
Writing software, in general, and making games, in particular, is a hard endeavor, which is why we should avoid unnecessary complications whenever we can using tools that will save us from despair. There are so many things that can go wrong during development; luckily for us, we can use source control as the first step to a better night's sleep.
What if your hard drive breaks, bursts in flames, or gets stolen? Yes, the right answer is continuous backups, tons of them, and then some more! Surely, online cloud storage services such as Dropbox or Google Drive provide this for you out of the box. They even let you share folders with others, which might lure you into thinking that it is a good way of working as a team, but it just stops cutting it the second things go a bit beyond trivial.
What if you come back home on a Saturday night after too many drinks and decide it is a great time to get some coding done? After all, you feel incredibly inspired! What follows is that you will wake up the next morning in sweat, tears and full of regret. Surely, Dropbox lets you revert changes on a per-file basis, but a lot of fiddling is required when the changes are spread across multiple systems, and you risk worsening things even more.
Finally, what if two members in your team make changes to the same file? Conflict solving in Dropbox is flaky at best; you will most likely enter the realms of hell in these cases. Manually merge two files every time this happens, and believe me, it will happen constantly, but this is not something you will enjoy.
Any good source control system gracefully solves each one of these little nightmares for you. A repository keeps track of every important file, and every time you make a set of changes, it is dead easy to create a new revision or snapshot of the whole project tree. These changes can be shared with your team members, and there is no problem in going back a few revisions whenever you realize a mistake has been made. Most source control systems also provide very intelligent mechanisms to merge files several people have modified.
After this little rant, it is time to proceed with the recipe. We will use Git to put only the essential files of our Libgdx project under source control, and in this way sleep a lot better at night. Keep in mind that the intent is neither to provide a detailed guide on how revision control works nor how to fully understand Git, but just the bare minimum to get you started.
Note
Why Git? Well, according to Linus Torvalds, if you do not use Git, you are ugly. For those who don't know him, Linus Torvalds is the father of both the Linux kernel and Git revision control system. He does not have a huge appreciation towards alternatives such as CVS or SVN. Check Linus' talk, as it is very interesting, at http://www.youtube.com/watch?v=4XpnKHJAok8.
First, you need to install the Git client on your computer, which was originally conceived as a command-line tool by Linus Torvalds. However, nowadays we have visual clients at our disposal, which make life much easier. On both Windows and Mac, I will personally recommend SourceTree because it is quite intuitive and has everything you are likely to need at hand. However, there are alternatives such as Tortoise Git. Both are free, and the latter is also completely open source. SourceTree's installer can be found on its official site at http://sourcetreeapp.com.
The package installation process varies across GNU/Linux distributions. In Debian-based distributions (most common ones), users can install the Git client using the command-line and apt-get:
sudo apt-get install git
This is a program capture; the cropped text is not relevant
Every time you start a project, the first step should be to create a repository to keep track of everything that goes on with it. Services such as GitHub, Gitorious, and Google Code offer free repositories but require you to disclose the source. However, GitHub also allows you to create paid private repositories. Bitbucket is a competitive alternative if you seek a private repository at no cost. Last but not least, you can always host your own Git server at home, but then you will have to deal with problems such as backups, availability from the outside, and so on. Perform the following steps:
- Choose your poison, and create an account and a repository to start with, such as:
- GitHub, available at http://github.com
- Gitorious, available at http://gitorious.org
- Google Code, available at http://code.google.com
- Bitbucket, available at http://bitbucket.org
- The next step will be to clone your newly created repository so as to have a local copy to work with.
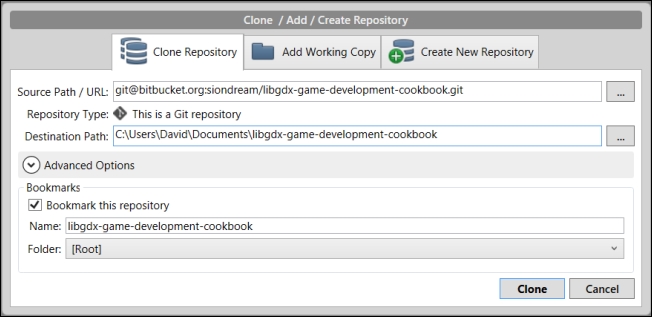
- From SourceTree, click on Clone/New, select the Clone Repository tab, and enter the URL you received from the service of your choice.
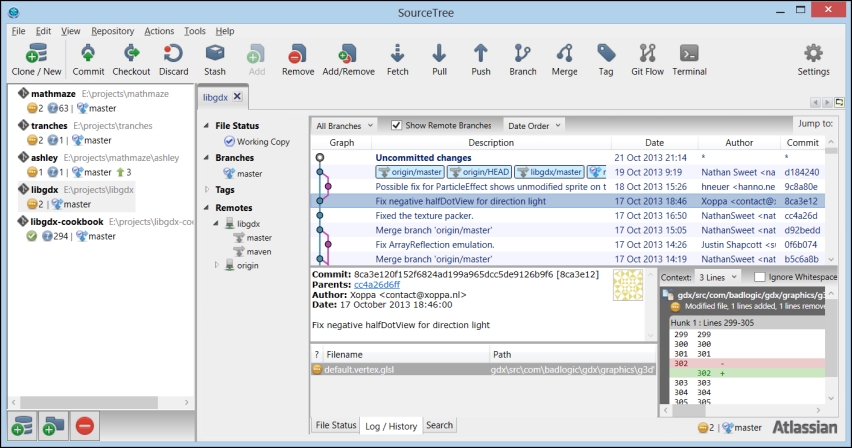
- After entering the destination path, you can simply click on Clone, and the empty repository will be available on the leftmost panel, as shown in the following screenshot:
- GNU/Linux users can get away with the following command:
git clone <REPO-URL> <DESTINATION-FOLDER> - Have you already started working on your awesome game? Then, what you need to do is clone your brand new repository into an empty folder and pour all the project files there. Git requires an empty folder to either create or clone a repository.
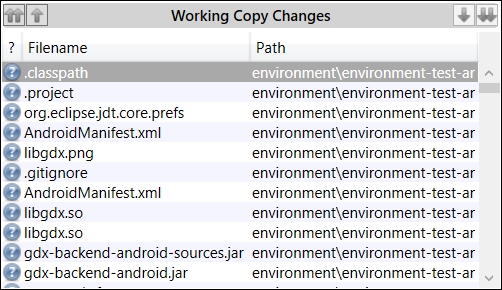
- With your repository selected on SourceTree, click on Working Copy and take a close look at the Working Copy Changes panel; there will be tons of files that are not under source control asking you to include them, as shown in the following screenshot:
- The list of candidates for addition, deletion, and modified files can also be queried from the following command line:
git status
We do not need all this nonsense! If you already compiled something, there will be tons of clutter that will certainly become a huge waste of cloud storage. Though this comes cheap these days, it will be painful to upload and download changes further down the line. Ideally, we only want to keep track of whatever is absolutely necessary for someone to download a snapshot from the other end of the world and be able to continue working normally.
Luckily enough, we can get rid of all the noise from git status and the Working Copy Changes panel by creating a .gitignore text file in the root folder of the repository with the following content:
bin/ target/ obj/ .gwt/ gwt-unitCache/ war/ gen/ *.class
It is time to add the .gitignore file to our repository. Perform the following steps:
- From the Working Copy Changes panel, right-click on the file and select Add to Index.
- Then, click on Commit, add a meaningful message such as
Adds .gitignore file to make repository management easier, and finish by clicking on the Commit button on the modal window, as shown in the following screenshot: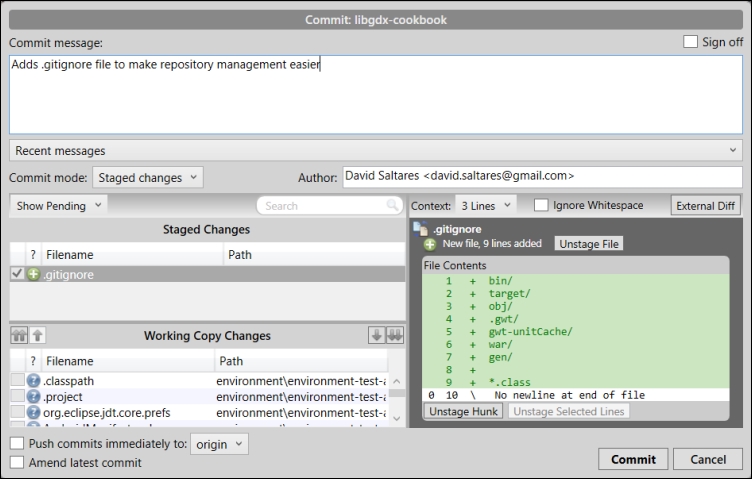
- On the command line, it looks something like this:
git add .gitignore git commit –m "Adds .gitignore file to make repository management easier"
- Now, you can safely proceed to add every remaining file and commit again. From GUI, follow the same process as with the
.gitignorefile. However, if you are a command-line lover, you can stage and commit all the files at once like this:git add * git commit –m "Adds project basic files"
Congratulations! Git is now keeping track of your project locally. Whenever you make changes, you simply need to add them again to the set of files about to be committed, and actually commit them. Obviously, you can achieve this with both the visual and command-line variants of the client.
Note
Writing meaningful commit messages might seem unimportant, but nothing is further away from the truth. Whenever you examine the history in search for the origin of a bug, you will want all the help you can get to understand what the person who made each commit was trying to do at that point in time.
It is time to push all the commits you have made from your local repository to the remote repository hosted by the provider of your choice. This is the way your teammates, and potentially the whole world in case the repository is public, will be granted access to the changes. Perform the following steps:
- From SourceTree, click on Push and select the origin and destiny branches; typically, both will be named master. Once you are ready, click on OK and wait for the operation to finish, as shown in the following screenshot:
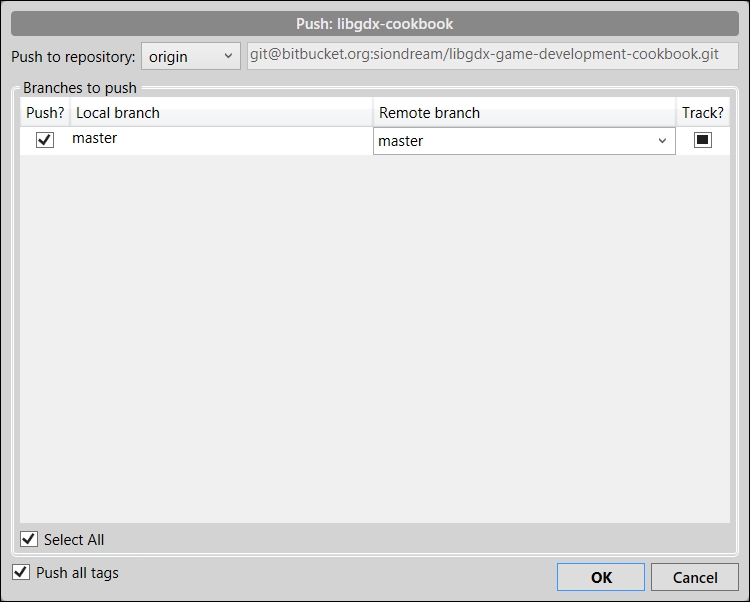
- Here is the command-line version of the same song:
git push origin masterLet's imagine that our game developer buddies have been sweating blood to add new shiny features. Naturally, you are eager to check what they have been up to and help them out. Assuming they pushed their changes to origin, you now need to pull every new commit and merge them with your working branch. Fortunately, Git will magically and gracefully take care of most conflicts. Perform the following steps:
- From SourceTree, you need to click on the Pull button and select the remote repository and branch you are pulling from. For a simplistic approach, these will be
originandmaster. Once you are ready, click on the OK button, as shown in the following screenshot, and sit back and enjoy: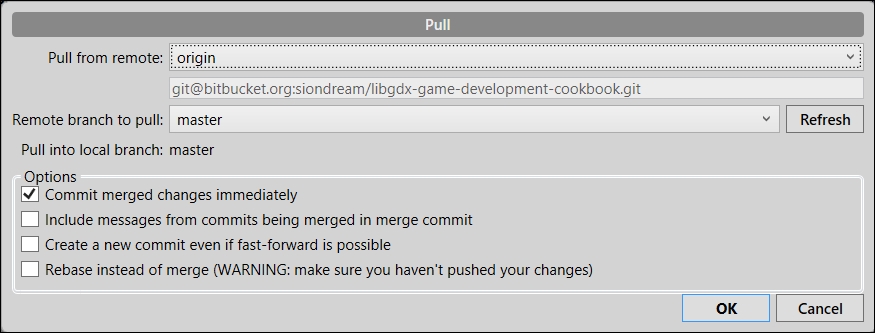
- A pull operation can also be triggered from the command line:
git pull origin
Git is a distributed revision control system. This means that, in principle, there is no central repository everyone commits to. Instead, developers have their own local repository containing the full history of the project.
The way Git keeps track of your files is quite special. A complete snapshot of all the files within the repository is kept per version. Every time you commit a change, Git takes a brand new picture and stores it. Thankfully, Git is smart enough to not store a file twice, unless it changes from one version to another. Rather, it simply links the versions together. You can observe this process in the following diagram:
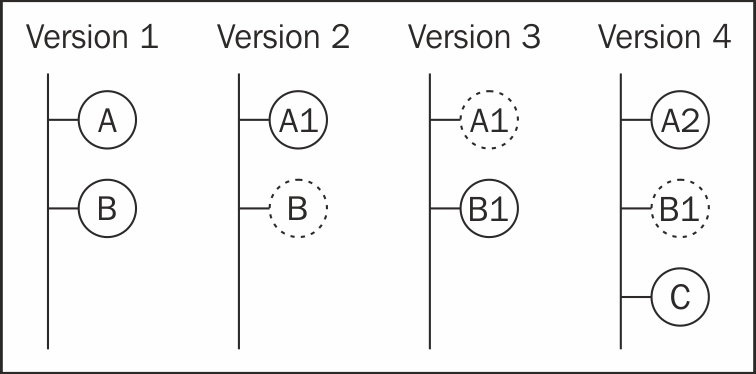
As per the previous diagram, Version 1 has two files, A and B. Then, a commit is made updating A, so Git stores the new file and creates a link to B because it has not changed. The next commit modifies B, so Version 3 stores this file and a link to the unchanged revision of A. Finally, Version 4 contains modifications to A, a link to B (unchanged), and the first revision of the newly created file C.
Most times you work with Git, you will operate locally because your repository contains everything that you need. It lets you check the full history, commit, and revert changes, among many others. This makes Git lightning fast and very versatile as it does not attach you to any Internet connection.
The typical usage of Git is as follows:
- Clone a remote repository and make it locally available with
git clone - Modify, add, or remove files
- Add files to the staging area for them to be committed to your local repository with
git add - Commit the files and create a new version within your local repository using
git commit - Receive changes from a remote repository with
git pull - Send your local changes to a remote repository with
git push
Though we didn't use them, the way to experience Git's true glory is through branching and merging. You can think of the history of your repository as a series of directory-tree snapshots linked together. A commit is a small object that points to the corresponding snapshot and contains information about its ancestors. The first commit will not have a parentand subsequent commits will have a parent, but when a commit is the result of merging several changes together, it will have several parents.
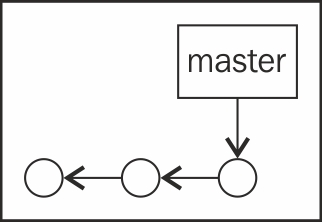
A branch is simply a movable pointer to one of these commits; you already know master, the default branch. The way we have been working, master will point to the last commit you made, as shown in the following diagram:
Branching in Git has a minimal overhead as the only thing it does is create a new pointer to a certain commit. In the following diagram, we create a new branch called test:
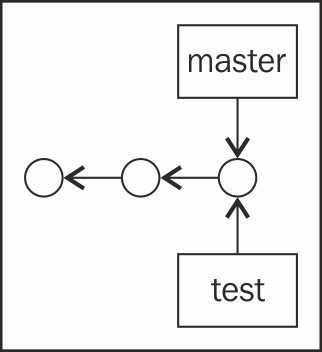
We can work on test for a while, go back to master, and then work on something different. Our repository will look something like this:
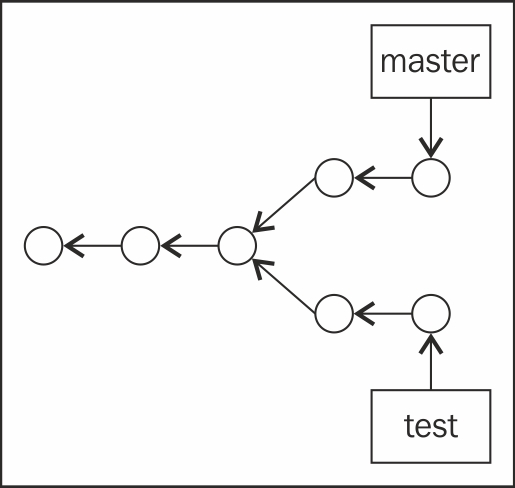
Someone in the team decides it is time to bring the awesome changes made on test over to master; it is now merging time! A new commit object is created, with the last commits from master and test as parents. Finally, the master branch pointer moves forward so that it points to the new commit. Easy as pie!
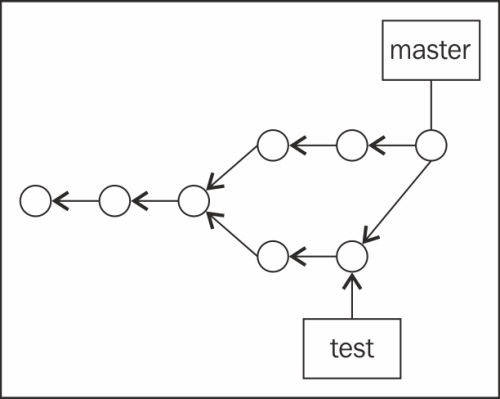
As we mentioned, this is not intended to be a comprehensive guide on Git but a mere introduction instead. If you are dying out of curiosity, I will wholeheartedly recommend Pro Git, which is freely available online under a Creative Commons license at http://git-scm.com/book.
The .gitignore file we created earlier contains a list of rules that tell Git which files we are not interested in. Files under this branch of the directory tree that match the patterns and are not committed to the repository just yet, will not appear as candidates when running git status on the Source Tree Working Copy Changes panel.
Typically, you will want to ignore specific files, that is, every file with a specific extension or anything that is under a certain folder. The syntax for these, in the same order, is quite simple:
/game/doc/doc.pdf *.jar /game/game-core/bin
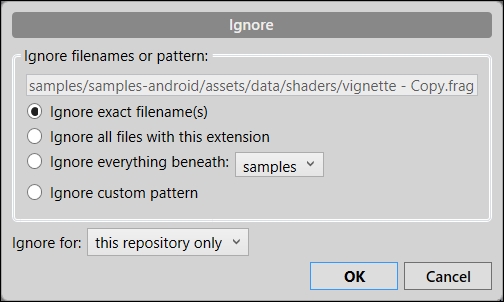
SourceTree lets us add files and paths to .gitignore very easily. Select the file you want to add to the ignore list from the Working Copy Changes panel, and right-click and select Ignore. A new modal window will appear giving you the options to ignore just this file, all the files with this extension, or everything placed under a certain folder from the file's path. Once you select the option you want, click on OK, as shown in the following screenshot:
This recipe was aimed at covering the very basics of the relationship between Libgdx and revision control systems. If you are interested in broadening your knowledge on the matter, read on.
Regardless of what Linus Torvalds might tell you, Git is not the only revision control system out in the wild, and it might not be the best fit in your case. The following are other alternatives:
- Mercurial: This is cross-platform, open source, and completely distributed, just like Git. It is available at http://mercurial.selenic.com.
- Subversion: This is also cross-platform and open source, but it's a centralized system. It is usually perceived as easier to learn than Git and works for most projects. However, it is much less flexible. It is available at
subversion.trigris.org. - Perforce: This is a proprietary centralized system, but free for up to 20 users. It is widely used in the games industry for its binary file management. It is available at http://perforce.com.
Pro Git is a freely available book on how to master the version control system. It is available at http://git-scm.com/book.
The Libgdx community is built around Git and hosted on GitHub. The following recipes are highly related to this revision control system:
- The Working from sources recipe in Chapter 13, Giving Back
- The Sending a pull request on GitHub recipe in Chapter 13, Giving Back