2.5 Conclusions
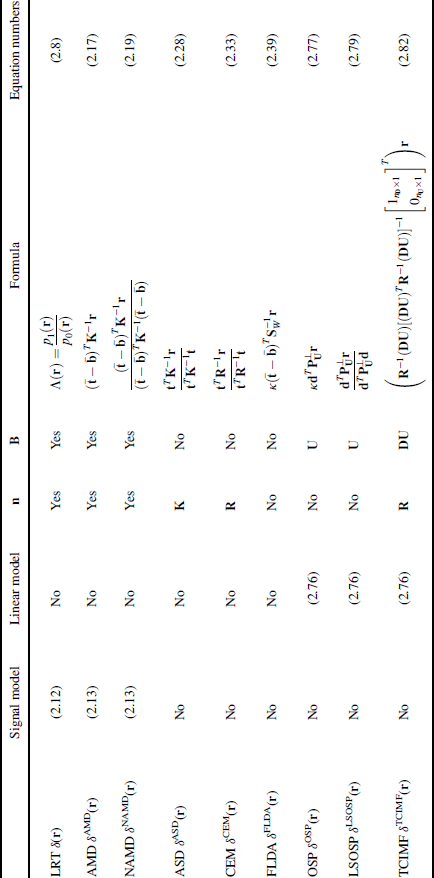
Subsample detection and mixed sample classification play central roles in hyperspectral image analysis. However, it seems that there is a lack of detailed treatment on decision issues of these two topics. Generally speaking, a subsample is a target sample of interest embedded in a sample with an unknown proportion while the remaining proportion of its embedded sample is considered as the background. On the other hand, a mixed sample comprises a set of known target signatures mixed linearly or nonlinearly in a sample. In light of this interpretation a major difference between a subsample and a mixed sample is that the background of a sample in which a subsample is embedded is unknown, while the background of a mixed sample is completely specified by other known target signatures. As a result, there is no background issue in a mixed sample and a mixed sample is generally performed by classification. By contrast, the background of a subsample is generally unknown and unspecified. Therefore, a subsample is usually performed by detection rather than by classification and the effectiveness of the subtarget detection is heavily determined by background suppression. Because of that this chapter is devoted to detection and classification via two types of decision-making processes, hard decisions and soft decisions, to address the issues of subsamples and mixed samples. As for detection, two approaches are reviewed. One is the likelihood ratio test using a threshold in terms of a cost function or the false alarm probability, which can be derived from a standard binary composite hypothesis testing approach that can be implemented as either pure sample detection or subsample detection. The other includes generalized LRT (GLRT)-based CFAR and the constrained energy minimization, both of which are developed for subsample detection with soft decisions. In analogy with detection, classification with hard and soft decisions is also considered. The classification with hard decisions is addressed by two pure sample-based classification techniques, FLDA and SVM, while classification with soft decisions is dealt by two mixed sample-based classification techniques, orthogonal subspace projection and target-constrained interference-minimization filter. Table 2.1 summarizes pure/subsample detectors and pure/mixed-sample classifiers presented in this chapter where κ, n, B, D, and U represent a scaling constant, noise, background, and desired and undesired signals, respectively and a “yes” or “no” indicates that the knowledge is required or not required. In addition, a “K” or an “R” indicates sample covariance or correlation matrix is required without knowing noise statistics. It should be noted that SVM is not included in Table 2.1 due to the fact that the training samples used in SVM are support vectors, which can be considered as worst samples for training. As a result, the mean of support vectors of each class cannot represent the mean of the class to which they belong. In this case, the target and/or background knowledge generated by these support vectors is not reliable and not representative.
Table 2.1 Summary of pure/subsample detectors and pure/mixed-sample classifiers.