
In order to see the top few keywords that belong to each cluster, we need to create a function that provides us with the top 50 words from each of the clusters and plot the word cloud.
Check the function, as follows:
from wordcloud import WordCloud
fig, ax = plt.subplots(4, sharex=True, figsize=(15,10*4))
plt.rcParams["axes.grid"] = False
def high_frequency_keywords(data, clusters, labels, n_terms):
df = pd.DataFrame(data.todense()).groupby(clusters).mean()
for i,r in df.iterrows():
words = ','.join([labels[t] for t in np.argsort(r)[-n_terms:]])
print('Cluster {} '.format(i))
print(words)
wordcloud = WordCloud(max_font_size=40, collocations=False, colormap = 'Reds', background_color = 'white').generate(words)
ax[i].imshow(wordcloud, interpolation='bilinear')
ax[i].set_title('Cluster {} '.format(i), fontsize = 20)
ax[i].axis('off')
high_frequency_keywords(text, clusters, tfidf.get_feature_names(), 50)
The output of the preceding code is split into two. Let's take a look at the text output:
Cluster 0
bipolar,patient,framework,evaluation,risk,older,internet,healthcare,activity,approach,online,anxiety,research,digital,children,assessment,clinical,dementia,adaptive,cognitive,intervention,disorders,technology,learning,psychiatric,community,interventions,management,therapy,review,adults,use,support,designing,schizophrenia,stress,data,people,analysis,care,self,mobile,disorder,using,patients,design,study,treatment,based,depression
Cluster 1
cessation,brief,comparing,single,disorder,people,adults,symptoms,risk,clinical,women,prevention,reduce,improve,training,use,results,online,personalized,internet,cluster,alcohol,anxiety,feedback,efficacy,patients,health,mental,therapy,primary,help,self,program,care,effects,cognitive,pilot,treatment,depression,tailored,effectiveness,web,based,randomised,study,intervention,protocol,randomized,controlled,trial
Cluster 2
qualitative,physical,digital,implementation,self,medical,management,patient,adults,designing,life,quality,work,development,systems,data,related,children,persons,support,online,analysis,assessment,information,intervention,veterans,service,design,patients,problems,behavioral,using,research,systematic,disorders,use,interventions,primary,treatment,based,study,services,review,severe,people,community,illness,care,mental,health
Cluster 3
modeling,implications,ethical,emotion,behavioral,dementia,based,young,designing,homeless,dynamics,group,experiences,robot,predicting,mobile,game,depression,understanding,physical,people,challenges,therapy,study,patients,management,technology,impact,technologies,self,anxiety,use,skills,interaction,networking,personal,disclosure,sites,data,networks,disclosures,using,design,online,network,support,mental,health,media,social
Note that it printed four different clusters and 50 frequently occurring words in each cluster. It is easy to see the keywords that belong to each of the clusters and decide if clustering was done correctly or not. To present these words correctly, we generated a word cloud.
The word cloud is as follows:
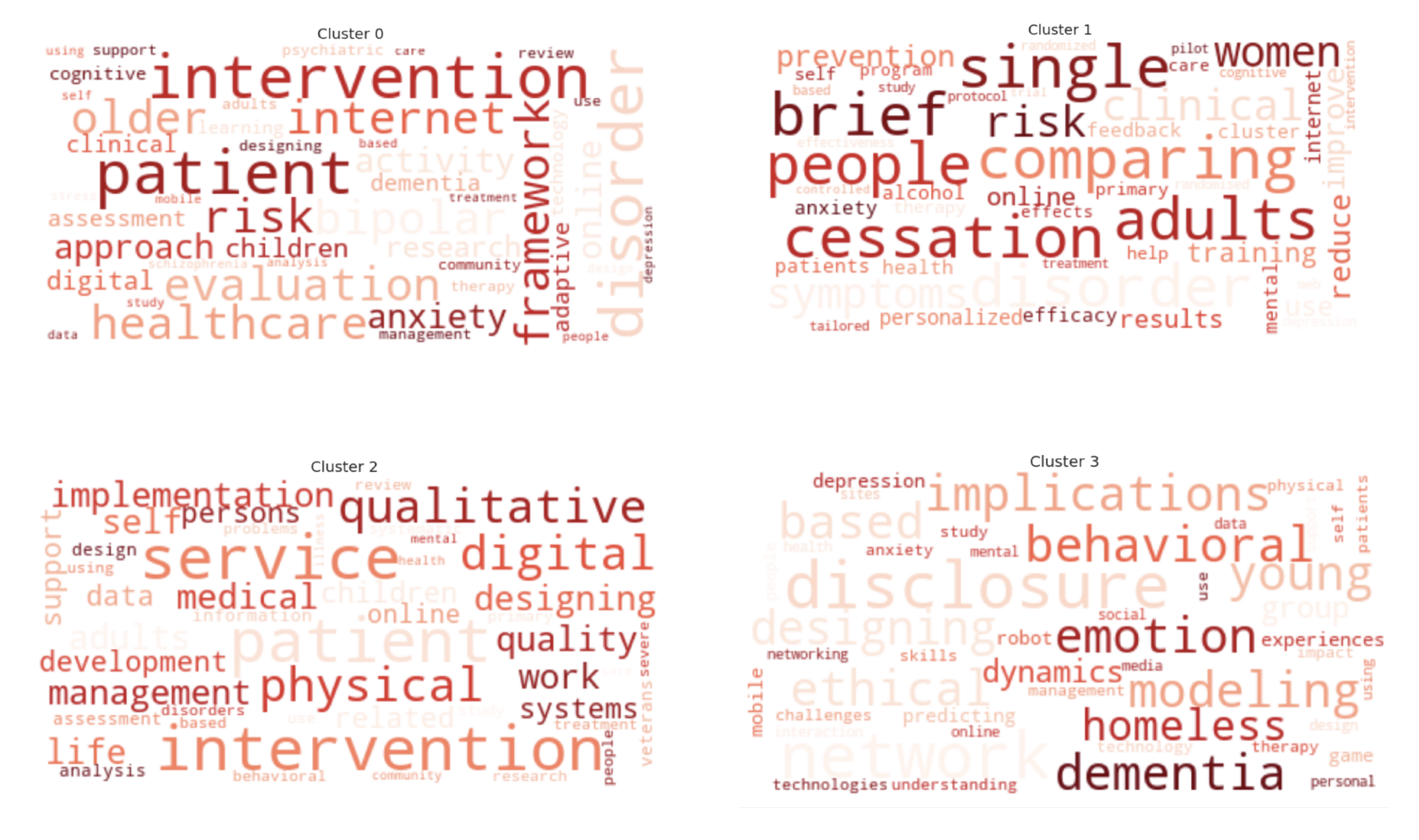
As we can see, there are four clusters. Each cluster shows the most related word. For example, cluster 0 shows a lot of words related to healthcare, intervention, framework, digital health, and so on. By doing this, it is easier to see the relationship between the keywords.
In the next section, we are going to discuss reinforcement learning.