
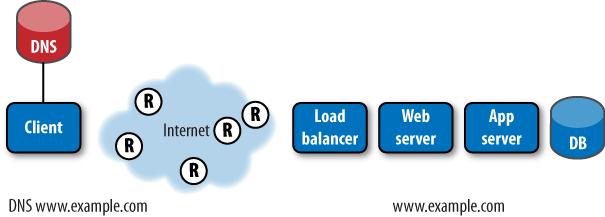
Getting a single object, such as an image, from a web server to a visitor’s browser is the work of many components that find, assemble, deliver, and present the content. They include:
A DNS server that transforms the URL of a website (www.example.com) into an Internet Protocol (IP) address (10.2.3.4).
Internet service providers (ISPs) that manage routes across the Internet.
Routers and switches between the client and the data center that forward packets.
A load balancer that insulates servers from the Web on many larger websites.
Servers and other web infrastructure that respond to requests for content. These include web servers that assemble content, application servers that handle dynamic content, and database servers that store, forward, and delete content.
That’s just for a single object. It gets more complicated for whole pages, and more so for visits.
When you type a URL into a browser, the browser first needs to find out the IP address of the website. It does this with the Domain Name Service (DNS) protocol, which ultimately resolves the name into one or more addresses and sends the address back to your browser, as shown in Figure 8-5.
You can run your own DNS lookups by typing nslookup and the domain name you want to
resolve at most command prompts. To launch a command prompt on a PC,
click Start→Run, then type command.com. On a Mac running OS X, click
the Spotlight icon in the top righthand corner of the screen (or press
Command-Space) and type Terminal,
then choose the Terminal application from the Applications list that
appears.
In the following example, the IP address for yahoo.com is provided by a DNS server (cns01.eastlink.ca) as 68.180.206.184.
macbook:~ alistair$ nslookup yahoo.com
Server: 24.222.0.94 (cns01.eastlink.ca)
Address: 24.222.0.94#53
Non-authoritative answer:
Name: yahoo.com
Address: 68.180.206.184Here’s what you need to know about DNS:
The DNS lookup happens when the visitor first visits your site. The client’s computer or his local ISP’s DNS server may keep a copy of the address it receives to avoid having to look it up repeatedly.
DNS can add to delay, particularly if your site is a mashup that has data from many places, since each new data source triggers another DNS query.
If DNS doesn’t work, users can’t get to your site unless they type in the IP address—in fact, asking them to type in the IP address directly is one way to see whether the problem is with DNS.
Note
Typing an IP address instead of a URL may not work either. If a web server is hosting multiple websites on one machine, the server needs to know which website users are looking for. Therefore, if a user requests a site using the server’s IP without including the hostname in the request, he won’t get the site he’s looking for.
There are many DNS servers involved in a lookup, so you may find that your site is available from some places and not others when a certain region or provider is having DNS issues.
Armed with the IP address of the destination site, your browser establishes a connection across the Internet using TCP, which is a protocol—a set of rules—designed to send data between two machines. TCP runs atop IP (Internet Protocol), which is the main protocol for the Internet. TCP and IP are two layers of protocols.
The concept of protocol layers is central to how the Internet functions. When the Internet was designed, its architects didn’t build a big set of rules for how everything should work. Instead, they built several simpler, smaller sets of rules. One set focuses on how to get traffic from one end of a wire to another. A second set focuses on how to address and deliver chunks of data, and another looks at how to stitch together those chunks into a “pipe” from one end of a network to another.
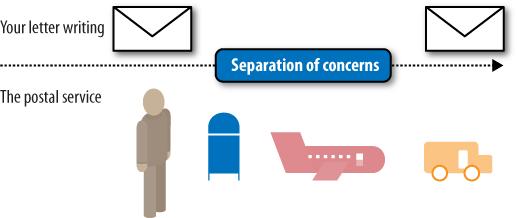
Here’s an analogy to help you understand the Web’s underlying protocols.
Think for a moment about the postal system—address an envelope properly, drop it in a mailbox, and it will come out the other end. You don’t need to worry about the trucks, planes, and mail carriers in between (Figure 8-6). Just follow the rules, and it’ll work as expected.
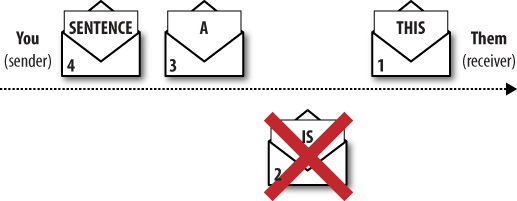
Now imagine trying to write a message to someone, but having to use a new envelope for each word, as shown in Figure 8-7.

It wouldn’t work. You’d have no control over the order in which the envelopes were delivered. If several envelopes arrived on the same day, or if they arrived out of order, the receiver wouldn’t know in what order to open them.
To resolve this issue, you and your reader would need to agree on some rules. Perhaps you’d say, “I’ll put a number on each envelope, and you can read them in the order they’re numbered,” (Figure 8-8).

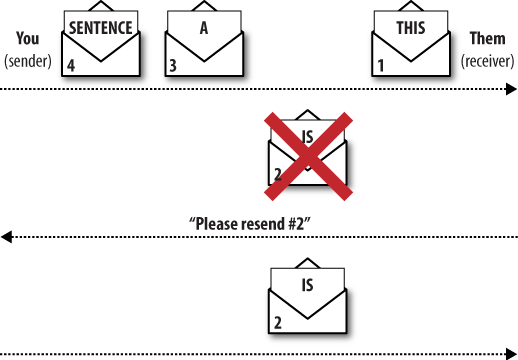
We still have a problem: what if a letter is lost? As Figure 8-9 shows, your reader, stuck at letter 1, would be waiting for lost letter 2 to show up while the remaining letters continue to arrive.
So you’d also need a rule that said, “If you get a lot of letters after a missing one, tell me, and I’ll resend the missing letter.” The conversation between sender and receiver looks more complex, as Figure 8-10 illustrates, but it’s also much more reliable.
You might even say, “Let me know when you’ve received my letters,” which would help you to understand how long they were taking to be delivered. If you didn’t get an acknowledgment of delivery for a particular letter, you could assume it was lost, and resend it.
A set of rules like the ones we’ve just defined makes up a protocol. Notice that you don’t need to concern yourself with how the postal service works in order to have your one-word-per-letter conversation. You don’t care whether the letters are delivered by car, plane, carrier pigeon, or unladen swallow. Similarly, the postal service isn’t concerned with the rules of your conversation. There is a separation of concerns between you and the postal service.
Put another way, your letter conversation is a “layer” of protocols, and the postal service is another “layer.” You have a small amount of agreed-upon interaction with the postal layer: if you address the letter properly, attach postage, and get it in a mailbox, they’ll deliver it.
In the same way, the Internet’s layers have a separation of concerns. IP is analogous to the postal service, delivering envelopes of data. For your computer to set up a one-to-one conversation with a server across IP, it needs a set of rules—and that’s TCP. It controls the transmission of data (that’s why it’s called the Transmission Control Protocol). The pattern of setting up a connection between two machines is so commonplace that we usually refer to it as the TCP/IP protocol stack. The connection between the two machines is the TCP session, shown in Figure 8-11.
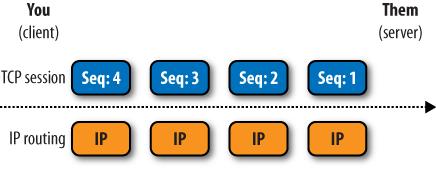
Figure 8-11. The combination of TCP and IP creates end-to-end sessions between a client and a server
The modern Internet is extremely reliable, but it still loses data from time to time. When it does, TCP detects the loss and resends what was lost. Just as your conversation with a friend would slow down briefly while you resent a lost envelope, so packet loss on the Internet increases delay.
Because IP doesn’t guarantee the order in which packets will be delivered—or even whether they’ll arrive at all—TCP manages things like the sequence of delivery, retransmission, and the rate of transmission.
TCP also allows us to time the network connection, since we can measure how much time elapses between when we send a particular packet and when the receiver acknowledges receipt. This comes in handy when we’re analyzing real user traffic and diagnosing problems.
You don’t need to understand TCP in detail, but you should know the following:
TCP creates an end-to-end connection between your browser and a server.
If the network loses data, TCP will fix it, but the network will be slower.
TCP uses a fraction of the available bandwidth to handle things like sequence numbers, sacrificing some efficiency for the sake of reliability.
TCP makes it possible to measure network latency by analyzing the time between when you send a packet and when the recipient acknowledges it. This is what allows network monitoring equipment to report on end user experience.
By hiding the network’s complexity, TCP makes it easy for the builders of the Internet to create browsers, web servers, and other online applications we use today.
A modern computer may have many TCP connections active at once. You may have an email client, a web browser, and a shared drive. All of them use TCP. In fact, when you surf several websites, you have TCP connections to each of them. And those sites have TCP connections to thousands of visitors’ computers. To keep track of all these connections, TCP gives each of these sockets, or TCP ports, numbers.
For the really common applications, such as the Web, email, and file sharing, the Internet community has agreed on standard numbers. The Web is usually port 80, and encrypted web connections are usually port 443. However, you can connect to any port number on which a web server is running and ask it for content, so sometimes the web port is 8080, or 8000; it varies.
Four things uniquely identify a TCP session: the client and server IP addresses, and the TCP port numbers being used. In Figure 8-12, the TCP session to Yahoo.com is identified as 24.138.72.1:2039 to 68.180.206.184:80. No other pair of computers on the Internet has that same combination of addresses and ports at that time.
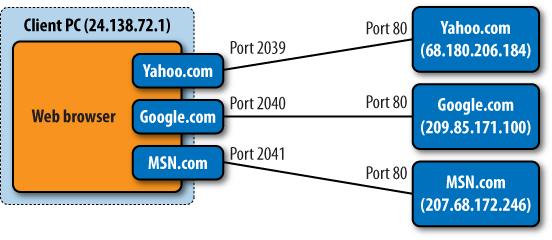
Your browser knows the IP address to which it wants to connect. And it knows it wants to connect to port 80 on the server because it wants to access that server’s web content. The TCP layer establishes a session between the client running the browser and port 80 on the server whose IP it received from the initial DNS lookup. After a brief exchange of information known as a three-way handshake, there’s a TCP session in place. Anything your browser puts into this session will come out at the other end, and vice versa.
You can try this out yourself. Open a command prompt and type the “telnet” command, followed by the domain name of a website and the port number, as follows:
macbook:~ alistair$ telnet www.bitcurrent.com 80You’ll see a message saying you’re connected to the server, and the server will wait for your request.
Trying 67.205.65.12... Connected to bitcurrent.com. Escape character is '^]'.
You can request the home page of the site by typing GET, followed bya forward slash signifying the root of the site:
GET /If everything’s working properly, you’ll see a flurry of HTML come back. This is the container object for the home page of the site, and it’s what a browser starts with to display a web page.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"> <html xmlns="http://www.w3.org/1999/xhtml"> <head profile="http://gmpg.org/xfn/11"> <script type="text/javascript" src="http://www.bitcurrent.com/ wp-content/themes/grid_focus_public/js/perftracker.js"></script> <script>
After a while, you’ll see the end of the HTML for the page, followed by a message showing that the connection has been closed.
</body> </html> Connection closed by foreign host.
In theory, you could surf the Web this way, but it wouldn’t be much fun. Fortunately, browsers hide all of this complexity from end users.
There’s one more thing to consider before your browser starts requesting web pages. If what you’re about to send is confidential, you may want to encrypt it. If you request a page from a secure website (prefixed by https://), your browser and the server will use a protocol called the Secure Sockets Layer (SSL) to encrypt the link.
Again, you don’t need to understand SSL. Here’s what you do need to know:
It makes the rest of your message impossible to read, which can make it harder for you to troubleshoot problems with a sniffer or to deploy inline collection for analytics.
The server has to do some work setting up the connection and encrypting traffic, both of which consume server resources.
SSL doesn’t just secure the link, it also proves that the server is what it claims to be, because it holds a certificate that has been verified by a trusted third party.
The browser may not cache some encrypted content, making pages load more slowly as the same object is retrieved with every page.
It makes the little yellow padlock come on.
Now you’re finally ready to retrieve and interpret some web content using HTTP. Just as IP handles the routing of chunks of data and TCP simulates a connection between two computers, so HTTP focuses on requesting and retrieving objects from a server. The individual layers of communication are shown in Figure 8-13.
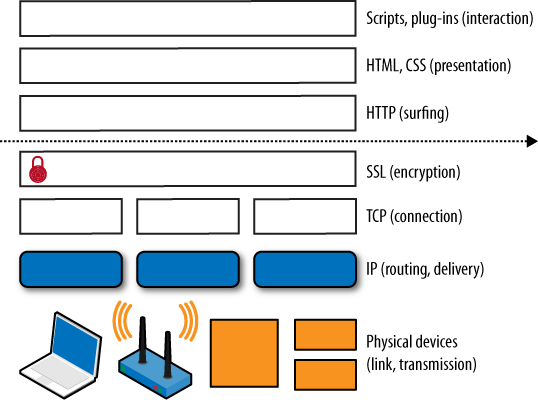
Your browser retrieves pages through a series of simple requests
and responses. The browser asks for an object (index.html) by name. The server replies that
yes, in fact, it has this object (200 OK) and sends it.
There’s an important caveat here. In many cases, your browser may have already visited the website in question. Much of the content on a web page doesn’t change that often. Menu bars, images, videos, and layout information are only modified occasionally. If your browser had to download every object every time it visited a site, not only would your bandwidth bill be higher, but the pages would also load more slowly. So before asking the server for an object, your browser checks to see if it has a copy in memory on your PC. If it does—and if the copy isn’t stale—it won’t bother asking for it. We’ll look at caching in more detail shortly.
There are seven standard HTTP commands, called methods, that a browser can send to a server. Of these, only three are commonly used on most sites:
Other commands, such as PUT, TRACE, OPTIONS, and DELETE, were seldom used until recently, but PUT and DELETE have newfound popularity in Ajax-based websites.
Your browser also tells the server things about itself, such as what kind of browser it is, whether it can accept compressed documents, which kinds of objects it can display, and which language the visitor speaks. The server can use some of this information to respond in the best way possible, for example, with a page specifically designed for Internet Explorer or one written in the visitor’s native language.
The request to the server can be as simple as GET page.html, but it’s common for a browser
to send additional information to the server along with the request.
This information can come in several formats. Common ones are:
- Cookies
This is a string of characters that the server gave to the browser on a previous visit. This allows the server to recognize you, so it can personalize content or welcome you back.
- Information in the URL structure itself
A request for www.example.com/user=bob/index.html, for example, will pass the username “bob” to the server.
- A URI query parameter
URI query parameters follow a “?” in the URL. For example, an HTTP request for http://www.youtube.com/watch?v=Yu_moia-oVI&fmt=22 contains two parameters. The first is the video number (v=Yu_moia-oVI) and the second is the format (fmt=22, for high definition).
Remember that we said your browser only uses a cached copy of content if it’s not stale? Your browser will check to see if it has a fresh copy of content, and then retrieve objects only if they’re more recent than the ones stored locally. This is called a conditional GET request: the server only sends an object if the one it has is more recent than the one the browser has, which saves on bandwidth without forcing you to see old content.
This is one of the reasons why, when testing site performance, you need to specify whether the test should simulate a first-time or a returning user. If a browser already has much of the content, performance will be much better because the browser already has a copy of many parts of the page.
If everything is running smoothly, the server will respond with an HTTP status code.
HTTP/1.0 200 OK
This is a quick message to acknowledge the request and tell the client what to expect. Status codes fall into four groups:

The 200 group indicates everything is fine and the response will follow.
The 300 group means “go look elsewhere.” This is known as a redirect, and it can happen temporarily or permanently. It’s used to distribute load across servers and data centers, or to send visitors to a location where the data they need is available. Instead of responding with a “200 OK” message, the server sends back a redirection to another web server.
The 400 group indicates client errors. The client may have asked for something that doesn’t exist, or the client may not have the correct permissions to see the object it has requested. While you might think that 400 errors are a visitor’s problem, they can be the result of broken links you need to fix. Figure 8-14 shows an example of a 404 apology page.
The 500 group indicates server errors. These are serious issues that can occur because of application logic, broken backend systems, and so on. Sometimes these errors can produce custom pages to inform visitors of the problem or to reassure them that something is being done to fix the issue, as shown in Figure 8-15.
Just before it sends the object, the server gives us some details about the object the browser is about to receive. This can include:
The size of the object
When it was last modified (which is essential to know in order to cache objects efficiently)
The type of content—a picture, a stylesheet, or a movie, and so on—so your browser knows how to display it
The server that’s sending the answer
Whether it’s OK to cache the object, and for how long to use it without checking for a fresh object from the server
A cookie the client can use in subsequent requests to remind the server who it is
Any compression that’s used to reduce the size of the object
Other data, such as the privacy policy (P3P) of the site
Here’s an example of metadata following an HTTP 200 OK response:
HTTP/1.x 200 OK Date: Mon, 13 Oct 2008 04:31:29 GMT Server: Apache/2.2.4 (Unix) mod_ssl/2.2.4 OpenSSL/0.9.7e Vary: Host Last-Modified: Wed, 13 Jun 2007 19:15:36 GMT Etag: "e36-70534600" Accept-Ranges: bytes Content-Length: 3638 Keep-Alive: timeout=5, max=100 Connection: Keep-Alive Content-Type: image/x-icon P3P: policyref="http://p3p.yahoo.com/w3c/p3p.xml", CP="CAO DSP COR CUR ADM DEV TAI PSA PSD IVAi IVDi CONi TELo OTPi OUR DELi SAMi OTRi UNRi PUBi IND PHY ONL UNI PUR FIN COM NAV INT DEM CNT STA POL HEA PRE GOV"
Each line is a response header. Following the headers, the server provides the object the client requested. One of the reasons for HTTP’s widespread success is the flexibility this affords: the server may provide many headers that your browser simply ignores. This has allowed browser developers and server vendors to innovate independently of one another, rather than having to release browsers and servers at the same time.
Now the server has to send the object your browser requested. This may be something stored in the server’s memory, in which case it’s a relatively simple matter of retrieving it and stuffing it into the existing TCP session. Your browser will do the rest.
On most modern sites, the web page contains some amount of dynamic content. This means the server has to think about the answer a bit. This server-side processing—what we’ll refer to here as host time—is a major source of poor performance. Assembling a single object may require the web server to talk to other servers and databases, and then combine everything into a single object for the user.
Once the object is prepared, the server sends it to your browser.
The other major source of poor performance comes from network latency (what we’ll refer to as network time). From the moment the server puts the object into the TCP connection until the moment the last byte of that object comes out at the other end, the clock is ticking. Large objects take longer to send; if anything’s lost along the way, or if the sender and receiver are far apart, they’ll take longer still.
Your browser receives the object. If the request was for a standalone object, that would be the end of it: your browser would shut down the TCP connection through a sequence of special TCP messages, and you’d be able to access the received object (i.e., the web page).
Pages contain many things, such as pictures, video, and Flash, as well as formatting information (stylesheets) and programming logic (JavaScript). So your browser now has to finish the job by retrieving the components of the container object it received.
Modern browsers are eager to display pages quickly. Your browser doesn’t even wait for the container object to load completely—as it’s flowing in, the browser is greedily analyzing it to find references to other objects it needs to retrieve. Once it sees additional objects listed in that page, it can go ahead and request them from the server, too. It can also start executing any JavaScript that’s on the page and launching plug-ins, such as Java, ActiveX, or Flash, that it will need to display content.
With the client and server communicating so much, it would be a waste to tear down that TCP session just to reestablish it. Version 0.9 of HTTP initially behaved in this way. If your browser needed more objects (and it usually does), it had to reconnect to the server. Not only was this slow, it also kept the servers busy setting up and tearing down connections. The Internet’s standards body moved quickly to correct this.
In version 1.1 of the HTTP protocol, the TCP connection is kept alive in anticipation of additional requests. Figure 8-16 shows this process.
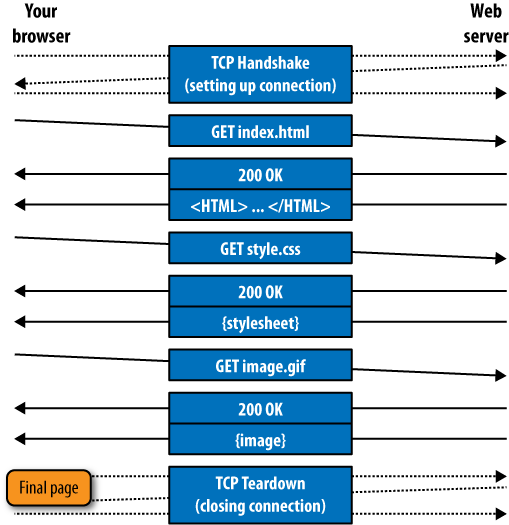
The examples we’ve seen so far are serial—that is, the browser and the web server are requesting and sending one object at a time. In reality, web transactions run in parallel. Here’s why: if you’re on a one-lane road, it’s hard to overtake someone. Add a second lane, and suddenly traffic flows freely. The same thing is true with network connections. A single TCP session means that a really big object can stop smaller objects from getting through quickly. This is known as head-of-line blocking, and is similar to a single slow truck delaying dozens of faster cars.
Figure 8-17. The About:config panel in Firefox, showing connection properties that users can adjust to change connection parallelism
Web browsers resolve this issue by establishing multiple TCP sessions to each server. By having two or more sessions open, the client can retrieve several objects concurrently. Some browsers, such as Firefox, let users configure many of these properties themselves, as shown in Figure 8-17. For more information about parallelization and pipelining, see Mozilla’s FAQ entry at www.mozilla.org/projects/netlib/http/pipelining-faq.html.
TCP parallelism makes browsers work better, but it also makes
your job of measuring things more difficult. Because many HTTP
transactions are occurring simultaneously, it’s harder to estimate
performance. Many web operations tools use
cascade diagrams like the one in Figure 8-18 to illustrate the
performance of a test or a page request. Notice that several objects
(script.js and style.css, for example) are being retrieved
simultaneously.

Early browsers simply displayed what they received. With the introduction of JavaScript in 1993, developers started to embed simple programs within the container page. Initially, they focused on making pages more dynamic with functions such as rollover images, but these quickly grew into highly interactive web pages.
Since then, JavaScript has become a powerful programming language in its own right. Interactive sites like Google Maps rely heavily on browser scripting to make their applications run quickly on the client.
At the time a page is loaded, the browser interprets the portions that are written in JavaScript. Because this may involve rewriting portions of the page that were just loaded, JavasScript needs to run first. That’s right: a page can contain a program that actually modifies the page itself.
Once your browser has the page and enough information about the objects it contains, it can display them to the user. Note that the browser doesn’t need all the objects on the page to show you the page—if your browser knows how big an image will be, it can begin displaying the page, leaving a space where the image will go. Including image sizes within the container page means the browser can show you the page sooner.
There are several important milestones in the loading of a page, and these are the things you’ll be monitoring with synthetic and RUM tools. They don’t always happen in this order, and their order depends on how a particular site was built.
- Initial action
This is the action that started it all—either typing in a URL or clicking on a link. It’s the basis for all page measurement.
- Initial DNS response time
If the browser is visiting a site for the first time, there must be a DNS lookup.
- SSL negotiation
If the page is encrypted, the browser and server need to set up the encrypted SSL channel before transmitting data.
- Container first byte
This is when the start of the container object reaches the browser. The time from the initial action to the first byte of the container can serve as a rough estimate of how much time the server took to process the request.
- Component objects requested
At this point, the browser knows enough to start asking for embedded elements, stylesheets, and JavaScript from the server.
- Component first byte
This is when the start of the component reaches the browser.
- Third-party content DNS lookups
If any of those component objects come from other sites or subdomains, the browser may have to look them up, too.
- Start processing instructions
This is when the browser starts interpreting JavaScript, possibly triggering other retrievals or page modification. This may block other page activity until the scripts are finished.
- Page starts rendering
This is the point at which the browser has rendered the page sufficiently for a user to start interacting with it. This is the critical milestone that governs end user experience.
- All objects loaded
Some objects, such as those below the viewable screen, may continue to load even after the user starts interacting with the page.
- Entire page loaded, including backup resources
To improve usability, scripts on the page may intentionally fetch some data after the page is completed.
- In-page retrieval (type-ahead search, etc.)
Many applications may retrieve additional components in response to user interactions. Microsoft’s Live Maps, for example, retrieves new map tiles as users scroll.
Few visits last for a single page. Each user action may trigger another page load, with a few differences from what happened when the initial page was loaded:
- DNS lookups are unnecessary
You shouldn’t need to look up the IP address again through DNS.
- Some content will be in the local cache
There will hopefully be plenty of up-to-date content in the local cache, so there will be less to retrieve.
- New cookies to send
The browser may have new cookies to send this time around, particularly if this was the first time the user visited the site.