
Aggregation is the process of implementing any mathematical operation on a dataset or a subset of it. Aggregation is one of the many techniques in pandas that's used to manipulate the data in the dataframe for data analysis.
The Dataframe.aggregate() function is used to apply aggregation across one or more columns. Some of the most frequently used aggregations are as follows:
- sum: Returns the sum of the values for the requested axis
- min: Returns the minimum of the values for the requested axis
- max: Returns the maximum of the values for the requested axis
We can apply aggregation in a DataFrame, df, as df.aggregate() or df.agg().
Since aggregation only works with numeric type columns, let's take some of the numeric columns from the dataset and apply some aggregation functions to them:
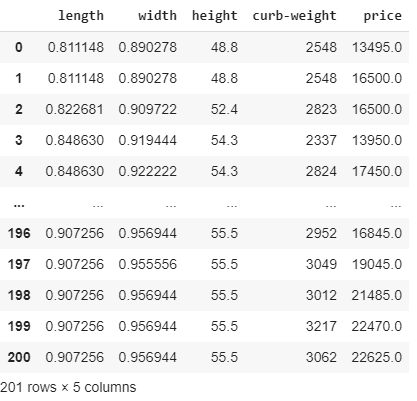
# new dataframe that consist length,width,height,curb-weight and price
new_dataset = df.filter(["length","width","height","curb-weight","price"],axis=1)
new_dataset
The output of the preceding code snippet is as follows:
Next, let's apply a single aggregation to get the mean of the columns. To do this, we can use the agg() method, as shown in the following code:
# applying single aggregation for mean over the columns
new_dataset.agg("mean", axis="rows")
The output of the preceding code is as follows:
length 0.837102
width 0.915126
height 53.766667
curb-weight 2555.666667
price 13207.129353
dtype: float64
We can aggregate more than one function together. For example, we can find the sum and the minimum of all the columns at once by using the following code:
# applying aggregation sum and minimum across all the columns
new_dataset.agg(['sum', 'min'])
The output of the preceding code is as follows:
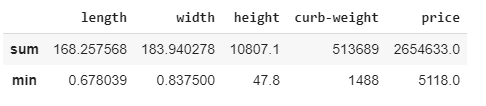
The output is a dataframe with rows containing the result of the respective aggregation that was applied to the columns. To apply aggregation functions across different columns, you can pass a dictionary with a key containing the column names and values containing the list of aggregation functions for any specific column:
# find aggregation for these columns
new_dataset.aggregate({"length":['sum', 'min'],
"width":['max', 'min'],
"height":['min', 'sum'],
"curb-weight":['sum']})
# if any specific aggregation is not applied on a column
# then it has NaN value corresponding to it
The output of the preceding code is as follows:

Check the preceding output. The maximum, minimum, and the sum of rows present the values for each column. Note that some values are NaN based on their column values.