
Often, we need to convert a categorical variable into some dummy matrix. Especially for statistical modeling or machine learning model development, it is essential to create dummy variables. Let's get started:
- Let's say we have a dataframe with data on gender and votes, as shown here:
df = pd.DataFrame({'gender': ['female', 'female', 'male', 'unknown', 'male', 'female'], 'votes': range(6, 12, 1)})
df
The output of the preceding code is as follows:

So far, nothing too complicated. Sometimes, however, we need to encode these values in a matrix form with 1 and 0 values.
- We can do that using the pd.get_dummies() function:
pd.get_dummies(df['gender'])
And the output of the preceding code is as follows:

Note the pattern. There are five values in the original dataframe with three unique values of male, female, and unknown. Each unique value is transformed into a column and each original value into a row. For example, in the original dataframe, the first value is female, hence it is added as a row with 1 in the female value and the rest of them are 0 values, and so on.
- Sometimes, we want to add a prefix to the columns. We can do that by adding the prefix argument, as shown here:
dummies = pd.get_dummies(df['gender'], prefix='gender')
dummies
The output of the preceding code is as follows:
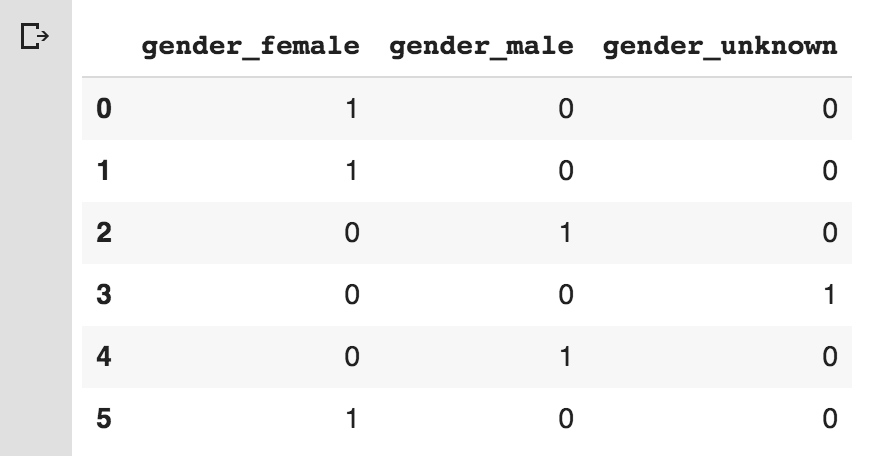
Note the gender prefix added to each of the column names. Not that difficult, right? Great work so far.
Let's look into another type of transformation in the following section.