sets of items.
- Similar items: Sometimes your data looks like a collection of sets and the objective is to find pairs of sets that have a relatively large fraction of their elements in common. It's a fundamental problem of data mining.
The target is to summarize the dataset succinctly and approximately, such as clustering, which is the process of examining a collection of points (data) and grouping the points into clusters according to some measure. The goal is that points in the same cluster have a small distance from one another, while points in different clusters are at a large distance from one another.
There are two popular processes to define the data mining process in different perspectives, and the more widely adopted one is CRISP-DM:
There are six phases in this process that are shown in the following figure; it is not rigid, but often has a great deal of backtracking:
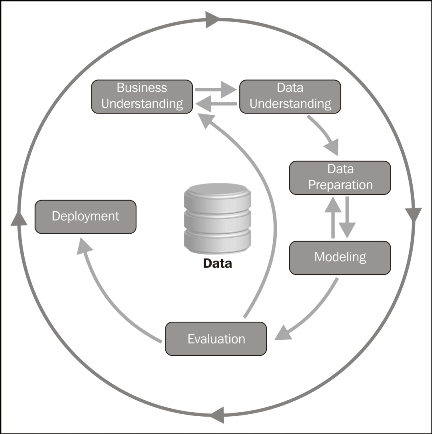
Let's look at the phases in detail:
- Business understanding: This task includes determining business objectives, assessing the current situation, establishing data mining goals, and developing a plan.
- Data understanding: This task evaluates data requirements and includes initial data collection, data description, data exploration, and the verification of data quality.
- Data preparation: Once available, data resources are identified in the last step. Then, the data needs to be selected, cleaned, and then built into the desired form and format.
- Modeling: Visualization and cluster analysis are useful for initial analysis. The initial association rules can be developed by applying tools such as generalized rule induction. This is a data mining technique to discover knowledge represented as rules to illustrate the data in the view of causal relationship between conditional factors and a given decision/outcome. The models appropriate to the data type can also be applied.
- Evaluation :The results should be evaluated in the context specified by the business objectives in the first step. This leads to the identification of new needs and in turn reverts to the prior phases in most cases.
- Deployment: Data mining can be used to both verify previously held hypotheses or for knowledge.
Here is an overview of the process for SEMMA:
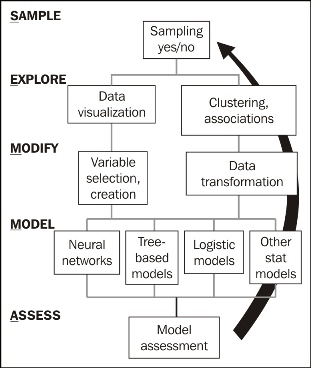
Let's look at these processes in detail:
- Sample: In this step, a portion of a large dataset is extracted
- Explore: To gain a better understanding of the dataset, unanticipated trends and anomalies are searched in this step
- Modify: The variables are created, selected, and transformed to focus on the model construction process
- Model: A variable combination of models is searched to predict a desired outcome
- Assess: The findings from the data mining process are evaluated by its usefulness and reliability