
13.5 Natural-Language Processing
In a science fiction movie, it’s not uncommon to have a human interact with a computer by simply talking to it. The captain of a spaceship might say, “Computer, what is the nearest starbase with medical facilities sufficient to handle Laharman’s syndrome?” The computer might then respond, “Starbase 42 is 14.7 light-years away and has the necessary facilities.”
How far is this science fiction from science fact? Ignoring space travel and advanced medicine for now, why don’t we interact with computers just by talking to them? To a limited extent, we can. We don’t tend to have free-flowing verbal conversations yet, but we’ve certainly made headway. Some computers can be set up to respond to specific verbal commands.
Devices such as the Amazon Echo and Google Home are examples of modern devices that rely on a verbal interface. These machines are sometimes called smart speakers (see FIGURE 13.7). You can simply ask questions, such as “What’s the weather?” or “How do you spell Mississippi?” and the device will respond. To get the device to realize that you are talking to it, you preface the question with a key phrase, such as “Hey, Google” or “Alexa” (the Echo’s alter ego). You can also use these devices as speakers for streaming music, to report the news, and for playing games.

FIGURE 13.7 The Google Home and Amazon Echo smart speakers
© pianodiaphragm/Shutterstock; © James W Copeland/Shutterstock
To probe this issue further, we must first realize that three basic types of processing occur during human/computer voice interaction:
Voice recognition—recognizing human words
Natural-language comprehension—interpreting human communication
Voice synthesis—re-creating human speech
The computer must first recognize the distinct words that are being spoken to it, then understand the meaning of those words, and finally (after determining the answer) produce the words that make up the response.
Common to all of these problems is the fact that we are using a natural language, which can be any language that humans use to communicate, such as English, Farsi, or Russian. Natural languages have inherent grammatical irregularities and ambiguities that make some of this processing quite challenging.
Computing technology has made great strides in all of these areas, albeit in some areas more than others. Let’s explore each one in more detail.
Voice Synthesis
Voice synthesis is generally a well-understood problem. There are two basic approaches to the solution: dynamic voice generation and recorded speech.
To generate voice output using dynamic voice generation, a computer examines the letters that make up a word and produces the sequence of sounds that correspond to those letters in an attempt to vocalize the word. Human speech has been categorized into specific sound units called phonemes. The phonemes for American English are shown in FIGURE 13.8.
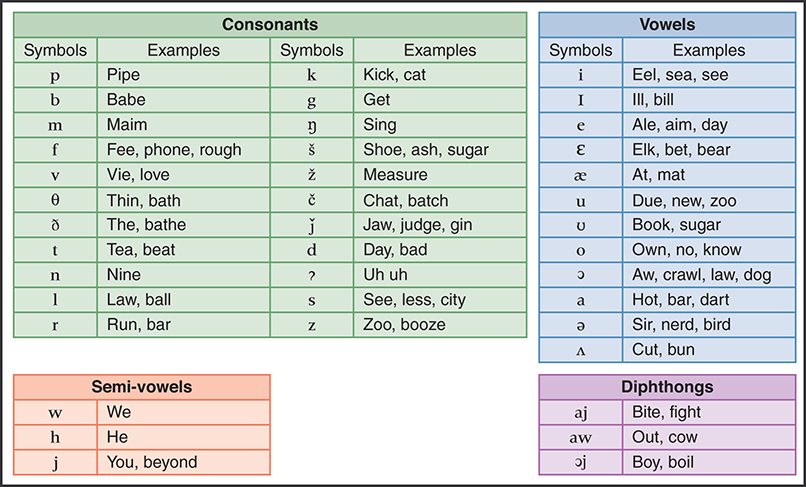
FIGURE 13.8 Phonemes for American English
After selecting the appropriate phonemes, the computer may modify the pitch of the phoneme based on the context in which it is used. The duration of each phoneme must also be determined. Finally, the phonemes are combined to form individual words. The sounds themselves are produced electronically, designed to mimic the way a human vocal track produces the sounds.
The challenges to this approach include the fact that the way we pronounce words varies greatly among humans, and the rules governing how letters contribute to the sound of a word are not consistent. Dynamic voice-generation systems often sound mechanical and stilted, though the words are usually recognizable.
The other approach to voice synthesis is to play digital recordings of a human voice saying specific words. Sentences are constructed by playing the appropriate words in the appropriate order. Sometimes common phrases or groups of words that are always used together are recorded as one entity. Telephone voice mail systems often use this approach: “Press 1 to leave a message for Alex Wakefield.”
Note that each word or phrase needed must be recorded separately. Furthermore, because words are pronounced differently in different contexts, some words may have to be recorded multiple times. For example, a word at the end of a question rises in pitch compared to its use in the middle of a sentence. As the need for flexibility increases, recorded solutions become problematic.
The dynamic voice-generation technique does not generally produce realistic human speech, but rather attempts to vocalize any words presented to it. Recorded playback is more realistic; it uses a real human voice but is limited in its vocabulary to the words that have been prerecorded, and it must have the memory capacity to store all the needed words. Generally, recorded playback is used when the number of words used is small.
Voice Recognition
When having a conversation, you might need to have something repeated because you didn’t understand what the person said. It’s not that you didn’t understand the meaning of the words (you hadn’t gotten that far); you simply didn’t understand which words were being spoken. This might happen for several reasons.
First, the sounds that each person makes when speaking are unique. Every person has a unique shape to his or her mouth, tongue, throat, and nasal cavities that affect the pitch and resonance of the spoken voice. Thus we can say we “recognize” someone’s voice, identifying him or her from the way the words sound when spoken by that person. But that also means that each person says any given word somewhat differently, complicating the task of recognizing the word in the first place. Speech impediments, mumbling, volume, regional accents, and the health of the speaker further complicate this problem.
Furthermore, humans speak in a continuous, flowing manner. Words are strung together into sentences. Sometimes we speak so quickly that two words may sound like one. Humans have great abilities to divide the series of sounds into words, but even we can become confused if a person speaks too rapidly.
Related to this issue are the sounds of words themselves. Sometimes it’s difficult to distinguish between phrases like “ice cream” and “I scream.” And homonyms such as “I” and “eye” or “see” and “sea” sound exactly the same but are unique words. Humans can often clarify these situations by considering the context of the sentence, but that processing requires another level of comprehension.
So, if we humans occasionally have trouble understanding the words we say to each other, imagine how difficult this problem is for a computer. Modern voice-recognition systems still do not do well with continuous, conversational speech. The best success has been with systems that assume disjointed speech, in which words are clearly separated.
Further success is obtained when voice-recognition systems are “trained” to recognize a particular human’s voice and a set of vocabulary words. A spoken voice can be recorded as a voiceprint, which plots the frequency changes of the sound produced by the voice when speaking a specific word. A human trains a voice-recognition system by speaking a word several times so that the computer can record an average voiceprint for that word by that person. Later, when a word is spoken, the recorded voice-prints can be compared to determine which word was spoken.
Voice-recognition systems that are not trained for specific voices and words do their best to recognize words by comparing generic voiceprints. While less accurate, using generic voiceprints avoids the time-consuming training process and allows anyone to use the system.
Natural-Language Comprehension
Even if a computer recognizes the words that are spoken, it is another task entirely to understand the meaning of those words. This is the most challenging aspect of natural-language processing. Natural language is inherently ambiguous, meaning that the same syntactic structure could have multiple valid interpretations. These ambiguities can arise for several reasons.
One problem is that a single word can have multiple definitions and can even represent multiple parts of speech. The word light, for instance, can be both a noun and a verb. This is referred to as a lexical ambiguity. A computer attempting to apply meaning to a sentence would have to determine how the word was being used. Consider the following sentence:
Time flies like an arrow.
This sentence might mean that time seems to move quickly, just like an arrow moves quickly. That’s probably how you interpreted it when you read it. But note that the word time can also be a verb, such as when you time the runner of a race. The word flies can also be a noun. Therefore, you could interpret this sentence as a directive to time flies in the same manner in which an arrow times flies. Because an arrow doesn’t time things, you probably wouldn’t apply that interpretation. But it is no less valid than the other one! Given the definition of the words, a computer would not necessarily know which interpretation was appropriate. We could even interpret this sentence a third way, indicating the preferences of that rare species we’ll call a “time fly.” After all, fruit flies like a banana. That interpretation probably sounds ridiculous to you, but such ambiguities cause huge problems when it comes to a computer understanding natural language.
A natural-language sentence can also have a syntactic ambiguity because phrases can be put together in various ways. For example:
I saw the Grand Canyon flying to New York.
Because canyons don’t fly, there is one obvious interpretation. But because the sentence can be constructed that way, there are two valid interpretations. To reach the desired conclusion, a computer would have to “know” that canyons don’t fly and take that fact into account.
Referential ambiguity can occur with the use of pronouns. Consider the following:
The brick fell on the computer but it is not broken.
What is not broken, the brick or the computer? We might assume the pronoun “it” refers to the computer in this case, but that is not necessarily the correct interpretation. In fact, if a vase had fallen on the computer, even we humans wouldn’t know what “it” referred to without more information.
Natural-language comprehension is a huge area of study and goes well beyond the scope of this book, but it’s important to understand the reasons why this issue is so challenging.