 Building a Naive Bayes classifier
by Alberto Boschetti, Luca Massaron, Bastiaan Sjardin, John Hearty, Prateek Joshi
Python: Real World Machine Learning
Building a Naive Bayes classifier
by Alberto Boschetti, Luca Massaron, Bastiaan Sjardin, John Hearty, Prateek Joshi
Python: Real World Machine Learning
- Python: Real World Machine Learning
- Table of Contents
- Python: Real World Machine Learning
- Python: Real World Machine Learning
- Credits
- Preface
- I. Module 1
- 1. The Realm of Supervised Learning
- Introduction
- Preprocessing data using different techniques
- Label encoding
- Building a linear regressor
- Computing regression accuracy
- Achieving model persistence
- Building a ridge regressor
- Building a polynomial regressor
- Estimating housing prices
- Computing the relative importance of features
- Estimating bicycle demand distribution
- 2. Constructing a Classifier
- Introduction
- Building a simple classifier
- Building a logistic regression classifier
- Building a Naive Bayes classifier
- Splitting the dataset for training and testing
- Evaluating the accuracy using cross-validation
- Visualizing the confusion matrix
- Extracting the performance report
- Evaluating cars based on their characteristics
- Extracting validation curves
- Extracting learning curves
- Estimating the income bracket
- 3. Predictive Modeling
- 4. Clustering with Unsupervised Learning
- Introduction
- Clustering data using the k-means algorithm
- Compressing an image using vector quantization
- Building a Mean Shift clustering model
- Grouping data using agglomerative clustering
- Evaluating the performance of clustering algorithms
- Automatically estimating the number of clusters using DBSCAN algorithm
- Finding patterns in stock market data
- Building a customer segmentation model
- 5. Building Recommendation Engines
- Introduction
- Building function compositions for data processing
- Building machine learning pipelines
- Finding the nearest neighbors
- Constructing a k-nearest neighbors classifier
- Constructing a k-nearest neighbors regressor
- Computing the Euclidean distance score
- Computing the Pearson correlation score
- Finding similar users in the dataset
- Generating movie recommendations
- 6. Analyzing Text Data
- Introduction
- Preprocessing data using tokenization
- Stemming text data
- Converting text to its base form using lemmatization
- Dividing text using chunking
- Building a bag-of-words model
- Building a text classifier
- Identifying the gender
- Analyzing the sentiment of a sentence
- Identifying patterns in text using topic modeling
- 7. Speech Recognition
- 8. Dissecting Time Series and Sequential Data
- Introduction
- Transforming data into the time series format
- Slicing time series data
- Operating on time series data
- Extracting statistics from time series data
- Building Hidden Markov Models for sequential data
- Building Conditional Random Fields for sequential text data
- Analyzing stock market data using Hidden Markov Models
- 9. Image Content Analysis
- Introduction
- Operating on images using OpenCV-Python
- Detecting edges
- Histogram equalization
- Detecting corners
- Detecting SIFT feature points
- Building a Star feature detector
- Creating features using visual codebook and vector quantization
- Training an image classifier using Extremely Random Forests
- Building an object recognizer
- 10. Biometric Face Recognition
- Introduction
- Capturing and processing video from a webcam
- Building a face detector using Haar cascades
- Building eye and nose detectors
- Performing Principal Components Analysis
- Performing Kernel Principal Components Analysis
- Performing blind source separation
- Building a face recognizer using Local Binary Patterns Histogram
- 11. Deep Neural Networks
- Introduction
- Building a perceptron
- Building a single layer neural network
- Building a deep neural network
- Creating a vector quantizer
- Building a recurrent neural network for sequential data analysis
- Visualizing the characters in an optical character recognition database
- Building an optical character recognizer using neural networks
- 12. Visualizing Data
- 1. The Realm of Supervised Learning
- II. Module 2
- 1. Unsupervised Machine Learning
- 2. Deep Belief Networks
- 3. Stacked Denoising Autoencoders
- 4. Convolutional Neural Networks
- 5. Semi-Supervised Learning
- 6. Text Feature Engineering
- 7. Feature Engineering Part II
- 8. Ensemble Methods
- 9. Additional Python Machine Learning Tools
- A. Chapter Code Requirements
- III. Module 3
- 1. First Steps to Scalability
- 2. Scalable Learning in Scikit-learn
- 3. Fast SVM Implementations
- 4. Neural Networks and Deep Learning
- The neural network architecture
- Neural networks and regularization
- Neural networks and hyperparameter optimization
- Neural networks and decision boundaries
- Deep learning at scale with H2O
- Deep learning and unsupervised pretraining
- Deep learning with theanets
- Autoencoders and unsupervised learning
- Summary
- 5. Deep Learning with TensorFlow
- 6. Classification and Regression Trees at Scale
- 7. Unsupervised Learning at Scale
- 8. Distributed Environments – Hadoop and Spark
- 9. Practical Machine Learning with Spark
- A. Introduction to GPUs and Theano
- A. Bibliography
- Index
A Naive Bayes classifier is a supervised learning classifier that uses Bayes' theorem to build the model. Let's go ahead and build a Naïve Bayes classifier.
- We will use
naive_bayes.pythat is provided to you as reference. Let's import a couple of things:from sklearn.naive_bayes import GaussianNB from logistic_regression import plot_classifier
- You were provided with a
data_multivar.txtfile. This contains data that we will use here. This contains comma-separated numerical data in each line. Let's load the data from this file:input_file = 'data_multivar.txt' X = [] y = [] with open(input_file, 'r') as f: for line in f.readlines(): data = [float(x) for x in line.split(',')] X.append(data[:-1]) y.append(data[-1]) X = np.array(X) y = np.array(y)We have now loaded the input data into
Xand the labels intoy. - Let's build the Naive Bayes classifier:
classifier_gaussiannb = GaussianNB() classifier_gaussiannb.fit(X, y) y_pred = classifier_gaussiannb.predict(X)
The
GaussianNBfunction specifies Gaussian Naive Bayes model. - Let's compute the accuracy of the classifier:
accuracy = 100.0 * (y == y_pred).sum() / X.shape[0] print "Accuracy of the classifier =", round(accuracy, 2), "%"
- Let's plot the data and the boundaries:
plot_classifier(classifier_gaussiannb, X, y)
You should see the following figure:
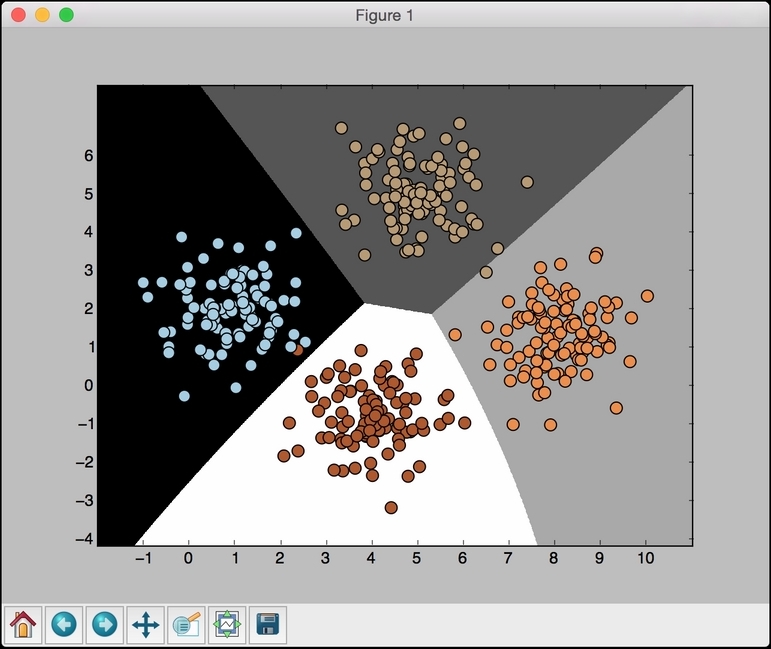
There is no restriction on the boundaries to be linear here. In the preceding example, we used up all the data for training. A good practice in machine learning is to have nonoverlapping data for training and testing. Ideally, we need some unused data for testing so that we can get an accurate estimate of how the model performs on unknown data. There is a provision in scikit-learn that handles this very well, as shown in the next recipe.
-
No Comment