
7.7 Important Threads
In the last two chapters, we have mentioned several topics in passing that are important not only in problem solving but also in computing in general. Let’s review some of the common threads discussed in these chapter.
Information Hiding
We have mentioned the idea of deferring the details several times. We have used it in the context of giving a name to a task and not worrying about how the task is to be implemented until later. Deferring the details in a design has distinct advantages. The designer sees just those details that are relevant at a particular level of the design. This practice, called information hiding, makes the details at a lower level inaccessible during the design of the higher levels.
This practice must seem very strange! Why shouldn’t the details be accessible while the algorithm is being designed? Shouldn’t the designer know everything? No. If the designer knows the low-level details of a module, he or she is more likely to base the module’s algorithm on these details—and it is precisely these low-level details that are more likely to change. If they do, then the entire module has to be rewritten.
Abstraction
Abstraction and information hiding are two sides of the same coin. Information hiding is the practice of hiding details; abstraction is the result with the details hidden. As we said in Chapter 1, an abstraction is a model of a complex system that includes only the details that are essential for the viewer to know. Take, for example, Daisy, the English spaniel. To her owner, she is a household pet; to a hunter, she is a bird dog; and to the vet, she is a mammal. Her owner watches Daisy’s wagging tail, hears her yelp when she gets left outside, and sees the hair she leaves everywhere. The hunter sees a finely trained helper who knows her job and does it well. The vet sees all of the organs, flesh, and bones of which she is composed. See FIGURE 7.17.
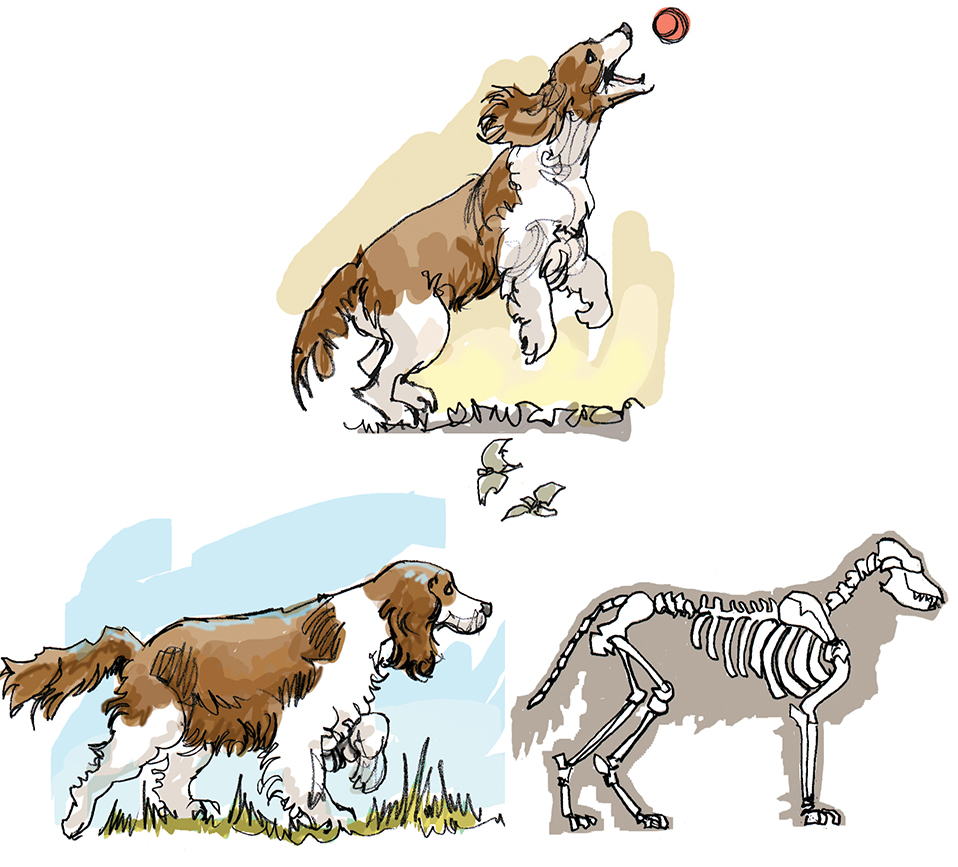
FIGURE 7.17 Different views of the same concept
In computing, an algorithm is an abstraction of the steps needed to implement it. The casual user of a program that includes the algorithm, who sees only the description of how to run the program, is like the dog owner: He or she sees only the surface. The programmer, who incorporates another’s algorithm in her program, is like the hunter who uses the well-trained dog: He or she uses the algorithm for a purpose. The implementer of the algorithm, who must understand it thoroughly, is like the vet: He or she must see the inner workings to implement the algorithm.
In computing, various kinds of abstraction are apparent. Data abstraction refers to the view of data; it is the separation of the logical view of data from its implementation. For example, your bank’s computer may represent numbers in two’s complement or one’s complement, but this distinction is of no concern to you as long as your bank statements are accurate.
Procedural abstraction refers to the view of actions; it is the separation of the logical view of an action from its implementation. For example, when we gave a name to a subprogram, we were practicing procedural abstraction.
A third kind of abstraction in computing is called control abstraction. Control abstraction refers to the view of a control structure; it is the separation of the logical view of a control structure from its implementation. A control structure lets us alter this sequential flow of control of an algorithm. WHILE and IF are control structures. How these control structures are implemented in the languages into which we might translate an algorithm is immaterial to the design of the algorithms.
Abstraction is the most powerful tool people have for managing complexity. This statement is true in computing as well as real life.
Naming Things
When we write algorithms, we use shorthand phrases to stand for the tasks and data with which we are dealing. We give names to data and processes. These names are called identifiers. For example, we used newBase and decimalNumber in the base-changing algorithm. We also gave names to tasks. For example, we used Split to name the task of splitting an array in the Quicksort algorithm. Our identifiers for data values were created from a combination of the words, using uppercase to make the meaning clearer. We left the names of tasks as phrases. Eventually the task names must be converted to a single identifier.
When we get to the stage where we translate an algorithm into a program in a language that a computer can execute, we may have to modify the identifiers. Each language has its own rules about forming identifiers. So there is a two-stage process: Data and actions are given names in the algorithm, and then these names are translated into identifiers that meet the rules of the computer language. Notice that giving identifiers to data and actions is a form of abstraction.
Testing
We have demonstrated testing at the algorithm phase using algorithm walk-throughs. We have shown how to design test plans and implemented one in assembly language. Testing is important at every stage in programming. There are basically two types of testing: clear-box testing, which is based on the code itself, and black-box testing, which is based on testing all possible input values. Often, a test plan incorporates both types of testing.
SUMMARY
Polya, in his classic book How to Solve It, outlined a problem-solving strategy for mathematical problems. This strategy can be applied to all problems, including those for which a computer program is to be written. These strategies include asking questions, looking for familiar things, and dividing and conquering; when these strategies are applied, they should lead to a plan for solving a problem. In computing, such a plan is called an algorithm.
Two categories of loops are distinguished: count controlled and event controlled. A count-controlled loop executes the loop a predetermined number of times. An event-controlled loop executes until an event within the loop changes.
Data comes in two forms: atomic (simple) and composite. An array is a homogeneous structure that gives a name to a collection of items and allows the user to access individual items by position within the structure.
Searching is the act of looking for a particular value in an array. In this chapter we examined the linear search in an unsorted array, the linear search in a sorted array, and the binary search in a sorted array. Sorting is the act of putting the items in an array into some kind of order. The selection sort, bubble sort, insertion sort, and Quicksort are four commonly used sorting algorithms.
Recursive algorithms are algorithms for which the name of a subprogram appears in the subprogram itself. The factorial and binary search are naturally recursive algorithms.
KEY TERMS
EXERCISES
For Exercises 1–6, match the problem-solving strategy with the definition or example.
Ask questions
Look for familiar things
Divide and conquer
For Exercises 7–10, match the phase with its output.
Analysis and specification phase
Algorithm development phase
Implementation phase
Maintenance phase
For Exercises 11–15, match the term with the definition.
Information hiding
Abstraction
Data abstraction
Procedural abstraction
Control abstraction
For Exercises 16–36, mark the answers true or false as follows:
True
False
Exercises 37–62 are short-answer questions.
Making a peanut butter and jelly sandwich
Getting up in the morning
Doing your homework
Driving home in the afternoon
Is the recipe an algorithm? Justify your answer.
Organize the recipe as an algorithm, using pseudocode.
List the words that have meaning in computing.
List the words that have meaning in cooking.
Make the brownies and take them to your professor.
Buying a toy for your four-year-old cousin
Organizing an awards banquet for your soccer team
Buying a dress or suit for an awards banquet at which you are being honored
Calculating the average of ten test scores
Calculating the average of an unknown number of test scores
Describing the differences in the two designs
Finding a telephone number in the phone book
Finding a telephone number on the Internet
Finding a telephone number on a scrap of paper that you have lost
Describe the differences among these designs.
Why is information hiding important?
Name three examples of information hiding that you encounter every day.
Give an abstraction of an airplane from the view of a pilot.
Give an abstraction of an airplane from the view of a passenger.
Give an abstraction of an airplane from the view of the cabin crew.
Give an abstraction of an airplane from the view of a maintenance mechanic.
Give an abstraction of an airplane from the view of the airline’s corporate office.
Exercises 63–65 use the following array of values.
![An array named ‘list’ of length 11 from the index [0] to [10] reads from left to right: 23, 41, 66, 20, 2, 90, 9, 34, 19, 40, and 99.](http://images-20200215.ebookreading.net/5/1/1/9781284155648/9781284155648__computer-science-illuminated__9781284155648__images__9781284156010_CH07_UN05.png)
Exercises 66 and 67 use the following array of values.
![An array named ‘list’ of length 11 from the index [0] to [10] reads from left to right: 5, 7, 20, 33, 44, 46, 48, 99, 101, 102, and 105.](http://images-20200215.ebookreading.net/5/1/1/9781284155648/9781284155648__computer-science-illuminated__9781284155648__images__9781284156010_CH07_UN06.png)
4
44
45
105
106
4
44
46
105
106
THOUGHT QUESTIONS
Top-down design creates scaffolding that is used to write a program. Is all of this scaffolding just a waste of effort? Is it ever used again? Of what value is it after the program is up and running?
Which of the problem-solving strategies do you use the most? Can you think of some others that you use? Would they be appropriate for computing problem solving?
There are several common examples of open-source software that many people use in their everyday lives. Can you name any?
Do you believe that the quality of an open-source software product is likely to be higher or lower than the quality of software produced by a large corporation? How do you think technical support for open-source software compares to that for proprietary software?
Daniel Bricklin (whose biography appears in Chapter 12) did not patent or copyright his software, believing that software should not be proprietary. As a result, he lost a great deal of money in the form of possible royalties. Do you consider his actions to be visionary or naive?
The Free Software Foundation is a tax-exempt charity that raises funds for work on the GNU Project. GNU software is free. Read about its philosophy on the Web. Compare GNU products with those of manufacturers such as Microsoft and Sun.
If you were to continue with computing and become a programmer, which side of the argument would you take: Should software be copyrighted or should it be free?