
Hierarchical clustering divides the target dataset into multilevels or a hierarchy of clusters. It segments data points along with successive partitions.
There are two strategies for hierarchical clustering. Agglomerative clustering starts with each data object in the input dataset as a cluster, and then in the following steps, clusters are merged according to certain similarity measures that end in only one cluster. Divisive clustering, in contrast, starts with one cluster with all the data objects in the input dataset as members, and then, the cluster splits according to certain similarity measures in the following steps, and at the end, singleton clusters of individual data objects are left.
The characteristics of hierarchical clustering methods are as follows:
- Multilevel decomposition.
- The merges or splits cannot perform a rollback. The error in the algorithm that is introduced by merging or splitting cannot be corrected.
- The hybrid algorithm.

The BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies) algorithm is designed for large dynamic datasets and can also be applied to incremental and dynamic clustering. Only one pass of dataset is required, and this means that there is no need to read the whole dataset in advance.
CF-Tree
is a helper data structure that is used to store the summary of clusters, and it is also a representative of a cluster. Each node in the CF-Tree is declared as a list of entries, ![]() , and
, and B is the predefined entry limitation. ![]() denotes the link to the ith child.
denotes the link to the ith child.
Given ![]() as the representative of cluster i, is defined as
as the representative of cluster i, is defined as ![]() , where
, where ![]() is the member count of the cluster, LS is the linear sum of the member objects, and SS is the squared sum of the member objects.
is the member count of the cluster, LS is the linear sum of the member objects, and SS is the squared sum of the member objects.
The leave of the CF-Tree must conform to the diameter limitation. The diameter of the 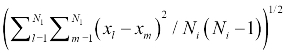 cluster must be less than the predefined threshold value, T.
cluster must be less than the predefined threshold value, T.
The main helper algorithms in BIRCH are CF-Tree insertion and CF-Tree rebuilding.
The summarized pseudocode for the BIRCH algorithm is as follows:
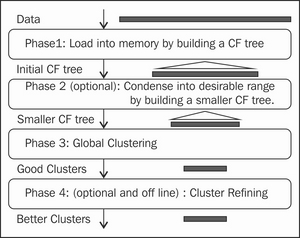
The overall framework for the chameleon algorithm is illustrated in the following diagram:
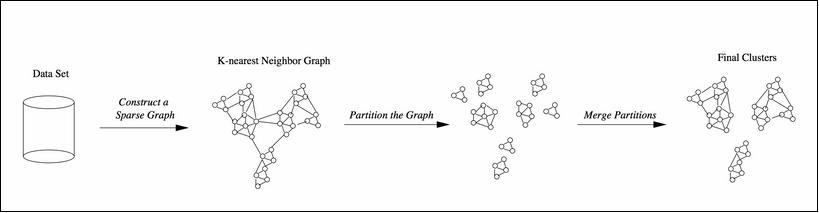
There are three main steps in the chameleon algorithm, which are as follows:
- Sparsification: This step is to generate a k-Nearest Neighbor graph, which is derived from a proximity graph.
- Graph partitioning: This step applies a multilevel graph-partitioning algorithm to partition the dataset. The initial graph is an all-inclusive graph or cluster. This then bisects the largest graph in each successive step, and finally, we get a group of roughly, equally-sized clusters (with high intrasimilarity). Each resulting cluster has a size not more than a predefined size, that is,
MIN_SIZE. - Agglomerative hierarchical clustering: This last step is where the clusters are merged based on self-similarity. The notion of self-similarity is defined with the RI and RC; they can be combined in various ways to be a measure of self-similarity.
Relative Closeness (RC), given the ![]() and
and ![]() clusters with sizes
clusters with sizes ![]() and
and ![]() , respectively.
, respectively. ![]() denotes the average weight of the edges that connect the two clusters.
denotes the average weight of the edges that connect the two clusters. ![]() denotes the average weight of the edges that bisect the
denotes the average weight of the edges that bisect the ![]() cluster:
cluster:
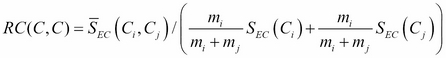
Relative Interconnectivity (RI) is defined in the following equation. Here, ![]() is the sum of the edges to connect the two clusters, and
is the sum of the edges to connect the two clusters, and ![]() is the minimum sum of the cut edges that bisect the
is the minimum sum of the cut edges that bisect the ![]() cluster:
cluster:
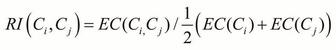
The summarized pseudocode for the chameleon algorithm is as follows:


The probabilistic hierarchical clustering algorithm is a hybrid of hierarchical clustering and probabilistic clustering algorithms. As a probabilistic clustering algorithm, it applies a completely probabilistic approach, as depicted here:

Take a look at the ch_05_ahclustering.R R code file from the bundle of R code for the previously mentioned algorithms. The codes can be tested with the following command:
> source("ch_05_ahclustering.R")
News portals provide visitors with tremendous news categorized with a predefined set of topics. With the exponential growth of information we receive from the Internet, clustering technologies are widely used for web documents categorization, which include online news. These are often news streams or news feeds.
One advantage of a clustering algorithm for this task is that there is no need for prior domain knowledge. News can be summarized by clustering news that covers specific events. Unsupervised clustering can also play a pivotal role in discovering the intrinsic topical structure of the existing text collections, while new categorization is used to classify the documents according to a predefined set of classes.
Services such as Google News are provided. For a story published by a couple of new agencies or even the same agency, there are often various versions that exist at the same time or span the same range of days. Here, clustering can help aggregate the news related to the same story, and the result is a better overview of the current story for visitors.
As preprocessing steps, plain texts are extracted from the web pages or news pages. Reuters-22173 and -21578 are two popular documents dataset used for research. The representation of a data instance in the dataset can either be classical term-document vectors or term-sentence vectors, as the dataset is a collection of documents, and the cosine-like measures are applied here.