
Web application fingerprinting is the first task for the penetration tester, to find out the version and type of a running web server, and the web technologies implemented. These allow attackers to determine known vulnerabilities and the appropriate exploits.
Attackers can utilize any type of command-line tool that has the capability to connect to the remote host. For example, we have used the netcat command in the following screenshot to connect to the victim host on port 80, and issued the HTTP HEAD command to identify what is being run on the server:
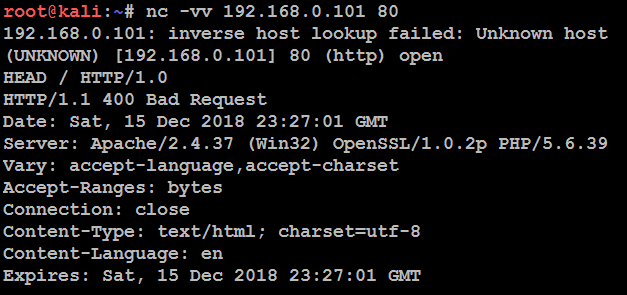
This returns an HTTP server response that includes the type of web server that the application is being run on, and the server section providing detailed information about the technology used to build the app—in this case, PHP 5.6.39.
Now, the attackers can determine known vulnerabilities using sources such as CVE Details (see https://www.cvedetails.com/vulnerability-list/vendor_id-74/product_id-128/PHP-PHP.html).
The ultimate goal of penetration testing is to obtain sensitive information. The website should be inspected to determine the Content Management System (CMS) that has been used to build and maintain it. CMS applications such as Drupal, Joomla, and WordPress, among others, may be configured with a vulnerable administrative interface that allows access to elevated privileges, or may contain exploitable vulnerabilities.
Kali includes an automated scanner, BlindElephant, which fingerprints a CMS to determine version information, as follows:
BlindElephant.py <website.com> joomla
A sample output is shown in the following screenshot:

BlindElephant reviews the fingerprint for components of the CMS, and then provides a best guess for the versions that are present. However, as with other applications, we have found that it may fail to detect a CMS that is present; therefore, always verify results against other scanners that crawl the website for specific directories and files, or manually inspect the site.
One particular scanning tool, automated web crawlers, can be used to validate information that has already been gathered, as well as to determine the existing directory and file structure of a particular site. Typical findings of web crawlers include administration portals, configuration files (current and previous versions) that may contain hardcoded access credentials and information on the internal structure, backup copies of the website, administrator notes, confidential personal information, and source code.
Kali supports several web crawlers, including Free Burp Suite, DirBuster, OWASP-ZAP, Vega, WebScarab, and WebSlayer. The most commonly used tool is DirBuster.
DirBuster is a GUI-driven application that uses a list of possible directories and files to perform a brute-force analysis of a website's structure. Responses can be viewed in a list or a tree format that reflects the site's structure more accurately. Output from executing this application against a target website is shown in the following screenshot:
