
It is very likely that your dataframe contains duplicate rows. Removing them is essential to enhance the quality of the dataset. This can be done with the following steps:
- Let's consider a simple dataframe, as follows:
frame3 = pd.DataFrame({'column 1': ['Looping'] * 3 + ['Functions'] * 4, 'column 2': [10, 10, 22, 23, 23, 24, 24]})
frame3
The preceding code creates a simple dataframe with two columns. You can clearly see from the following screenshot that in both columns, there are some duplicate entries:

- The pandas dataframe comes with a duplicated() method that returns a Boolean series stating which of the rows are duplicates:
frame3.duplicated()
The output of the preceding code is pretty easy to interpret:

The rows that say True are the ones that contain duplicated data.
- Now, we can drop these duplicates using the drop_duplicates() method:
frame4 = frame3.drop_duplicates()
frame4
The output of the preceding code is as follows:

Note that rows 1, 4, and 6 are removed. Basically, both the duplicated() and drop_duplicates() methods consider all of the columns for comparison. Instead of all the columns, we could specify any subset of the columns to detect duplicated items.
- Let's add a new column and try to find duplicated items based on the second column:
frame3['column 3'] = range(7)
frame5 = frame3.drop_duplicates(['column 2'])
frame5
The output of the preceding snippet is as follows:
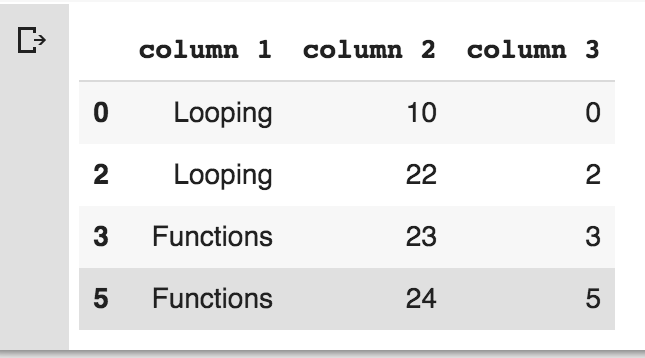
Note that both the duplicated and drop_duplicates methods keep the first observed value during the duplication removal process. If we pass the take_last=True argument, the methods return the last one.