
The k-medoids algorithm is extended from the k-means algorithm to decrease the sensitivity to the outlier data points.
Given the dataset D and the predefined parameter k, the k-medoids algorithm or the PAM algorithm can be described as shown in the upcoming paragraphs.
As per a clustering related to a set of k medoids, the quality is measured by the average distance between the members in each cluster and the corresponding representative or medoids.
An arbitrary selection of k objects from the initial dataset of objects is the first step to find the k medoids. In each step, for a selected object ![]() and a nonselected node
and a nonselected node ![]() , if the quality of the cluster is improved as a result of swapping them, then a swap is performed.
, if the quality of the cluster is improved as a result of swapping them, then a swap is performed.
The cluster quality should be the sum of all the differences in the distance between the members and medoids, before and after the swap. For each nonselected object ![]() , there are four difference cases under consideration (they are marked out in the following diagram). Given a set of medoids, one of them is
, there are four difference cases under consideration (they are marked out in the following diagram). Given a set of medoids, one of them is ![]() , and the cluster related to it is
, and the cluster related to it is ![]() .
.

- Case 1: The first difference case is
 , given that
, given that  is the representative of the second medoid that is closer or more similar to
is the representative of the second medoid that is closer or more similar to  :
After swapping,
:
After swapping, will be relocated to
will be relocated to 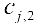 , and the cost of swapping will be defined as follows:
, and the cost of swapping will be defined as follows:

- Case 2: The second difference case is ,
 .
After swapping, will be relocated to
.
After swapping, will be relocated to  , and the cost of swapping is defined as follows:
, and the cost of swapping is defined as follows:

- Case 3: Here,
 and
and  . After swapping, the cost of swapping is defined as follows:
. After swapping, the cost of swapping is defined as follows:
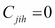
- Case 4: Here,
 and
and  . After swapping, will be relocated to, and the cost of swapping is defined as follows:
. After swapping, will be relocated to, and the cost of swapping is defined as follows:

At the end of each swapping step, the total cost of swapping is defined as follows:
The PAM (Partitioning Around Medoids) algorithm is a partitional clustering algorithm. The summarized pseudocode for the PAM algorithm is as follows:

Take a look at the ch_05_kmedoids.R R code file from the bundle of R code for the previous algorithms. The code can be tested with the following command:
> source("ch_05_kmedoids.R")
Along with the increase in the size and quantity of documents on the Internet, the efficient algorithms are always in urgent need to get usable summarization or distill the key information. The documents will in versatile formats, structured or unstructured. The tasks include summarization of a single document or multiple documents. More extended target to extract summarization from multimedia files. Other challenges include summarizing multilingual documents. Abstraction requires the tool support from KNLP for grammar and lexicons for analyses and generation. One possible process for the abstraction is illustrated as follows:

Many approaches are suggested for automatic abstraction of document text, such as automatic extraction, automatic abstraction based on understanding, information extraction, and automatic abstraction based on structures. Possible features to be adapted to design the summarization system include the sentence length cutoff, fixed-phrase, paragraph, thematic word, and uppercase word features.
Abstraction or summarization popularly has been defined as a process with two steps. An intermediate representation of some sort is retrieved by the extraction of important concepts from the source texts. Given the intermediate representation, the summary is generated.
For the first step of the summarization process, it can largely be treated as part of automatic indexing. Lexical chains to extract important concepts from a document are one possible solution. Lexical chains exploit the cohesion among an arbitrary number of related words, and they are calculated by grouping (chaining) sets of words that are semantically related.