
Variance is the square of the average/mean of the difference between each value in the dataset with its average/mean; that is, it is the square of standard deviation.
Different Python libraries have functions to obtain the variance of the dataset. The NumPy library has the numpy.var(dataset) function. The statistics library has the statistics.variance(dataset) function. Using the pandas library, we calculate the variance in our df data frame using the df.var() function:
# variance of dataset using var() function
variance=df.var()
print(variance)
# variance of the specific column
var_height=df.loc[:,"height"].var()
print(var_height)
The output of the preceding code is as follows:
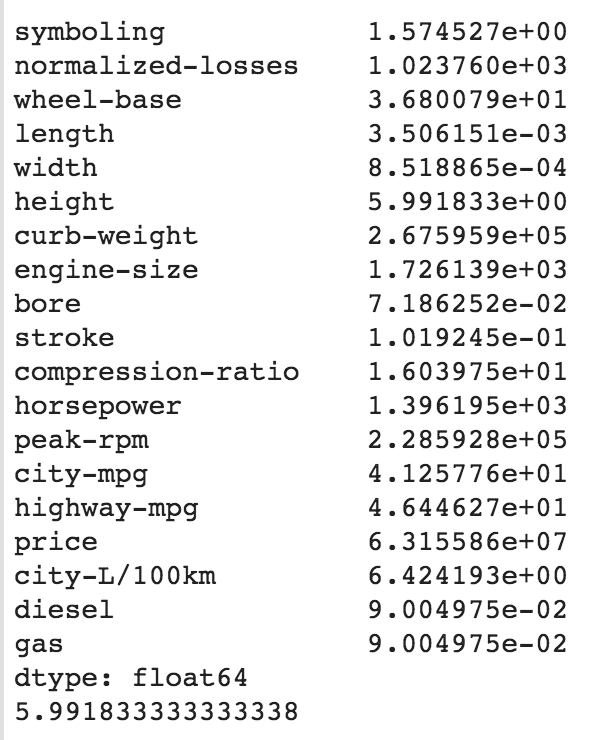
It is essential to note the following observations from the code snippet provided here:
- It is important to note that df.var() will calculate the variance in the given data frame across the column by default. In addition, we can specify axis=0 to indicate that we need to calculate variance by column or by row.
- Specifying df.var(axis=1) will calculate the row-wise variance in the given data frame.
- Finally, it is also possible to calculate the variance in any particular column by specifying the location. For example, df.loc[:,"height"].var() calculates the variance in the column height in the preceding dataset.