
Jug is a distributed computing framework that uses tasks as central parallelization units. As backends, Jug uses filesystems or the Redis server. The Redis server was discussed in Chapter 8, Working with Databases. Install Jug with the following command:
$ pip install jug
MapReduce (see http://en.wikipedia.org/wiki/MapReduce) is a distributed algorithm used to process large datasets with a cluster of computers. The algorithm consists of a Map and a Reduce phase. During the Map phase, data is processed in a parallel fashion. The data is split up in parts and on each part, filtering or other operations are performed. In the Reduce phase, the results from the Map phase are aggregated, for instance, to create a statistics report.
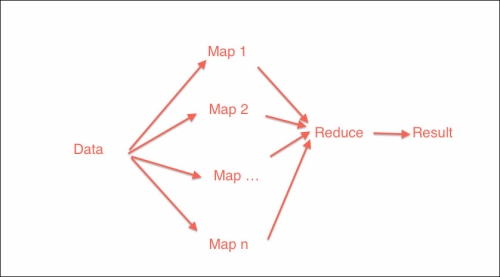
If we have a list of text files, we can compute word counts for each file. This can be done during the Map phase. At the end, we can combine individual word counts into a corpus word frequency dictionary. Jug has MapReduce functionality, which is demonstrated in the jug_demo.py file in this book's code bundle (the code depends on the cython_module artifact):
import jug.mapreduce
from jug.compound import CompoundTask
import cython_module as cm
import cytoolz
import cPickle
def get_txts():
return [(1, 'Lorem ipsum dolor sit amet, consectetur adipiscing elit.'), (2, 'Donec a elit pharetra, malesuada massa vitae, elementum dolor.'), (3, 'Integer a tortor ac mi vehicula tempor at a nunc.')]
def freq_dict(file_words):
filtered = cm.filter_sw(file_words[1].split())
fd = cytoolz.frequencies(filtered)
return fd
def merge(left, right):
return cytoolz.merge_with(sum, left, right)
merged_counts = CompoundTask(jug.mapreduce.mapreduce, merge, freq_dict, get_txts(), map_step=1)In the preceding code, the merge() function is called during the Reduce phase and the freq_dict() function is called during the Map phase. We define a Jug CompoundTask consisting of multiple subtasks. Before we run this code, we need to start a Redis server. Perform MapReduce by issuing the following command:
$ jug execute jug_demo.py --jugdir=redis://127.0.0.1/&
The ampersand (&) at the end means that this command runs in the background. We can issue the command from multiple computers in this manner, if the Redis server is accessible in the network. In this example, Redis only runs on the local machine (127.0.0.1 is the IP address of the localhost). However, we can still run the command multiple times locally. We can check the status of the Jug command as follows:
$ jug status jug_demo.py
By default, Jug stores data in the current working directory if we don't specify the jugdir option. Clean the Jug directory with the following command:
$ jug cleanup jug_demo.py
To query Redis and perform the rest of the analysis, we will use another program. In this program, initialize Jug as follows:
jug.init('jug_demo.py', 'redis://127.0.0.1/')
import jug_demoThe following line gets the results from the Reduce phase:
words = jug.task.value(jug_demo.merged_counts)
The rest of the code is given in the jug_redis.py file in this book's code bundle:
import jug
def main():
jug.init('jug_demo.py', 'redis://127.0.0.1/')
import jug_demo
print "Merged counts", jug.task.value(jug_demo.merged_counts)
if __name__ == "__main__":
main()