
Wes McKinney open sourced the pandas library (https://github.com/wesm) that has been widely used in data science. We will be utilizing this library to get meaningful insight from the data. Before delving in detail into this section, we are going to revisit some of the most fundamental techniques in pandas that you should be familiar with so as to be able to follow upcoming chapters. If these things are new to you, feel free to check one of the further reading sections for additional resources. Perform the following steps:
- Use the following to set default parameters:
import numpy as np
import pandas as pd
print("Pandas Version:", pd.__version__)
pd.set_option('display.max_columns', 500)
pd.set_option('display.max_rows', 500)
- In pandas, we can create data structures in two ways: series and dataframes. Check the following snippet to understand how we can create a dataframe from series, dictionary, and n-dimensional arrays.
The following code snippet shows how we can create a dataframe from a series:
series = pd.Series([2, 3, 7, 11, 13, 17, 19, 23])
print(series)
# Creating dataframe from Series
series_df = pd.DataFrame({
'A': range(1, 5),
'B': pd.Timestamp('20190526'),
'C': pd.Series(5, index=list(range(4)), dtype='float64'),
'D': np.array([3] * 4, dtype='int64'),
'E': pd.Categorical(["Depression", "Social Anxiety", "Bipolar Disorder", "Eating Disorder"]),
'F': 'Mental health',
'G': 'is challenging'
})
print(series_df)
The following code snippet shows how to create a dataframe for a dictionary:
# Creating dataframe from Dictionary
dict_df = [{'A': 'Apple', 'B': 'Ball'},{'A': 'Aeroplane', 'B': 'Bat', 'C': 'Cat'}]
dict_df = pd.DataFrame(dict_df)
print(dict_df)
The following code snippet shows how to create a dataframe from n-dimensional arrays:
# Creating a dataframe from ndarrays
sdf = {
'County':['Østfold', 'Hordaland', 'Oslo', 'Hedmark', 'Oppland', 'Buskerud'],
'ISO-Code':[1,2,3,4,5,6],
'Area': [4180.69, 4917.94, 454.07, 27397.76, 25192.10, 14910.94],
'Administrative centre': ["Sarpsborg", "Oslo", "City of Oslo", "Hamar", "Lillehammer", "Drammen"]
}
sdf = pd.DataFrame(sdf)
print(sdf)
-
Now, let's load a dataset from an external source into a pandas DataFrame. After that, let's see the first 10 entries:
columns = ['age', 'workclass', 'fnlwgt', 'education', 'education_num',
'marital_status', 'occupation', 'relationship', 'ethnicity', 'gender','capital_gain','capital_loss','hours_per_week','country_of_origin','income']
df = pd.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/adult/adult.data',names=columns)
df.head(10)
If you run the preceding cell, you should get an output similar to the following screenshot:
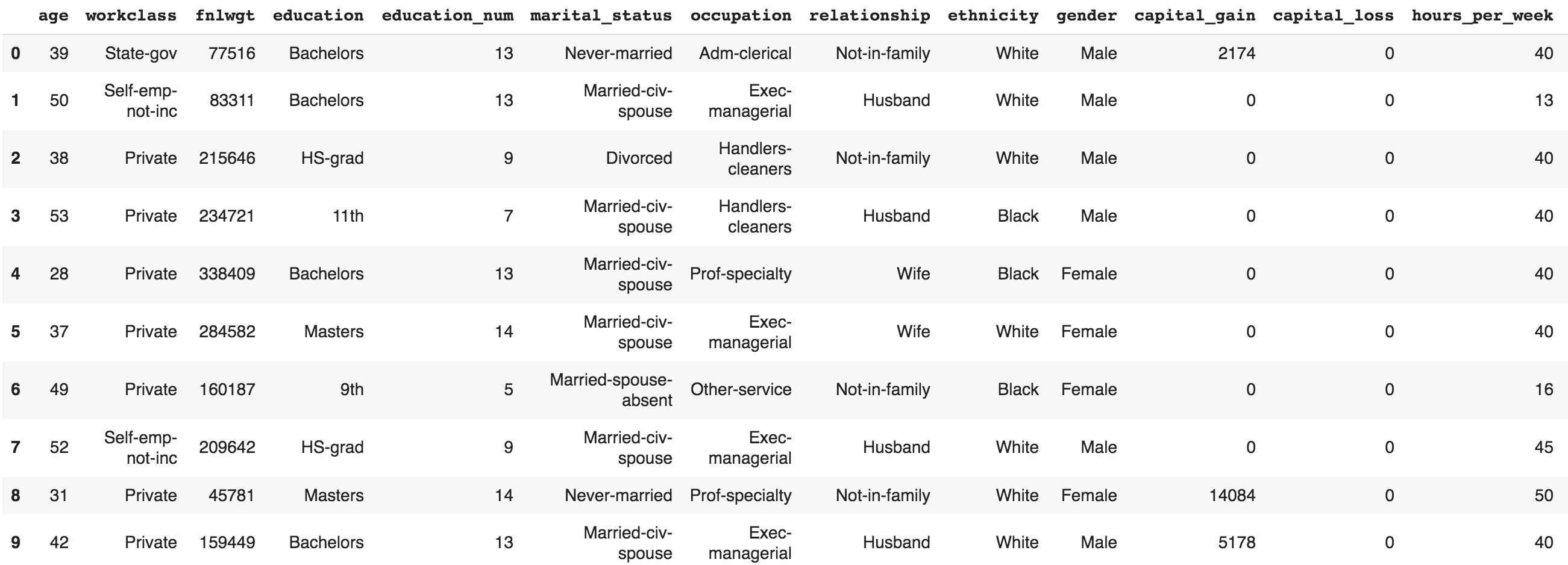
- The following code displays the rows, columns, data types, and memory used by the dataframe:
df.info()
The output of the preceding code snippet should be similar to the following:
# Output:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 32561 entries, 0 to 32560
Data columns (total 15 columns):
age 32561 non-null int64
workclass 32561 non-null object
fnlwgt 32561 non-null int64
education 32561 non-null object
education_num 32561 non-null int64
marital_status 32561 non-null object
occupation 32561 non-null object
relationship 32561 non-null object
ethnicity 32561 non-null object
gender 32561 non-null object
capital_gain 32561 non-null int64
capital_loss 32561 non-null int64
hours_per_week 32561 non-null int64
country_of_origin 32561 non-null object
income 32561 non-null object
dtypes: int64(6), object(9)
memory usage: 3.7+ MB
- Let's now see how we can select rows and columns in any dataframe:
# Selects a row
df.iloc[10]
# Selects 10 rows
df.iloc[0:10]
# Selects a range of rows
df.iloc[10:15]
# Selects the last 2 rows
df.iloc[-2:]
# Selects every other row in columns 3-5
df.iloc[::2, 3:5].head()
- Let's combine NumPy and pandas to create a dataframe as follows:
import pandas as pd
import numpy as np
np.random.seed(24)
dFrame = pd.DataFrame({'F': np.linspace(1, 10, 10)})
dFrame = pd.concat([df, pd.DataFrame(np.random.randn(10, 5), columns=list('EDCBA'))],
axis=1)
dFrame.iloc[0, 2] = np.nan
dFrame
It should produce a dataframe table similar to the following screenshot:
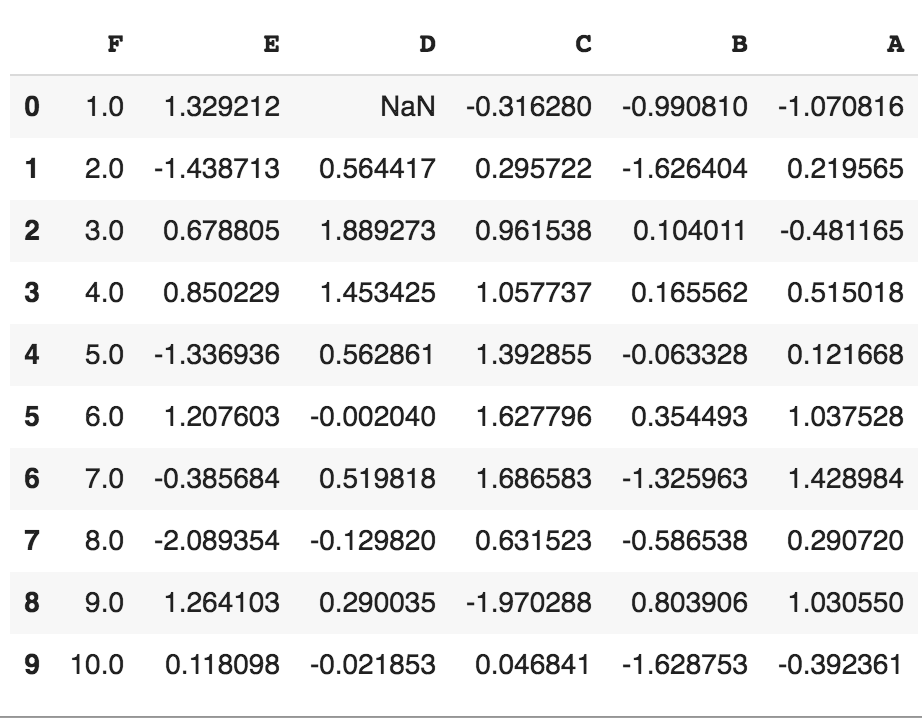
- Let's style this table using a custom rule. If the values are greater than zero, we change the color to black (the default color); if the value is less than zero, we change the color to red; and finally, everything else would be colored green. Let's define a Python function to accomplish that:
# Define a function that should color the values that are less than 0
def colorNegativeValueToRed(value):
if value < 0:
color = 'red'
elif value > 0:
color = 'black'
else:
color = 'green'
return 'color: %s' % color
- Now, let's pass this function to the dataframe. We can do this by using the style method provided by pandas inside the dataframe:
s = df.style.applymap(colorNegativeValueToRed, subset=['A','B','C','D','E'])
s
It should display a colored dataframe as shown in the following screenshot:
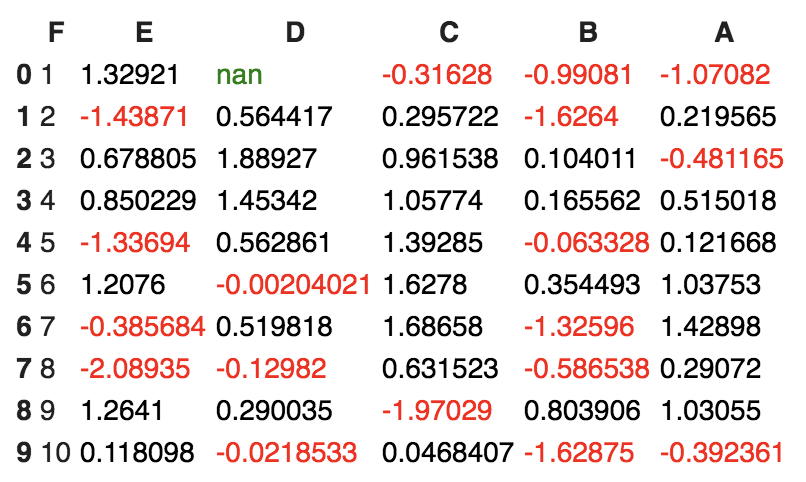
It should be noted that the applymap and apply methods are computationally expensive as they apply to each value inside the dataframe. Hence, it will take some time to execute. Have patience and await execution.
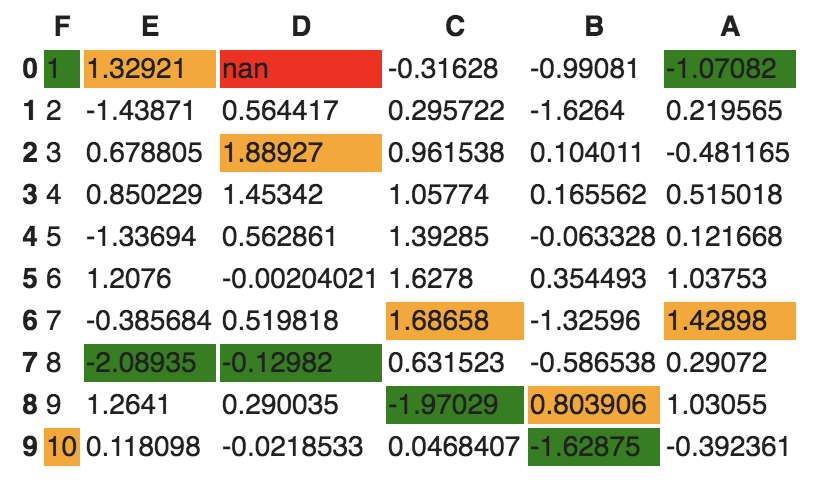
- Now, let's go one step deeper. We want to scan each column and highlight the maximum value and the minimum value in that column:
def highlightMax(s):
isMax = s == s.max()
return ['background-color: orange' if v else '' for v in isMax]
def highlightMin(s):
isMin = s == s.min()
return ['background-color: green' if v else '' for v in isMin]
We apply these two functions to the dataframe as follows:
df.style.apply(highlightMax).apply(highlightMin).highlight_null(null_color='red')
The output should be similar to the following screenshot:
- Are you still not happy with your visualization? Let's try to use another Python library called seaborn and provide a gradient to the table:
import seaborn as sns
colorMap = sns.light_palette("pink", as_cmap=True)
styled = df.style.background_gradient(cmap=colorMap)
styled
The dataframe should have an orange gradient applied to it:

There are endless possibilities. How you present your result depends on you. Keep in mind that when you present your results to end stakeholders (your managers, boss, or non-technical persons), no matter how intelligently written your code is, it is worthless to them if they cannot make sense of your program. It is widely accepted that better-visualized results are easy to market.