
Classification algorithms are a type of machine learning algorithm that involve determining the class (category or type) of a given item. For instance, we could try to determine the genre of a movie based on some features. In this case, the genre is the class to be predicted. In the next chapter, Chapter 10, Predictive Analytics and Machine Learning, we will continue with an overview of machine learning. In the meantime, we will discuss a popular algorithm called Naive Bayes classification, which is frequently used to analyze text documents.
Naive Bayes classification is a probabilistic algorithm based on the Bayes theorem from probability theory and statistics. The Bayes theorem formulates how to discount the probability of an event based on new evidence. For example, imagine that we have a bag with pieces of chocolate and other items we can't see. We will call the probability of drawing a piece of dark chocolate P(D). We will denote the probability of drawing a piece of chocolate as P(C). Of course, the total probability is always 1, so P(D) and P(C) can be at most 1. The Bayes theorem states that the posterior probability is proportional to the prior probability times likelihood:
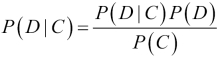
P(D|C) in the preceding notation means the probability of event D given C. When we haven't drawn any items yet, P(D) = 0.5 because we don't have any information yet. To actually apply the formula, we need to know P(C|D) and P(C) or we have to determine those indirectly.
Naive Bayes Classification is called naive because it makes the simplifying assumption of independence between features. In practice, the results are usually pretty good, so this assumption is often warranted to a certain level. Recently, it was found that there are theoretical reasons why the assumption makes sense. However, since machine learning is a rapidly evolving field, algorithms have been invented with (slightly) better performance.
Let's try to classify words as stopwords or punctuation. As a feature, we will use the word length, since stopwords and punctuation tend to be short.
This setup leads us to define the following functions:
def word_features(word):
return {'len': len(word)}
def isStopword(word):
return word in sw or word in punctuationLabel the words in the Gutenberg shakespeare-caesar.txt as being a stopword or not:
labeled_words = ([(word.lower(), isStopword(word.lower())) for word in words]) random.seed(42) random.shuffle(labeled_words) print labeled_words[:5]
Five labeled words will appear as follows:
[('was', True), ('greeke', False), ('cause', False), ('but', True), ('house', False)]
For each word, determine its length:
featuresets = [(word_features(n), word) for (n, word) in labeled_words]
In previous chapters, we mentioned overfitting and how to avoid this with cross-validation by having a train and a test dataset. We will train a Naive Bayes classifier on 90 percent of the words and test on the remaining 10 percent. Create the train set and test set and train the data:
cutoff = int(.9 * len(featuresets)) train_set, test_set = featuresets[:cutoff], featuresets[cutoff:] classifier = nltk.NaiveBayesClassifier.train(train_set)
We can now check what the classifier gives for some words:
classifier = nltk.NaiveBayesClassifier.train(train_set)
print "'behold' class", classifier.classify(word_features('behold'))
print "'the' class", classifier.classify(word_features('the'))Fortunately, the words are properly classified:
'behold' class False 'the' class True
Determine the classifier accuracy on the test set as follows:
print "Accuracy", nltk.classify.accuracy(classifier, test_set)
We get a high accuracy for this classifier of around 85 percent. Print an overview of the most informative features:
print classifier.show_most_informative_features(5)
The overview shows the word lengths that are most useful for the classification process:

The code is in the naive_classification.py file in this book's code bundle:
import nltk
import string
import random
sw = set(nltk.corpus.stopwords.words('english'))
punctuation = set(string.punctuation)
def word_features(word):
return {'len': len(word)}
def isStopword(word):
return word in sw or word in punctuation
gb = nltk.corpus.gutenberg
words = gb.words("shakespeare-caesar.txt")
labeled_words = ([(word.lower(), isStopword(word.lower())) for word in words])
random.seed(42)
random.shuffle(labeled_words)
print labeled_words[:5]
featuresets = [(word_features(n), word) for (n, word) in labeled_words]
cutoff = int(.9 * len(featuresets))
train_set, test_set = featuresets[:cutoff], featuresets[cutoff:]
classifier = nltk.NaiveBayesClassifier.train(train_set)
print "'behold' class", classifier.classify(word_features('behold'))
print "'the' class", classifier.classify(word_features('the'))
print "Accuracy", nltk.classify.accuracy(classifier, test_set)
print classifier.show_most_informative_features(5)