
You may have seen word clouds produced by Wordle or others before. If not, you will see them soon enough in this chapter. A couple of Python libraries can create word clouds; however, these libraries don't seem to beat the quality produced by Wordle yet. We can create a word cloud via the Wordle web page on http://www.wordle.net/advanced. Wordle requires a list of words and weights in the following format:
Word1 : weight Word2 : weight
Modify the code from the previous example to print the word list. As a metric, we will use the word frequency and select the top percent. We don't need anything new and the final code is in the cloud.py file in this book's code bundle:
from nltk.corpus import movie_reviews
from nltk.corpus import stopwords
from nltk import FreqDist
import string
sw = set(stopwords.words('english'))
punctuation = set(string.punctuation)
def isStopWord(word):
return word in sw or word in punctuation
review_words = movie_reviews.words()
filtered = [w.lower() for w in review_words if not isStopWord(w.lower())]
words = FreqDist(filtered)
N = int(.01 * len(words.keys()))
tags = words.keys()[:N]
for tag in tags:
print tag, ':', words[tag]Copy and paste the output into the Wordle web page and generate the following word cloud:

If we analyze the word cloud, it may occur to us that the result is far from perfect, so we may want to try something better. For instance, we can try to do the following things:
- Filter more: We should get rid of words that contain numeric characters and names. NLTK has a
namescorpus we can use. Also, words that only occur once in the whole corpus are good to ignore, since they probably don't add enough information value. - Use a better metric: The term frequency-inverse document frequency (tf-idf) seems a good candidate.
The tf-idf metric can give us ranking weights for words in our corpus. Its value is proportional to the number of occurrences of a word (corresponds to term frequency) in a particular document. However, it's also inversely proportional to the number of documents in the corpus (corresponds to inverse document frequency), where the word occurs. The tf-idf value is the product of term frequency and inverse document frequency. If we need to implement tf-idf ourselves, we have to consider logarithmic scaling as well. Luckily, we don't have to concern ourselves with the implementation details, since scikit-learn has a TfidfVectorizer class with an efficient implementation. This class produces a sparse SciPy matrix. This is a term-document matrix with tf-idf values for each combination of available words and documents. So, for a corpus with 2,000 documents and 25,000 unique words, we get a 2,000 x 25,000 matrix. A lot of the matrix values will be zero, which is where the sparseness comes in handy. The final rank weights can be found by summing all the tf-idf values for each word.
Improve filtering by using the isalpha() method and names corpus:
all_names = set([name.lower() for name in names.words()])
def isStopWord(word):
return (word in sw or word in punctuation) or not word.isalpha() or word in all_namesWe will again create a NLTK FreqDist to be able to ignore words that occur only once. The TfidfVectorizer class needs a list of strings representing each document in the corpus.
Create the list as follows:
for fid in movie_reviews.fileids():
texts.append(" ".join([w.lower() for w in movie_reviews.words(fid) if not isStopWord(w.lower()) and words[w.lower()] > 1]))Create the vectorizer; to be safe, let it ignore stopwords:
vectorizer = TfidfVectorizer(stop_words='english')
Create the sparse term-document matrix:
matrix = vectorizer.fit_transform(texts)
Sum the tf-idf values for each word and store it in a NumPy array:
sums = np.array(matrix.sum(axis=0)).ravel()
Now, create a pandas DataFrame with the word rank weights and sort it:
ranks = []
for word, val in itertools.izip(vectorizer.get_feature_names(), sums):
ranks.append((word, val))
df = pd.DataFrame(ranks, columns=["term", "tfidf"])
df = df.sort(['tfidf'])
print df.head()The lowest ranking values are printed as follows and can be considered for filtering:
term tfidf 8742 greys 0.03035 2793 cannibalize 0.03035 2408 briefer 0.03035 19977 superintendent 0.03035 14022 ology 0.03035
Now, it's a matter of printing the top ranking words and presenting them to Wordle in order to create the following cloud:
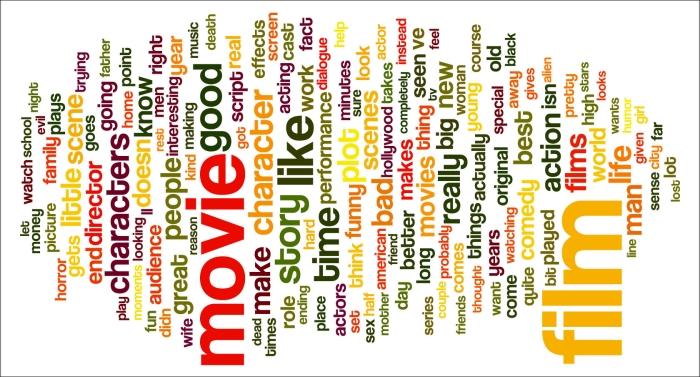
Unfortunately, you have to run the code yourself to see the difference in color with the previous word cloud. The tf-idf metric allows for more variation than the mere word frequency, so we get more varied colors. Also, the words in the cloud seem more relevant. Refer to cloud2.py file in this book's code bundle:
from nltk.corpus import movie_reviews
from nltk.corpus import stopwords
from nltk.corpus import names
from nltk import FreqDist
from sklearn.feature_extraction.text import TfidfVectorizer
import itertools
import pandas as pd
import numpy as np
import string
sw = set(stopwords.words('english'))
punctuation = set(string.punctuation)
all_names = set([name.lower() for name in names.words()])
def isStopWord(word):
return (word in sw or word in punctuation) or not word.isalpha() or word in all_names
review_words = movie_reviews.words()
filtered = [w.lower() for w in review_words if not isStopWord(w.lower())]
words = FreqDist(filtered)
texts = []
for fid in movie_reviews.fileids():
texts.append(" ".join([w.lower() for w in movie_reviews.words(fid) if not isStopWord(w.lower()) and words[w.lower()] > 1]))
vectorizer = TfidfVectorizer(stop_words='english')
matrix = vectorizer.fit_transform(texts)
sums = np.array(matrix.sum(axis=0)).ravel()
ranks = []
for word, val in itertools.izip(vectorizer.get_feature_names(), sums):
ranks.append((word, val))
df = pd.DataFrame(ranks, columns=["term", "tfidf"])
df = df.sort(['tfidf'])
print df.head()
N = int(.01 * len(df))
df = df.tail(N)
for term, tfidf in itertools.izip(df["term"].values, df["tfidf"].values):
print term, ":", tfidf