
16.4 Experiments
Two data sets are used for experiments, the HYDICE image data in Figure 1.15 and Purdue's Indian Pine test site AVIRIS data in Figure 1.13.
16.4.1 HYDICE Image Experiments
Since the precise knowledge of the 19 R panel pixels is known according to the ground truth provided in Figure 1.15(b), the mean of each of five panel signatures is calculated by averaging the R pixels for each of five rows and shown in Figure 1.16. These five panel signatures were used for discrimination and also as a database for identification. Table 16.1 tabulates identification errors of 19 R panel pixels resulting from pixel-based hyperspectral measures, ED, SAM, OPD, SID, and correlation-weighted hyperspectral measures, MDRX, MDCEM, MFDRX, and MFDCEM where all the four correlation-weighted hyperspectral measures made no errors compared to pixel-based hyperspectral measures that made errors ranging from 4 to 6 with the SID and ED being the best and worst measures.
Table 16.1 Identification errors of 19 R pixels resulting from signature vector-based hyperspectral measures and second-order statistics weighted hyperspectral measures.

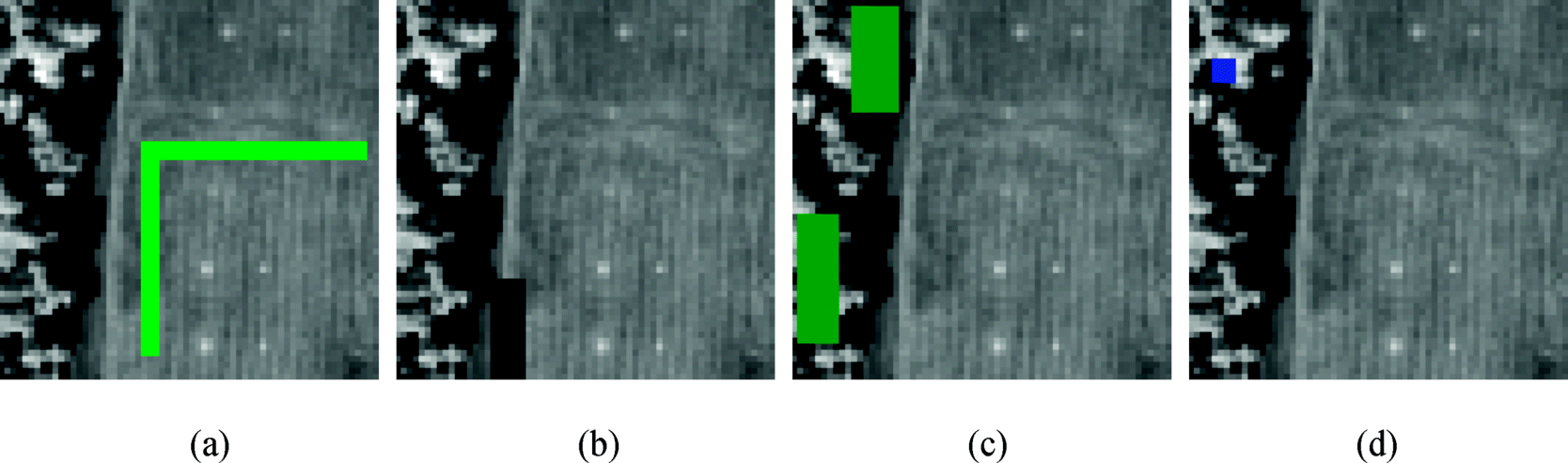
Since the performance of a posteriori correlation-weighted hyperspectral measures varies with the knowledge of the U used in their measures, their results are not included in Table 16.1. Instead, this issue is investigated separately. To see the impact of various knowledge of U on ![]() -weighted hyperspectral measures, the particular sampling areas specified by the marked areas in Figure 16.2(a)–(d) were used to obtain undesired signatures for U.
-weighted hyperspectral measures, the particular sampling areas specified by the marked areas in Figure 16.2(a)–(d) were used to obtain undesired signatures for U.
Figure 16.2 (a) Sample grass area; (b) sample road area; (c) sample tree area; (d) sample interference area.
Let u5, u6, u7, and u8 denote grass, road, tree, and interference signatures averaged over these four sample areas, respectively. Table 16.2 tabulates identification errors resulting from the two ![]() -weighted hyperspectral measures for identification, IDOSP,Δ and IDOSP where U4 consists of four undesired panel signatures and U5 = [U4u5], U6 = [U4u5u6], U7 = [U4u5u6u7], U8 = [U4u5u6u7u8].
-weighted hyperspectral measures for identification, IDOSP,Δ and IDOSP where U4 consists of four undesired panel signatures and U5 = [U4u5], U6 = [U4u5u6], U7 = [U4u5u6u7], U8 = [U4u5u6u7u8].
Table 16.2 Identification errors resulting from the a posteriori-weighted hyperspectral measures, IDOSP-D,Δ and IDOSP-D with various knowledge provided by U

As shown in Table 16.2, IDOSP,Δ performed better than IDOSP and both improved their performance if more undesired signatures were eliminated. In particular, IDOSP,Δ made no errors once a background signature was eliminated, while IDOSP must wait until all four background signatures were eliminated. Nevertheless, both IDOSP,Δ and IDOSP generally performed better than signature vector-based hyperspectral measures.
16.4.2 AVIRIS Image Experiments
Another image data set to be used in this section is Purdue's Indian Pine test site shown in Figure 1.13 that is an AVIRIS image collected from an area of mixed agriculture and forestry in Northwestern Indiana, USA. This image scene has been studied extensively in the literature. It is very interesting in the sense that most pixels in the image scene are heavily mixed and and provides another excellent example for experiments. A detailed study on this scene was recently reported in Liu et al. (2006). Unfortunately, to the author's best knowledge, a comprehensive study on subpixels and mixed pixels in this scene is yet to be done.
Since the number of samples in each of 16 pattern classes varies in a wide range, the performance of correlation-weighted hyperspectral measures also varies. Tables 16.3 and 16.4 tabulate classification rates in percentage (%) of signature vector-based hyperspectral measures and correlation-weighted hyperspectral measures for 16 classes, respectively, where the classes are sorted in an increasing order of the number of samples and the last row calculated the averaged classification rates produced by various measures for each of 16 classes. Comparing Table 16.3 with Table 16.4, it is surprising to discover that the two MD-based hyperspectral measures, two MFD-based hyperspectral measures performed best among all the measures and the signature vector-based hyperspectral measured performed better than OSP-based hyperspectral measures.
Table 16.3 Classification resulting from various signature vector-based hyperspectral measures.

Table 16.4 Classification rates resulting from various correlation weighted-based hyperspectral measures.

Several observations can be made by Tables 16.3 and 16.4 and are worthwhile. The MFD-based hyperspectral measures, MDRX and MDCEM performed well when the number of samples is small in classes 9, 7, 1, 16, 13, 4, 16. Their performance was deteriorated with increasing samples as opposed to signature vector-based hyperspectral measures which performed increasingly better than did MFDRX and MFDCEM in classes 10, 14, 2, 11. This was due to the fact that the matching signatures to be used were increasingly affected by contaminated spectral correlation caused by more heavily mixed pixels, in which case, signature vector-based hyperspectral measures were not affected by sample spectral correlation. This was also witnessed by the performance of OSP-based hyperspectyral measures where the signature vectors used for the U were heavily mixed. Such mixed pixel information resulted in erroneous elimination of desired pixel information used by IDOSP,Δ and IDOSP. However, it seemed that the performance of OSP-based hyperspectral measures, MD-based and MFD-based hyperspectral measures was little affected by number of samples. They yielded the best performance in general.
In the past, many research efforts published in the literature have studied this image scene with background removed from the image scene for analysis. In the following experiments, we investigate such a scenario to see if the knowledge of background affects the performance of the correlation-weighted hyperspectral measures. Table 16.5 tabulates their classification rates in percentage (%) for 16 classes.
Table 16.5 Classification rates resulting from various correlation-weighted hyperspectral measures with background removed.

Comparing Table 16.5 with Table 16.4, their performances did not change drastically where both OSP-based hyperspectral measures and MD-based hyperspectral measures improved classification slightly in contrast to the MFD-based hyperspectral measures whose performance was slightly degraded. This was because the former had less interference caused by the mixed pixels in the background, while the latter required background pixels included in the sample correlation/covariance matrix to eliminate the effect incurred by the background.
Finally, Figure 16.3 plots the averaged performance of the four types of measures, sample-based, OSP-based, MD-based, and MFD-based hyperspectral measures in classification by averaging the results in Tables 16.3 and 16.4 with MDRX + MDCEM → MD-based hyperspectral measures, MFDRX + MFDCEM → MFD-based hyperspectral measures, IDOSP,Δ, IDOSP → OSP-based hyperspectral measures, ED + SAM + SID + OPD → signature vector-based hyperspectral measures.
Figure 16.3 Averaged performance of four types of measures, signature vector-based, OSP-based, MD-based, and MFD-based hyperspectral measures.

It is interesting to find that MD-based hyperspectral measures yielded the best performance. The ability of the MFD-based hyperspectral measures in classification was also reasonably good with performance deteriorated as the number of samples was increased. The OSP-based hyperspectral measures performed better when the sample size was small. On average the performance of signature vector-based hyperspectral measures was the worst.
A concluding comment is noteworthy. On many occasions the correlation-weighted hyperspectral measures are easy to be confused with classifiers when they are applied to real images to perform spectral similarity such as experiments performed above for the HYDICE and Purdue's Indian Pine scene images. First, the correlation-weighted hyperspectral measures are not designed for classifiers. Instead, they are designed to discriminate and identify signature vectors. Second, a classifier is a discrete p-value function which maps a data sample to a specific value that indicates the class to which it belongs. So, it is a class membership-labeling process and needs to know the number of classes, p a priori. Such prior knowledge is not required by the correlation-weighted hyperspectral measures. Third, a classifier generally requires training samples to provide its needed class information, while the correlation-weighted hyperspectral measures do not. Finally and most importantly, when a classifier operates on data sample vectors in the original data space, it usually implements a distance metric to measure similarity between two data sample vectors. So, when signature vector-based hyperspectral measures can be used for this distance metric, in which case they become classifiers. Classifiers of this type include ISODATA, nearest neighbor rule-based classifiers. However, a good classifier generally extracts class feature information or takes advantage of training sample vectors to transform the original data space into a feature space in which it can perform classification more effectively on the extracted class features rather than data sample vectors. This is the main reason that classifiers of this type such as FLDA and SVM always perform better than the correlation-weighted hyperspectral measures used as classifiers.