
13.2 Knowledge Representation
The knowledge we need to represent an object or event varies based on the situation. Depending on the problem we are trying to solve, we need specific information. For example, if we are trying to analyze family relationships, it’s important to know that Fred is Cathy’s father, but not that Fred is a plumber or that Cathy owns a pickup truck. Furthermore, not only do we need particular information, but we also need it in a form that allows us to search and process that information efficiently.
There are many ways to represent knowledge. For example, we could describe it in natural language. That is, we could write an English paragraph describing, for instance, a student and the ways in which the student relates to the world. However, although natural language is very descriptive, it doesn’t lend itself to efficient processing. Alternatively, we could formalize the language, by describing a student using an almost mathematical notation. This formalization lends itself to more rigorous computer processing, but it is difficult to learn and use correctly.
In general, we want to create a logical view of the data, independent of its actual underlying implementation, so that it can be processed in specific ways. In the world of artificial intelligence, the information we want to capture often leads to new and interesting data representations. We want to capture not only facts, but also relationships. The kind of problem we are trying to solve may dictate the structure we impose on the data.
As specific problem areas have been investigated, new techniques for representing knowledge have been developed. We examine two in this section: semantic networks and search trees.
Semantic Networks
A semantic network is a knowledge representation technique that focuses on the relationships between objects. A directed graph is used to represent a semantic network or net. The nodes of the graph represent objects, and the arrows between nodes represent relationships. The arrows are labeled to indicate the types of relationships that exist.
Semantic nets borrow many object-oriented concepts, which were discussed in Chapter 9, including inheritance and instantiation. An inheritance relationship indicates that one object is-a more specific version of another object. Instantiation is the relationship between an actual object and something that describes it (like a class).
Examine the semantic network shown in FIGURE 13.3. It has several is-a relationships and several instance-of relationships. But it also has several other types of relationships, such as lives-in (John lives in Heritage Acres). There are essentially no restrictions on the types of relationships that can be modeled in a semantic network.
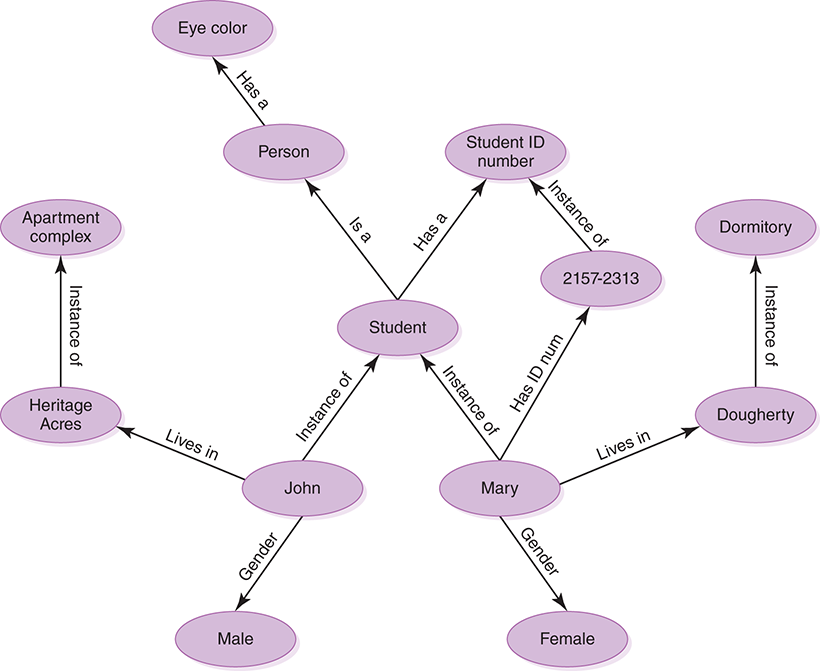
FIGURE 13.3 A semantic network
Many more relationships could be represented in this semantic net. For instance, we could have indicated that any person is either left- or right-handed, that John owns a car that is a Honda, or that every student has a grade point average. The relationships that we represent are completely our choice, based on the information we need to answer the kinds of questions that we will face.
The way in which we establish the relationships can vary as well. For example, instead of showing that individual students live in particular dwellings, we could show that dwellings house certain people. In other words, we could turn those arrows around, changing the lives-in relation-ship to a houses relationship. Again, the choice is ours as we design the network. Which approach best describes the kind of issues we address? In some situations we may choose to represent both relationships.
The types of relationships represented determine which questions are easily answered, which are more difficult to answer, and which cannot be answered. For example, the semantic net in Figure 13.3 makes it fairly simple to answer the following questions:
Is Mary a student?
What is the gender of John?
Does Mary live in a dorm or an apartment?
What is Mary’s student ID number?
However, the following questions are more difficult to answer with this network:
How many students are female and how many are male?
Who lives in Dougherty Hall?
Note that the information to answer these questions is present in the network; it’s just not as easy to process. These last questions require the ability to easily find all students, and there are no relationships that make this information easy to obtain. This network is designed more for representing the relationships that individual students have to the world at large.
This network cannot be used to answer the following questions, because the knowledge required is simply not represented:
What kind of car does John drive?
What color are Mary’s eyes?
We know that Mary has an eye color, because she is a student, all students are people, and all people have a particular eye color. We just don’t know what Mary’s particular eye color is, given the information stored in this network.
A semantic network is a powerful, versatile way to represent a lot of information. The challenge is to model the right relationships and to populate (fill in) the network with accurate and complete data.
Search Trees
In Chapter 8, we mentioned the use of tree structures to organize data. Such structures play an important role in artificial intelligence. For example, we can use a tree to represent possible alternatives in adversarial situations, such as game playing.
A search tree is a structure that represents all possible moves in a game, for both you and your opponent. You can create a game program that maximizes its chances to win. In some cases it may even be able to guarantee a win.
In search trees, the paths down a tree represent the series of decisions made by the players. A decision made at one level dictates the options left to the next player. Each node of the tree represents a move based on all other moves that have occurred thus far in the game.
Let’s define a simplified variation of a game called Nim to use as an example. In our version, there are a certain number of spaces in a row. The first player may place one, two, or three Xs in the leftmost spaces. The second player may then place one, two, or three Os immediately adjacent to the Xs. Play continues back and forth. The goal is to place your mark in the last (rightmost) space.
Here is an example of a play of our version of Nim using nine spaces:
| Initial: | _ _ _ _ _ _ _ _ _ | |
| Player 1: | X X X _ _ _ _ _ _ | |
| Player 2: | X X X O _ _ _ _ _ | |
| Player 1: | X X X O X _ _ _ _ | |
| Player 2: | X X X O X O O _ _ | |
| Player 1: | X X X O X O O X X | Player 1 wins. |
The search tree in FIGURE 13.4 shows all possible moves in our version of the game using only five spaces (rather than the nine spaces used in the preceding example). At the root of the tree, all spaces are initially empty. The next level shows the three options the first player has (to place one, two, or three Xs). At the third level, the tree shows all options that Player 2 has, given the move that Player 1 already made.
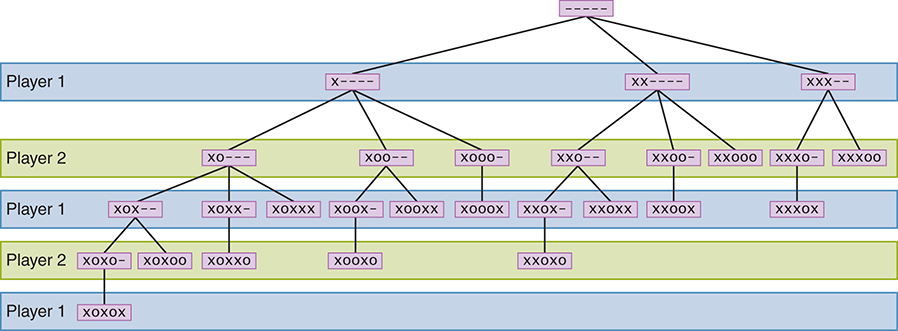
FIGURE 13.4 A search tree for a simplified version of Nim
Note that when a large number of marks are made in one turn, fewer options may be available to the next player, and the paths down the tree tend to be shorter. Follow the various paths down from the root, noting the different options taken by each player. Every single option in our simplified game is represented in this tree.
We’ve deliberately simplified the game of Nim so that we can show a simple search tree. The real game of Nim has some important differences— for example, there are multiple rows, and items are removed instead of added. However, even our simplified version demonstrates several interesting mathematical ideas.
The concepts of search tree analysis can be applied nicely to other, more complicated games such as chess. In such complex games the search trees are far more complicated, having many more nodes and paths. Think about all the possible moves you might initially make in a chess game. Then consider all the possible moves your opponent might make in response. A full chess search tree contains all possible moves at each level, given the current status of the board. Because these trees are so large, only a fraction of the tree can be analyzed in a reasonable time limit, even with modern computing power.
As machines have become faster, more of the search tree can be analyzed, but still not all of the branches. Programmers have come up with ways to “prune” the search trees, eliminating paths that no human player would consider reasonable. Even so, the trees are too large to completely analyze for each move.
This leaves us with a question: Do we choose a depth-first approach, analyzing selective paths all the way down the tree that we hope will result in successful moves? Or do we choose a breadth-first approach, analyzing all possible paths but only for a short distance down the tree? Both approaches, shown in FIGURE 13.5, may miss key possibilities. While this issue has been debated among AI programmers for many years, a breadth-first approach tends to yield the best results. It seems that it’s better to make consistently error-free conservative moves than to occasionally make spectacular moves.

FIGURE 13.5 Depth-first and breadth-first searches
Programs that play chess at the master level have become commonplace. In 1997, the computer chess program Deep Blue, developed by IBM using an expert system, defeated world champion Garry Kasparov in a six-game match. This event marked the first time a computer had defeated a human champion at master-level play.