
3.3 Representing Text
A text document can be decomposed into paragraphs, sentences, words, and ultimately individual characters. To represent a text document in digital form, we simply need to be able to represent every possible character that may appear. The document is the continuous (analog) entity, and the separate characters are the discrete (digital) elements that we need to represent and store in computer memory.
At this point, we should distinguish between the basic idea of representing text and the more involved concept of word processing. When we create a document in a word processing program such as Microsoft® Word, we can specify all kinds of formatting: fonts, margins, tabs, color, and so on. Such programs also let us add art, equations, and other elements. This extra information is stored along with the rest of the text so that the document can be displayed and printed the way you want it. The core issue, however, is the way we represent the characters themselves; therefore, those techniques remain our focus at this point.
There are a finite number of characters to represent. The general approach for representing characters is to list all of them and then assign a binary string to each character. For example, to store a particular letter, we store the appropriate bit string.
So which characters do we need to represent? The English language includes 26 letters. But uppercase and lowercase letters have to be treated separately, so that’s really 52 unique characters. Punctuation characters also have to be represented, as do the numeric digits (the actual characters ‘0’, ‘1’, through ‘9’). Even the space character must have a representation. And what about languages other than English? The list of characters we may want to represent starts to grow quickly once you begin to think about it. Keep in mind that, as we discussed earlier in this chapter, the number of unique things (characters, in this case) we want to represent determines how many bits we’ll need to represent any one of them.
A character set is simply a list of characters and the codes used to represent each one. Several character sets have been used over the years, though a few have dominated. By agreeing to use a particular character set, computer manufacturers have made the processing of text data easier. We explore two character sets in the following sections: ASCII and Unicode.
The ASCII Character Set
ASCII stands for American Standard Code for Information Interchange. The ASCII character set originally used seven bits to represent each character, allowing for 128 unique characters. The eighth bit in each character byte was originally used as a check bit, which helped ensure proper data transmission. Later ASCII evolved so that all eight bits were used to represent a character. This eight-bit version is formally called the Latin-1 Extended ASCII character set. The extended ASCII set allows for 256 characters and includes accented letters as well as several other special symbols. FIGURE 3.5 shows the ASCII character set.
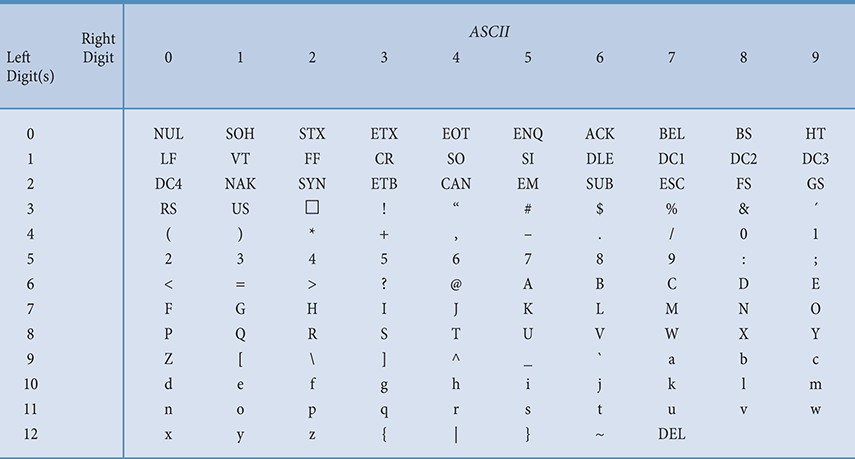
FIGURE 3.5 The ASCII character set
The codes in Figure 3.5 are expressed as decimal numbers, but these values get translated to their binary equivalent for storage in the computer. Note that the ASCII characters have a distinct order based on the codes used to store them. Each character has a relative position (before or after) every other character. This property is helpful in several different ways. For example, note that both the uppercase and lowercase letters are in order. Therefore, we can use the character codes to help us put a list of words into alphabetical order.
The first 32 characters in the ASCII character chart do not have a simple character representation that you could print to the screen. These characters are reserved for special purposes, such as carriage return and tab. They are usually interpreted in special ways by whatever program is processing the data.
The Unicode Character Set
The extended version of the ASCII character set provides 256 characters, which is enough for English but not enough for international use. This limitation gave rise to the Unicode character set, which has a much stronger international influence.
The goal of the people who created Unicode is nothing less than to represent every character in every language used in the entire world, including all of the Asian ideograms. It also represents many special-purpose characters such as scientific symbols.
The Unicode character set is used by many programming languages and computer systems today. In general, the encoding uses 16 bits per character, but is flexible so that it can use more space per character if needed to represent additional characters. FIGURE 3.6 shows a few characters from the non-ASCII portion of the Unicode character set.

FIGURE 3.6 A few characters in the Unicode character set
For consistency, Unicode was designed to be a superset of ASCII. That is, the first 256 characters in the Unicode character set correspond exactly to the extended ASCII character set, including the codes used to represent them. Therefore, programs that assume ASCII values are unaffected even if the underlying system embraces the Unicode approach.
Text Compression
Alphabetic information (text) is a fundamental type of data. Therefore, it is important that we find ways to store and transmit text efficiently between one computer and another. The following sections examine three types of text compression:
Keyword encoding
Run-length encoding
Huffman encoding
As we discuss later in this chapter, some of the ideas underlying these text compression techniques come into play when dealing with other types of data as well.
Keyword Encoding
Consider how often you use words such as “the,” “and,” “which,” “that,” and “what.” If these words took up less space (that is, had fewer characters), our documents would shrink in size. Even though the savings for each word would be small, they are used so often in a typical document that the combined savings would add up quickly.
One fairly straightforward method of text compression is keyword encoding, in which frequently used words are replaced with a single character. To decompress the document, you reverse the process: You replace the single characters with the appropriate full word.
For example, suppose we used the following chart to encode a few words:
| WORD | SYMBOL |
| as | ^ |
| the | ~ |
| and | + |
| that | $ |
| must | & |
| well | % |
| these | # |
Let’s encode the following paragraph:
The human body is composed of many independent systems, such as the circulatory system, the respiratory system, and the reproductive system. Not only must all systems work independently, but they must interact and cooperate as well. Overall health is a function of the well-being of separate systems, as well as how these separate systems work in concert.
The encoded paragraph is:
The human body is composed of many independent systems, such ^ ~ circulatory system, ~ respiratory system, + ~ reproductive system. Not only & each system work independently, but they & interact + cooperate ^ %. Overall health is a function of ~ %-being of separate systems, ^ % ^ how # separate systems work in concert.
There are a total of 352 characters in the original paragraph, including spaces and punctuation. The encoded paragraph contains 317 characters, resulting in a savings of 35 characters. The compression ratio for this example is 317/352 or approximately 0.9.
There are several limitations to keyword encoding. First, note that the characters we use to encode the keywords cannot be part of the original text. If, for example, the ‘$’ were part of the original paragraph, the resulting encoding would be ambiguous. We wouldn’t know whether ‘$’ represented the word “that” or if it was the actual dollar-sign character. This limits the number of words we can encode as well as the nature of the text that we are encoding.
Also, note that the word “The” in the example is not encoded by the ‘~’ character because the word “The” and the word “the” contain different letters. Remember, the uppercase and lowercase versions of the same letter are different characters when it comes to storing them on a computer. We would have to use a separate symbol for “The” if we wanted to encode it—or employ a more sophisticated substitution scheme.
Finally, note that we would not gain anything by encoding words such as “a” and “I” because that would simply be replacing one character for another. The longer the word, the more compression we get per word. Unfortunately, the most frequently used words are often short. Of course, some documents use certain words more frequently than others depending on the subject matter. For example, we would have realized some nice savings if we had chosen to encode the word “system” in our example, but it might not be worth encoding in a general situation.
An extension of keyword encoding is to replace specific patterns of text with special characters. The encoded patterns are generally not complete words, but rather parts of words such as common prefixes and suffixes—“ex,” “ing,” and “tion,” for instance. An advantage of this approach is that patterns being encoded generally appear more often than whole words (because they occur in many different words). A disadvantage is that they are generally short patterns and, therefore, the replacement savings per word is small.
Run-Length Encoding
In some situations, a single character may be repeated over and over again in a long sequence. This type of repetition doesn’t generally take place in English text, but often occurs in large data streams, such as DNA sequences. A text compression technique called run-length encoding capitalizes on these situations. Run-length encoding is sometimes called recurrence coding.
In run-length encoding, a sequence of repeated characters is replaced by a flag character, followed by the repeated character, followed by a single digit that indicates how many times the character is repeated. For example, consider the following string of seven repeated ‘A’ characters:
AAAAAAA
If we use the ‘*’ character as our flag, this string would be encoded as
*A7
The flag character indicates that the series of three characters (including the flag) should be decoded into the appropriate repetitious string. All other text is treated regularly. Therefore, the encoded string
*n5*x9ccc*h6 some other text *k8eee
would be decoded into the following original text:
nnnnnxxxxxxxxxccchhhhhh some other text kkkkkkkkeee
The original text contains 51 characters and the encoded string contains 35 characters, giving us a compression ratio in this example of 35/51, or approximately 0.68.
In this example the three repeated ‘c’ characters and the three repeated ‘e’ characters are not encoded. Because it takes three characters to encode a repetition sequence, it is not worth it to encode strings of two or three. In fact, in the case of two repeated characters, encoding would actually make the string longer!
Given that we are using one character for the repetition count, it seems that we can’t encode repetition lengths greater than nine. But keep in mind that each character is represented by a series of bits based on some character set. For example, the character ‘5’ is represented as ASCII value 53, which in an eight-bit binary string is 00110101. So, instead of interpreting the count character as an ASCII digit, we could interpret it as a binary number. We can then have repetition counts between 0 and 255, or even between 4 and 259, because runs of three or less are not represented.
Huffman Encoding
Another text compression technique, called Huffman encoding, is named after its creator, Dr. David Huffman. Why should the character “X,” which is seldom used in text, take up the same number of bits as the blank, which is used very frequently? Huffman codes address this question by using variable-length bit strings to represent each character. That is, a few characters may be represented by five bits, another few by six bits, yet another few by seven bits, and so forth. This approach is contrary to the idea of a character set, in which each character is represented by a fixed-length bit string (such as 8 or 16).
The idea behind this approach is that if we use only a few bits to represent characters that appear often and reserve longer bit strings for characters that don’t appear often, the overall size of the document being represented is small.
For example, suppose we use the following Huffman encoding to represent a few characters:
| Huffman Code | Character |
| 00 | A |
| 01 | E |
| 100 | L |
| 110 | O |
| 111 | R |
| 1010 | B |
| 1011 | D |
Then the word “DOORBELL” would be encoded in binary as
1011110110111101001100100
If we used a fixed-size bit string to represent each character (say, 8 bits), then the binary form of the original string would be 8 characters times 8 bits, or 64 bits. The Huffman encoding for that string is 25 bits long, giving a compression ratio of 25/64, or approximately 0.39.
What about the decoding process? When we use character sets, we just take the bits in chunks of 8 or 16 bits to see what character the chunk represents. In Huffman encoding, with its variable-length codes, it seems as if we might get confused when trying to decode a string because we don’t know how many bits we should include for each character. In fact, that potential source of confusion has been eliminated by the way the codes are created.
An important characteristic of any Huffman encoding is that no bit string used to represent a character is the prefix of any other bit string used to represent a character. Therefore, as we scan from left to right across a bit string, when we find a string that corresponds to a character, that must be the character it represents. It can’t be part of a larger bit string.
For example, if the bit string
1010110001111011
is created with the previous table, it must be decoded into the word “BOARD.” There is no other possibility.
So how is a particular set of Huffman codes created? The details of that process are a bit beyond the scope of this book, but let’s discuss the underlying issue. Because Huffman codes use the shortest bit strings for the most common characters, we start with a table that lists the frequency of the characters we want to encode. Frequencies may come from counting characters in a particular document (352 E’s, 248 S’s, and so on) or from counting characters in a sample of text from a particular content area. A frequency table may also come from a general idea of how frequently letters occur in a particular language such as English. Using those values, we can construct a structure from which the binary codes can be read. The way the structure is created ensures that the most frequently used characters get the shortest bit strings.