
11.2 Orthogonal Projection-Based EEAs
In this section, we further show that PPI, VCA, and ATGP-EEA are essentially the same type of algorithms that rather appear in different forms. All of these three EEAs use the OP derived from the principle of orthogonality to find endmembers. OP is one of most widely used concepts in statistical signal processing and plays a key role in mean squared error or least squares error-based approaches (Poor, 1994). It basically says that any new or innovations information must be orthogonal in the sense of mean squared error or least squares error to the information that is already known or the information that can be inferred from the data samples that were already processed. A best example of using OP is the orthogonal subspace projection (OSP) approach developed for linear spectral mixture analysis (Harsanyi and Chang, 1994; Chang, 2003a; Chang, 2005) as well as ATGP used for target detection and classification (Ren and Chang, 2003; Chang, 2003a). Interestingly, the first use of OP in endmember extraction is PPI, which assumes that the more likely the data sample to be an endmember, the better chance the data sample to be orthogonally projected at end points of a skewer where a skewer is a randomly generated unit vector. A further use of OP is exploited by VCA that selects a data sample vector with the maximal OP in the OSP-projected space as a potential endmember. Interestingly, PPI, ATGP, and VCA share the same idea of using OP to find endmembers, but their relationships are never realized and explored until Wu et al. (2007). As a matter of fact, these three seemingly different EEAs are indeed closely related. The following section reinterprets them from an OP perspective in a unified framework.
11.2.1 Relationship among PPI, VCA, and ATGP
The idea of PPI is very simple and intuitive. It assumes that for a given “right” vector an endmember should have its OP falling at one of two end points of the vector with either maximal or minimal OP. A key issue is how to find such a “right” vector. Since there is no prior knowledge about endmembers, the best way is to randomly generate as many vectors as needed to find “right” vectors so that endmembers can be orthogonally projected at as many their end points as possible. A vector randomly generated with unit length for this purpose is called a skewer. In order to accomplish its goal, PPI requires a large number of skewers, K, and then assigns a count to each of data sample vectors, to be called the PPI count, by counting the number of skewers on which the data sample vector is projected orthogonally as their end points. Hopefully, the higher PPI count of a data sample vector, the more likely it is an endmember. Despite that such an approach is elegant, two major drawbacks need to be addressed. First is how large the number of skewers is sufficient. Second is how to determine an appropriate cut-off value for PPI counts to produce a desired set of endmembers. Unfortunately, none of these two issues is easy to deal with.
The development of ATGP is originally designed to find targets of interest in data when no prior target knowledge is available. It repeatedly implements orthogonal projections to produce a nested sequence of decreasing orthogonal complement subspaces, each of which can be used to extract a specific target with maximal orthogonal projection. As shown in Chapter 8, most of ATGP-generated target pixels indeed ended up desired endmembers. This is certainly not a surprise because the concept behind ATGP is OP that is exactly the same criterion used by PPI. Nevertheless, there are two exceptions. First is that PPI requires a very large number of skewers to find maximal or minimal OP compared to ATGP that finds targets of interest from a sequence of orthogonal projection subspaces with maximal projections. Accordingly, PPI simultaneously extracts all endmembers compared to ATGP that extracts targets sequentially one after another. Second is that PPI takes advantage of random nature in skewers to uncover all possible endmembers as opposed to ATGP that takes a deterministic approach to search for definite directions of maximal projections to find possible target candidates in a sequence of orthogonal projection subspaces. Nonetheless, both PPI and ATGP share the same principle and implement OP to find what they are designed for. The goal of VCA is to improve PPI by replacing the skewers with Gaussian random vectors, which can be viewed as Gaussian skewers, and then repeatedly using OP as the way ATGP does to generate a sequence of subspaces via OP in which data with the maximal OP are extracted as an endmember. In addition to the use of Gaussian skewers to produce initial endmembers, VCA also differs from PPI in three aspects. VCA does not need a large number of Gaussian skewers, but it does require prior knowledge about the number of endmembers needed to be generated. Another is that VCA is a SQ-EEA and can be considered as a sequential version of PPI which is in fact an SM-EEA. ATGP actually fills the gap between PPI and VCA. Finally, in order to ensure that endmembers to be extracted are non-negative, i.e., satisfying abundance non-negativity constraint (ANC), VCA restricts its search region in the first quadrant, while PPI selects skewers from all possible random directions.
11.2.1.1 Relationship Between PPI and ATGP
As noted in the introduction, PPI and ATGP-EEA share the principle of orthogonality to find their targets of interest, that is, endmembers in our case. In what follows, we conduct an item-by-item in-depth comparative study between these two. For the sake of simplicity the ATGP-EEA is replaced with ATGP throughout the chapter.
The above-mentioned relationship between PPI and ATGP was not explored in Chang and Plaza (2006) and Plaza and Chang (2006), but their conducted experiments did show that most of final PPI-selected endmembers are the same data sample vectors produced by ATGP.
11.2.1.2 Relationship Between PPI and VCA
The relationship between PPI and VCA is more obvious than that between PPI and ATGP described above.
![]()
![]()
11.2.1.3 Relationship Between ATGP and VCA
The relationship between ATGP and VCA was first noted in Wu et al. (2007) and later in Greg (2010). Technically speaking, both ATGP and VCA are essentially the same algorithm in terms of design rationale as they can be interpreted one from another as follows.
(11.2) ![]()
(11.4) ![]()
(11.6) ![]()
11.2.1.4 Discussions
VCA suffers from the uncertainty caused by the use of random initial endmembers, as PPI does. In order resolve this issue, VCA requires a large number of initial endmembers as PPI does to constitute reliable statistics. Therefore, the number of vertices required for VCA must be sufficiently large. As a consequence, it may result in more vertices than VCA needs. Such a dilemma is avoided by PPI that provides a visualization tool to allow users to manually perform what VCA cannot do. ATGP introduces a deterministic approach to correct this random issue and uses a VD-estimated value to generate a desired set of target sample vectors. Such an approach is adopted by PPI and referred to as fast iterative PPI (FIPPI) in Chang and Plaza (2006) and will be referred to as ATGP-PPI for consistency in this chapter. A similar approach can be also applied to VCA, called ATGP-VCA, to mitigate the same issue caused by the use of Gaussian random variables by VCA.
Figure 11.1 summarizes the relationships among PPI, ATGP, and VCA along with ATGP-PPI and ATGP-VCA, both of which implement ATGP as their initialization algorithm to produce an initial set of endmembers. As noted, VCA, ATGP-VCA, and ATGP-PPI play a role bridging PPI and ATGP.
Figure 11.1 Relationships among the PPI, VCA, and ATGP.
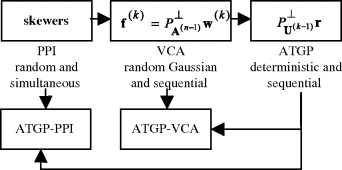
The insights into relationships in Figure 11.1 have never been investigated in the literature. As a matter of fact, VCA is nothing more than an orthogonal projection-based endmember extraction algorithm that can be considered as a variant of PPI or ATGP. However, the connection between PPI and VCA is not clear until ATGP is used to bridge the gap between these two. Since both PPI and VCA use randomly generated vectors as their initial endmembers, two issues become evidential: inconsistency in final results and insufficient statistics to cope with randomness. In order to cope with these two issues, ATGP-PPI and ATGP-VCA are introduced to produce a set of ATGP-generated target sample vectors that can be used as initial endmembers.
Over the past years, VCA has been a well-accepted endmember extraction algorithm in the literature. However, the insights into the design rationale into VCA have not been explored. In this section, we trace back to its origin and show that VCA is actually a variant of ATGP and is derived from the concept of PPI. Furthermore, as shown in Chang et al. (2006), Chapter 8 and the following experiments in Section 11.2.2 the performance of VCA is generally not as good as many people expect. Specifically, as an endmember extraction algorithm, VCA generally cannot compete against simplex-based methods such as N-FINDR, SGA. This is because its used criterion is maximal orthogonal subspace projection not maximal simplex volume. As a result, VCA does not satisfy the sum to one abundance constraint (ASC) compared to simplex volume criterion which satisfies both convexity constraints, ANC and ASC imposed on extraction of endmembers. On the other hand, due to the fact that both VCA and ATGP use maximal orthogonal subspace projection, ATGP indeed performs better than VCA does in endmember extraction on many cases because ATGP finds the maximal orthogonal projection over the entire data space orthogonal complement to the space linearly spanned by already found endmembers compared to VCA which restricts its search region to convex hulls in the first quadrant. This may result in the fact that some ATGP-extracted samples may not be in the first quadrant. But according to our experiments, such case did not occur often. Additionally, as an unsupervised target detection algorithm, VCA does not perform as well as ATGP. Consequently, in either case of endmember extraction or unsupervised target detection, ATGP is generally doing better than VCA. Finally, as for computational complexity, both VCA and ATGP perform orthogonal projections and their computing time is very fast. Because of that, VCA may have an edge over simplex volume-based techniques in the sense that only orthogonal projections are performed compared to calculating matrix determent for a simplex volume. But this advantage is poorly traded for its performance in endmember extraction.
11.2.2 Experiments-Based Comparative Study and Analysis
In order to conduct a comprehensive comparative analysis, two data sets from the real AVIRIS Cuprite image data shown in Figure 1.12(c) and (d) are used to simulate TI2. Since TI1 has no noise simulated in the image and TI3 contains endmembers corrupted by Gaussian noise, only TI2 is selected for experiments because it simulates exactly pure signatures as endmembers implanted in the image scene.
11.2.2.1 Synthetic Image Experiment: TI2
The reflectance data of Figure 1.12(c) is used for experiments where the VD estimated for this data set by the Hrasanyi–Farrend–Chang method is nVD = 6 with ![]() . In this case, the value of 6 is used as the number of endmembers, p = 6, as well as the number of dimensions or components required for DR, q = 6. But in fact, q = p−1. So in experiments, these two values are used for experiments.
. In this case, the value of 6 is used as the number of endmembers, p = 6, as well as the number of dimensions or components required for DR, q = 6. But in fact, q = p−1. So in experiments, these two values are used for experiments.
Reflectance Data
Table 11.1 tabulates endmember pixels extracted by three OP-based EEAS along with two versions of PPI and VCA using ATGP-generated pixels as initial endmembers, ATGP-PPI and ATGP-VCA, respectively, where four transforms, PCA, MNF, SVD, and ICA, are implemented for DR with q = 6 (Note: the DR techniques used by the original VCA is SVD). Here, an endmember pixel is defined as a pixel whose spectral signature is an endmember and the number of skewers used by PPI is K = 200.
Table 11.1 Endmembers extraction by PPI, ATGP, VCA, ATGP-PPI, and ATGP-VCA (TI2 with reflectance data)

Interestingly, the level of knowledge required by the three algorithms, PPI, ATGP, and VCA, can be closely related to one another. Despite that PPI does not require the knowledge of the number of endmembers, p, it does need to know the value of q, the number of dimensions or components when it performs DR. Quite oppositely, VCA and ATGP only require to know the number of target pixels they must generate, in which case this number was set to p and q was set to be equal to p, that is, p = q.
According to the results of Table 11.1, all the five algorithms performed comparably. In particular, the results demonstrated that p = 6 was sufficient for the five algorithms to successfully extract all the five mineral endmembers. It is also worth noting that since both the PPI and the VCA used p randomly generated vectors as their initial endmembers, the final results were not consistent. As a result, on some occasions, they may not extract all the five endmembers. The results of the PPI and VCA in Table 11.1 were obtained by their best runs.
Radiance Data
As another example, a second synthetic image was simulated by radiance data in exactly the same manner as the first synthetic image, TI2, except that the five mineral signatures were the radiance data in Figure 1.12(d) instead of the reflectance data used in Figure 1.12(c).
Interestingly, VD estimated for this radiance data-based synthetic image, TI2, was nVD = 5 with ![]() instead of six estimated for the reflectance data-based synthetic image. In other words, the background simulated by the sample mean of the radiance data-based synthetic image was not considered as an endmember as it was where the background was simulated by the sample mean of the reflectance data-based synthetic image due to our belief that the reflectance data are calibrated. So, the value of p was set to 5 and the number of dimensions or components required for DR was also set to q = 5.
instead of six estimated for the reflectance data-based synthetic image. In other words, the background simulated by the sample mean of the radiance data-based synthetic image was not considered as an endmember as it was where the background was simulated by the sample mean of the reflectance data-based synthetic image due to our belief that the reflectance data are calibrated. So, the value of p was set to 5 and the number of dimensions or components required for DR was also set to q = 5.
Table 11.2 tabulates endmember pixels extracted by three OP-based EEAS along with two versions of the PPI and VCA using ATGP-generated pixels as initial endmembers, ATGP-PPI and ATGP-VCA, respectively, where three transforms, PCA, MNF, and ICA, were implemented for DR with q = 5 and the results highlighted by shade indicate failures of extracting all five endmembers.
Table 11.2 Endmembers extraction by PPI, ATGP, VCA, ATGP-PPI, and ATGP-VCA (TI2 with radiance data)
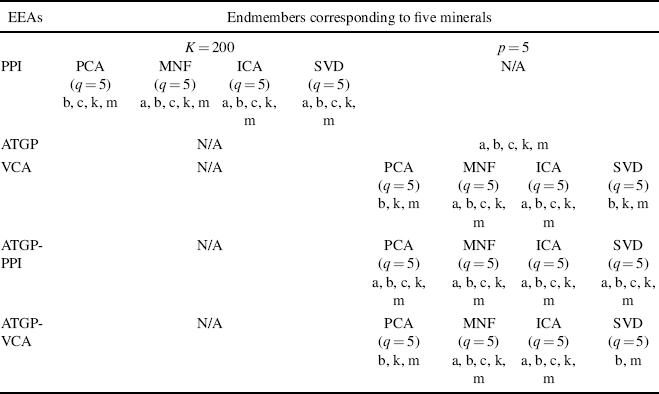
As shown in the table, the best performance was ATGP, while the worst one was VCA. Two observations are noteworthy. One is that ATGP-VCA using ATGP as its initialization algorithm did not improve its performance over VCA with the use of random initial endmembers even though ATGP was the one that yields the best performance. This implies that the target sample vectors generated by ATGP that were supposed to be endmember pixels were actually compromised by the process of finding the maximal OP implemented in VCA where ATGP-generated target pixels were replaced by the data sample vectors that yielded the maximal OPs at each iteration but turned out to be not endmembers. This finding further demonstrated that the maximal OP used by VCA as a criterion was ineffective and may not be as good as the criterion of using maximal simplex volume. On the contrary, ATGP did improve PPI with PCA where ATGP-generated target sample vectors helped PPI find correct projection directions due to the reason that PCA compromised endmembers by retaining second-order statistics in a few principal components, while endmembers should be characterized by high-order statistics. A comparison of results between Tables 11.1 and 11.2 indicates that the radiance data set presented more challenges for an EEA than the reflectance data set.
11.2.2.2 Real Image Experiments
In this section, we repeat the same synthetic image experiments conducted in Section 11.2.2.1.3 for two real hyperspectral image scenes, HYDICE data in Figure 1.15(a) and Cuprite data in Figure 1.11(b) for experiments. It has been shown in Chang (2003a), Chang and Du (2004), and Chang et al. (2006) that a good VD estimate for the HYDICE data was nVD = 9 with PF equal to or smaller than 10−3 by the HFC method. By letting p = q = 9 Table 11.3 tabulates the extracted endmembers by PPI with K = 200, ATGP, VCA, ATGP-PPI, and ATGP-VCA that correspond to the five panel signatures in Figure 1.16.
Table 11.3 Endmembers extraction by PPI, ATGP, VCA, ATGP-PPI, and ATGP-VCA (HYDICE data)

According to Table 11.3, it is obvious that for PPI, ATGP-PPI, and ATGP-VCA to be able to extract all the five panel signatures ICA must be used to perform DR prior to endmember extraction except the case that VCA used alone with ICA as DR extracted only four not five panel signatures. More interestingly, without using ICA as DR none of PPI and VCA along with their ATGP versions could extract more than three panel signatures if any of PCA, MNF, and SVD was used to perform DR. This simple example demonstrates two important facts. One is that DR is a crucial preprocessing step for endmember extraction. The other is that endmembers can be better characterized by high-order statistics-based DR transforms than second-order statistics-based DR transforms.
As for Cuprite image scene in Figures 1.11(b) and 1.12 with reflectance data and radiance data it has been shown in Chang et al. (2006) and Chapter 4 that for the image with reflectance data nVD = 22 with PF = 10−4 is a good estimate for the number of endmembers, p = 22. In order to make a fair comparison, the same false alarm probability PF = 10−4 chosen for the image with reflectance data was also selected for the real image with radiance data, in which case the nVD = 15 according to Table 11.4.
Table 11.4 VD-estimated value for the Cuprite scene with various false alarm probabilities.

Tables 11.5 and 11.6 tabulate endmember pixels extracted by PPI, ATGP, and VCA along with two versions of the PPI and VCA using ATGP-generated pixels as initial endmembers, ATGP-PPI and ATGP-VCA, respectively, where four transforms, PCA, MNF, SVD, and ICA, were implemented for DR with q = 22 in Table 11.5 and q = 15 in Table 11.6. The results highlighted by shade in Tables 11.5 and 11.6 indicate that the algorithm failed to extract all the five mineral signatures.
Table 11.5 Endmembers extraction by PPI, ATGP, VCA, ATGP-PPI, and ATGP-VCA (reflectance data)

Table 11.6 Endmembers extraction by PPI, ATGP, VCA, ATGP-PPI, and ATGP-VCA (radiance data)

In analogy with synthetic image experiments the results obtained for real image data in Tables 11.5 and 11.6 also confirmed that the real image with radiance data were generally more difficult and challenging to deal with than the real image with reflectance data. Four interesting and intriguing findings are also observed in Tables 11.5 and 11.6.
Table 11.7 Endmembers extraction by ATGP, VCA, ATGP-PPI, and ATGP-VCA (radiance data)

In summary, this section investigates three seemingly different algorithms PPI, VCA, and ATGP, in endmember extraction and explores their relationships. The insights into such relationships are very enlightening. In particular, it has shown that VCA is nothing more than an orthogonal projection-based endmember extraction algorithm that can be considered as a variant of PPI and ATGP in either way. However, the connection of PPI to VCA is not clear until ATGP fits in between and bridges their gap. In doing so, this section re-interprets PPI, ATGP, and VCA from the principle of orthogonality. Most importantly, an in-depth study is also conducted to reveal close relationships among these three algorithms via orthogonal projection. Since both PPI and VCA use randomly generated vectors as their initial endmembers, two issues become evidential: (1) inconsistency in final results resulting from random initial conditions and (2) accurate number of endmembers, p. In order to address the first issue, two variants of PPI and VCA are also introduced in this chapter, called ATGP-PPI and ATGP-VCA that implements the ATGP as their initialization algorithm to produce a set of target pixels to be used as their initial endmembers. It is also interesting to note that the ATGP alone can also be considered as an initialization algorithm for any arbitrary EEA to produce a better set of initial endmembers. Finally, these five algorithms are further evaluated and compared via synthetic and real image experiments for performance analysis. The results showed that using such ATGP-generated target sample vectors as initial endmembers for any EEA resulted in only a small change in final selected set of endmembers. A surprising finding is that ATGP that is primarily developed for automatic target detection and classification indeed performed very well in endmember extraction and even outperformed VCA in most cases. A second surprising finding is that according to conducted experiments VCA did not perform as well as it was originally designed for. Similar observations are also demonstrated in Chang et al. (2006) and Wu et al. (2009).
Finally, if we further construct two p-vertex simplexes with their p vertices specified by the p endmembers obtained by ATGP and VCA, respectively, we can calculate their corresponding simplex volumes via (7.3) in comparison with the volume calculated from a simplex formed by the p endmembers generated by N-FINDR. If the volume of ATGP-generated simplex is close to that of N-FINDR-generated simplex, it implies that the p ATGP-generated endmembers can be considered as desired endmembers, even though these endmembers may not be the same as the endmembers generated by N-FINDR. Similarly, it can be also applied to VCA-generated simplex.