
9.4 Functionality in High-Level Languages
Two pseudocode constructs—selection and repetition (looping)—are hallmarks of imperative languages. In Chapter 6, we implemented these constructions in assembly language, showing how detailed the instructions had to be. We also examined these constructs along with subprograms in pseudocode. In high-level languages, selection and repetition are very easy. Subprograms and parameter passing, however, are more complicated.
First, we review the concept of a Boolean expression, which is the construct that high-level languages use to make choices. We then examine other constructs that high-level languages provide to make programming easier and safer.
Boolean Expressions
In Chapter 6, we wrote an algorithm to read in pairs of numbers and print them in order. It contained a selection statement within a loop. Here is the outline of the loop with the selection statement:
Each of these statements asks a question. Notice how these questions are phrased:
Each phrase is actually a statement. If the statement is true, the answer to the question is true. If the statement is not true, the answer to the question is false. Making statements and then testing whether they are true or false is how programming languages ask questions. These statements are called assertions or conditions. When we write algorithms, we make assertions in English-like statements. When the algorithms are translated into a high-level programming language, the English-like statements are rewritten as Boolean expressions.
What is a Boolean expression? In Chapter 4, we introduced the concept of Boolean operations when we discussed gates and circuits. Here we are using them at the logical level rather than the hardware level. A Boolean expression is a sequence of identifiers, separated by compatible operators, that evaluates to either true or false. A Boolean expression can be any of the following.
■ A Boolean variable
■ An arithmetic expression followed by a relational operator followed by an arithmetic expression
■ A Boolean expression followed by a Boolean operator followed by a Boolean expression
So far in our examples, variables have contained numeric values. A Boolean variable is a location in memory that is referenced by an identifier that can contain either true or false. (When referring to code in a specific language or to what is actually stored in memory, we use a mono-space, or code, font.)
A relational operator is one that compares two values. The six relational operators are summarized in the following chart, along with the symbols that various high-level languages use to represent the relation.
A relational operator between two arithmetic expressions is asking if the relationship exists between the two expressions. For example,
xValue < yValue
is making the assertion that xValue is less than yValue. If xValue is less than yValue, then the result of the expression is true; if xValue is not less than yValue, then the result is false.
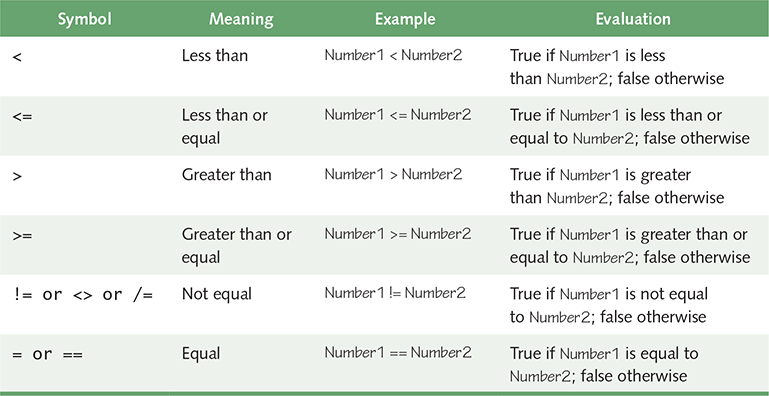
To avoid the confusion over the use of = and == to mean equality in different programming languages, we have used the word “equals” rather than choosing one of the symbols in our algorithms.
Recall that the three Boolean operators are the special operators AND, OR, and NOT. The AND operator returns true if both expressions are true and false otherwise. The OR operator returns false if both expressions are false and true otherwise. The NOT operator changes the value of the expression.
Data Typing
When working in an assembly language, we assign identifiers to memory locations with no regard as to what is to be stored into the locations. Many widely used, high-level languages (including both C++ and Java) require you to state what can be stored in a place when you associate it with an identifier. If a statement in a program tries to store a value into a variable that is not the proper type, an error message is issued. The requirement that only a value of the proper type can be stored into a variable is called strong typing.
For example, look at the following 8 bits: 00110001. What does it represent? It is a byte in memory. Yes, but what does it mean? Well, it could be the binary representation of the decimal number 49. It could also be the extended ASCII representation of the character ‘1’. Could it mean anything else? Yes, it could be the Pep/9 instruction specifier for the DCI direct mode trap instruction. Thus, when a program is executing, it must know how to interpret the contents of a place in memory.
In the next sections, we look at common types of data values and explore how high-level languages allow you to associate locations with identifiers. Each of these data types has certain operations that legally can be applied to values of the type. A data type is a description of the set of values and the basic set of operations that can be applied to values of the type.
Of the languages we explore, C++, Java, and VB .NET are strongly typed; Python is not.
Data Types
Data are the physical symbols that represent information. Inside a computer, both data and instructions are just binary bit patterns. The computer executes an instruction because the address of the instruction is loaded into the program counter and the instruction is then loaded into the instruction register. The same bit pattern that is executed can also represent an integer number, a real number, a character, or a Boolean value. The key is that the computer interprets the bit pattern to be what it expects it to be.
For example, in Pep/9 the instruction for Stop is a byte of all zero bits. When this instruction is loaded into the instruction register, the program halts. A byte of all zero bits can also be interpreted as an 8-bit binary number containing the value 0 (zero). If the location containing all zero bits is added to the contents of a register, the value is interpreted as a number.
Most high-level languages have four distinct data types built into the language: integer numbers, real numbers, characters, and Boolean values.
Integers
The integer data type represents a range of integer values, from the smallest to the largest. The range varies depending on how many bytes are assigned to represent an integer value. Some high-level languages provide several integer types of different sizes, which allows the user to choose the one that best fits the data in a particular problem.
The operations that can be applied to integers are the standard arithmetic and relational operators. Addition and subtraction are represented by the standard symbols + and −. Multiplication and division are usually represented by * and /. Depending on the language, integer division may return a real number or the integer quotient. Some languages have two symbols for division: one that returns a real result and one that returns the integer quotient. Most languages also have an operator that returns the integer remainder from division. This operator is called the modulus operator, but it may or may not act as the mathematical modulus operator. The relational operators are represented by the symbols shown in the table in the previous section.
Reals
The real data type also represents a range from the smallest to the largest value with a given precision. Like the integer data type, the range varies depending on the number of bytes assigned to represent a real number. Many high-level languages have two sizes of real numbers. The operations that can be applied to real numbers are the same as those that can be applied to integer numbers. However, you must be careful when applying the relational operators to real values, because real numbers are often not exact. For example, 1/3 + 1/3 + 1/3 in computer arithmetic is not necessarily 1.0. In fact, 1/10 * 10 is not 1.0 in computer arithmetic.
Characters
In Chapter 3, we said that a mapping of the ASCII character set to code requires only one byte. One commonly used mapping for the Unicode character set uses two bytes. In this mapping, our English alphabet is represented in ASCII, which is a subset of Unicode. Applying arithmetic operations to characters doesn’t make much sense, and many strongly typed languages will not allow you to do so. However, comparing characters does make sense, so the relational operators can be applied to characters. The meanings of “less than” and “greater than,” when applied to characters, are “comes before” and “comes after,” respectively, in the character set. Thus the character ‘A’ is less than ‘B’, ‘B’ is less than ‘C’, and so forth. Likewise, the character ‘1’ (not the number) is less than ‘2’, ‘2’ is less than ‘3’, and so forth. If you want to compare ‘A’ to ‘1’, you must look up the relationship between these two characters in the character set you are using.
Boolean
As we said in the previous section, the Boolean data type consists of two values: true and false. We can also assign a Boolean expression to a Boolean variable. Here is the pairs program using Boolean variables:
Integers, reals, characters, and Booleans are called simple or atomic data types, because each value is distinct and cannot be subdivided into parts. In the last chapter, we discussed composite data types—that is, data types made up of a collection of values. The string data type has some of the properties of a composite type but is often considered a simple data type.
Strings
A string is a sequence of characters that in some languages can be considered as one data value. For example,
“This is a string.”
is a string containing 17 characters: 1 uppercase letter, 12 lowercase letters, 3 blanks, and a period. The operations defined on strings vary from language to language, but often include a concatenation of strings and a comparison of strings in terms of lexicographic order. Other languages provide a complete array of operations, such as taking a substring of a given string or searching a given string for a substring.
Note that we have used single quotes to enclose characters and double quotes to enclose strings. Some high-level languages use the same symbol for both, thus not distinguishing between a character and a string with one character.
Declarations
A declaration is a language statement that associates an identifier with a variable, an action, or some other entity within the language that can be given a name so that the programmer can refer to that item by name. In this section we discuss how a variable is declared. Later we look at how actions are given names.

These examples illustrate some differences among high-level languages. For example, VB .NET uses a reserved word to signal a declaration. A reserved word is a word in a language that has special meaning; it cannot be used as an identifier. Dim is a reserved word in VB .NET used to declare variables. C++ and Java do not use a reserved word for this purpose.
C++ and Java use the semicolon to end a statement in the language. VB .NET uses the end of the line or the comment symbol to end the statement. Python programs do not require declarations because Python is not a strongly typed language. Python uses the pound sign (#) as the beginning of a comment that extends to the end of the line. Recall that Pep/9 uses a semicolon to signal that what follows is a comment.
C++, Java, Python, and VB .NET are case sensitive, which means that two copies of the same identifier, when capitalized differently, are considered different words. Thus, Integer, INTEGER, InTeGeR, and INTeger are considered four different identifiers in case-sensitive languages. C++, Java, and VB .NET have a collection of type names for various sizes of integer and real numbers. Although Python does not declare identifiers, it does have the reserved words long, int, float, and bool.
Are these differences important? They are if you are writing a program in one of these languages. However, they are just syntactic issues— that is, different ways of doing the same thing. The important concept is that an identifier is associated with a place in memory and may or may not be associated with a data type. In the exercises, we ask you to compare the syntactic differences that surface in these examples.
The use of uppercase and lowercase in identifiers is part of the culture of a language. In our examples, we have tried to stick with the style that is common within the language’s culture. For example, most C++ programmers begin variable names with lowercase and subprograms with uppercase, while VB .NET programmers tend to begin variable names with uppercase letters.
Input/Output Structures
In our pseudocode algorithms, we have used the expressions Read and Write or Print to indicate that we were interacting with the environment outside the program. Read was for getting a value from outside the program and storing it into a variable inside the program, and Write and Print were for displaying a message for the human to see.
High-level languages view text data as a stream of characters divided into lines. How the characters are interpreted depends on the data types of the places into which the values are to be stored. Any input statement has three parts: the declaration of the variables into which data will be placed, the input statement with the names of the variables to be read, and the data stream itself. As an example, let’s look at the pseudocode algorithm to input three values:
In a strongly typed language, the variables name, age, and hourlyWage would have to be declared, along with their respective data types. Let’s assume the types are string, integer, and real. The input statement would list the three variables. Processing would proceed as follows. The first data item on the input stream would be assumed to be a string, because name is of type string. The string would be read and stored into name. The next variable is an integer, so the read operation expects to find an integer next in the input stream. This value is read and stored in age. The third variable is a real number, so the read operation expects to find a real value next on the input stream to be stored as hourlyWage.
The input stream may be from the keyboard or a data file, but the process is the same: The order in which the variables are listed in the input statement must be the same as the order in which the values occur in the input stream. The types of the variables being input determine how the characters in the input stream are interpreted. That is, the input stream is just a series of ASCII (or Unicode) characters. The type of the variable into which the next value is to be stored determines how a sequence of characters is interpreted. For simplicity, let’s assume that the input statement believes that a blank separates each data value. For example, given the data stream
Maggie 10 12.50“Maggie” would be stored in name, 10 would be stored in age, and 12.50 would be stored in hourlyWage. Both 10 and 12.50 are read in as characters and converted to type integer and real, respectively.
In a language that is not strongly typed, the format of the input determines the type. If the input appears between quotes, it is assumed to be a string and is stored that way. If the input is a number, it is stored that way.
Output statements create streams of characters. The items listed on the output statement can be literal values or variable names. Literal values are numbers or strings written explicitly in the output statement (or any statement, for that matter). The values to be output are processed one at a time by looking at the type of the identifier or literal. The type determines how the bit pattern is to be interpreted. If the type is a string, the characters are written into the output stream. If the bit pattern is a number, the number is converted to the characters that represent the digits and the characters are written out.
In a strongly typed language, regardless of the syntax of input/output statements or where the input/output streams are, the key to the processing lies in the data type that determines how characters are to be converted to a bit pattern (input) and how a bit pattern is to be converted to characters (output). In a language that is not strongly typed, the format of the input itself determines how the bit pattern is to be converted.
Here are input and output statements in the four languages we are using for demonstrations. The prompts are omitted. The input statements are in black; the output statements are in green.

Control Structures
Our pseudocode provided three ways to alter the flow of control of the algorithm: repetition, selection, and subprogram. These constructs are called control structures because they determine the order in which other instructions in a program are executed.
In the seminal article “Notes on Structured Programming,” published in 1972, Edsger W. Dijkstra pointed out that programmers should be precise and disciplined—in other words, they should use only selected control structures. This article and the others published with it introduced the era of structured programming.10 According to this view, each logical unit of a program should have just one entry and one exit. The program should not jump randomly in and out of logical modules. Although programs could be designed in this way in assembly language using instructions that branch to other parts of the program, high-level languages introduced control constructs that made this discipline easy to follow. These constructs are selection statements, looping statements, and subprogram statements. With this approach, unrestricted branching statements are no longer necessary.
In our pseudocode algorithms, we used indention to group statements within the body of an if statement or a while statement. Python uses indention, but the other languages use actual markers. VB .NET uses End If and End While to end the corresponding statements. Java and C++ use braces ({}).
The following tables show code segments using if and while statements in the demonstration languages.


The following table shows how VB .NET and C++ define a subprogram that does not return a single value. In this example, there are two integer value parameters and one real reference parameter. Again, this illustration is meant to give you a hint of the rich variety of syntax that abounds in high-level languages, not to make you competent in writing this construct in any of them. The ampersand (&) used in C++ is not a typographical error; it signals that three is a reference parameter.
| Language | Subprogram Declaration |
VB .NET |
Public Sub Example(ByVal one As Integer,ByVal two As Integer,ByRef three As Single)...End Sub |
C++ |
void Example(int one, int two, float& three) |
We do not show a Java or Python example because they handle memory very differently, allowing only value parameters.
Nested Logic
The statements to be executed or skipped in any control statement can be simple statements or blocks (compound statements)—there is no constraint on what these statements can be. In fact, the statement to be skipped or repeated can contain a control structure. Selection statements can be nested within looping structures; looping structures can be nested within selection statements. Selection and looping statements can be nested within subprograms, and subprogram calls can be nested within looping or selection structures.
We have looked at nesting in our algorithms, but the topic is worth another look. Take, for example, the algorithm that counts and sums ten positive numbers in a file:
The selection control structure is embedded within a looping control structure. If we wanted to sum and print weekly rainfall figures for a year, we would have the following nested looping structures:
Control structures within control structures within control structures . . . Theoretically, there is no limit to how deeply control structures can be nested! However, if the nesting becomes too difficult to follow, you should give the nested task a name and make it a subprogram, giving its implementation later. For example, examine the alternative version of the preceding pseudocode algorithm. Which is easier to follow?
Asynchronous Processing
You have likely grown up using a graphical user interface (GUI) that relies on the use of a mouse to manipulate multiple window frames on a screen. Clicking has become a major form of input to the computer. In fact, for many applications, filling in boxes and clicking buttons to say the input is ready has become the only form of input.
In traditional stream processing, an input statement is executed in the sequence in which it is encountered. Here are the first four statements in the algorithm shown earlier:
We expect these statements to be executed in sequence. Output is written to a window, a value is read from the input stream, another value is stored, and the while loop is executed. Stream input and output is within the sequential flow of the program.
Mouse clicking, in contrast, does not occur within the sequence of the program. That is, a user can click a mouse at any time during the execution of a program. The program must recognize when a mouse click has occurred, process the mouse click, and then continue. This type of processing is called asynchronous, which means “not at the same time.” The mouse can be clicked at any time; it is not synchronized with any other instructions.
Asynchronous processing is also called event-driven processing. In other words, the processing is under the control of events happening outside the sequence of program instructions.
Asynchronous processing is used frequently in Java and VB .NET but less often in the other languages.