
Now that we built all of the different parts of a recommendation engine, we are ready to generate movie recommendations. We will use all the functionality that we built in the previous recipes to build a movie recommendation engine. Let's see how to build it.
- Create a new Python file, and import the following packages:
import json import numpy as np from euclidean_score import euclidean_score from pearson_score import pearson_score from find_similar_users import find_similar_users
- We will define a function to generate movie recommendations for a given user. The first step is to check whether the user exists in the dataset:
# Generate recommendations for a given user def generate_recommendations(dataset, user): if user not in dataset: raise TypeError('User ' + user + ' not present in the dataset') - Let's compute the Pearson score of this user with all the other users in the dataset:
total_scores = {} similarity_sums = {} for u in [x for x in dataset if x != user]: similarity_score = pearson_score(dataset, user, u) if similarity_score <= 0: continue - We need to find the movies that haven't been rated by this user:
for item in [x for x in dataset[u] if x not in dataset[user] or dataset[user][x] == 0]: total_scores.update({item: dataset[u][item] * similarity_score}) similarity_sums.update({item: similarity_score}) - If the user has watched every single movie in the database, then we cannot recommend anything to this user. Let's take care of this condition:
if len(total_scores) == 0: return ['No recommendations possible'] - We now have a list of these scores. Let's create a normalized list of movie ranks:
# Create the normalized list movie_ranks = np.array([[total/similarity_sums[item], item] for item, total in total_scores.items()]) - We need to sort it in descending order based on the score:
# Sort in decreasing order based on the first column movie_ranks = movie_ranks[np.argsort(movie_ranks[:, 0])[::-1]] - We are finally ready to extract the movie recommendations:
# Extract the recommended movies recommendations = [movie for _, movie in movie_ranks] return recommendations - Let's define the
mainfunction and load the dataset:if __name__=='__main__': data_file = 'movie_ratings.json' with open(data_file, 'r') as f: data = json.loads(f.read()) - Let's generate recommendations for
Michael Henry:user = 'Michael Henry' print " Recommendations for " + user + ":" movies = generate_recommendations(data, user) for i, movie in enumerate(movies): print str(i+1) + '. ' + movie - The user
John Carsonhas watched all the movies. Therefore, if we try to generate recommendations for him, it should display 0 recommendations. Let's see whether this happens:user = 'John Carson' print " Recommendations for " + user + ":" movies = generate_recommendations(data, user) for i, movie in enumerate(movies): print str(i+1) + '. ' + movie - If you run this code, you will see the following on your Terminal:
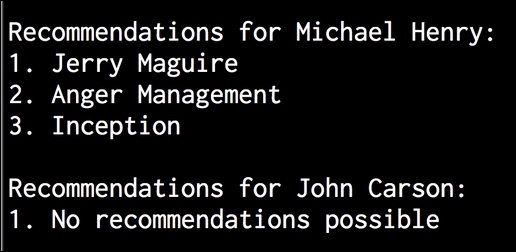
..................Content has been hidden....................
You can't read the all page of ebook, please click here login for view all page.