
In previous sections, we covered neural networks and deep architectures running on a local computer and we found that neural networks are already highly vectorized but still computationally expensive. There is not much that we can do if we want to make the algorithm more scalable on a desktop computer other than utilizing Theano and GPU computing. So if we want to scale deep learning algorithms more drastically, we will need to find a tool that can run algorithms out-of-core instead of on a local CPU/GPU. H2O is, at this moment, the only open source out-of-core platform that can run deep learning algorithms quickly. It is also cross-platform; besides Python, there are APIs for R, Scala, and Java.
H2O is compiled on a Java-based platform developed for a wide range of data science-related tasks such as datahandling and machine learning. H2O runs on distributed and parallel CPUs in-memory so that data will be stored in the H2O cluster. The H2O platform—as of yet—has applications for General Linear Models (GLM), Random Forests, Gradient Boosting Machines (GBM), K Means, Naive Bayes, Principal Components Analysis, Principal Components Regression, and, of course our main focus for this chapter, Deep Learning.
Great, now we are ready to perform our first H2O out-of-core analysis.
Let's start the H2O instance and load a file in H2O's distributed memory system:
import sys sys.prefix = "/usr/local" import h2o h2o.init(start_h2o=True) Type this to get interesting information about the specifications of your cluster. Look at the memory that is allowed and the number of cores. h2o.cluster_info()
This will look more or less like the following (slight differences might occur between trials and systems):
OUTPUT:] Java Version: java version "1.8.0_60" Java(TM) SE Runtime Environment (build 1.8.0_60-b27) Java HotSpot(TM) 64-Bit Server VM (build 25.60-b23, mixed mode) Starting H2O JVM and connecting: .................. Connection successful! ------------------------------ --------------------------------------- H2O cluster uptime: 2 seconds 346 milliseconds H2O cluster version: 3.8.2.3 H2O cluster name: H2O_started_from_python**********nzb520 H2O cluster total nodes: 1 H2O cluster total free memory: 3.56 GB H2O cluster total cores: 8 H2O cluster allowed cores: 8 H2O cluster healthy: True H2O Connection ip: 1**.***.***.*** H2O Connection port: 54321 H2O Connection proxy: Python Version: 2.7.10 ------------------------------ --------------------------------------- ------------------------------ --------------------------------------- H2O cluster uptime: 2 seconds 484 milliseconds H2O cluster version: 3.8.2.3 H2O cluster name: H2O_started_from_python_quandbee_nzb520 H2O cluster total nodes: 1 H2O cluster total free memory: 3.56 GB H2O cluster total cores: 8 H2O cluster allowed cores: 8 H2O cluster healthy: True H2O Connection ip: 1**.***.***.*** H2O Connection port: 54321 H2O Connection proxy: Python Version: 2.7.10 ------------------------------ --------------------------------------- Sucessfully closed the H2O Session. Successfully stopped H2O JVM started by the h2o python module.
In H2O deep learning, the dataset that we will use to train is the famous MNIST dataset. It consists of pixel intensities of 28 x 28 images of handwritten digits. The training set has 70,000 training items with 784 features together with a label for each record containing the target label digits.
Now that we are more comfortable with managing data in H2O, let's perform a deep learning example.
In H2O, we don't have to transform or normalize the input data; it is standardized internally and automatically. Each feature is transformed into the N(0,1) space.
Let's import the famous handwritten digits image dataset MNIST from the Amazon server to the H2O cluster:
import h2o
h2o.init(start_h2o=True)
train_url ="https://h2o-public-test-data.s3.amazonaws.com/bigdata/laptop/mnist/train.csv.gz"
test_url="https://h2o-public-test-data.s3.amazonaws.com/bigdata/laptop/mnist/test.csv.gz"
train=h2o.import_file(train_url)
test=h2o.import_file(test_url)
train.describe()
test.describe()
y='C785'
x=train.names[0:784]
train[y]=train[y].asfactor()
test[y]=test[y].asfactor()
from h2o.estimators.deeplearning import H2ODeepLearningEstimator
model_cv=H2ODeepLearningEstimator(distribution='multinomial'
,activation='RectifierWithDropout',hidden=[32,32,32],
input_dropout_ratio=.2,
sparse=True,
l1=.0005,
epochs=5)The output of this print model will provide a lot of detailed information. The first table that you will see is the following one. This provides all the specifics about the architecture of the neural network. You can see that we have used a neural network with an input dimension of 717 with three hidden layers (consisting of 32 units each) with softmax activation applied to the output layer and ReLU between the hidden layers:
model_cv.train(x=x,y=y,training_frame=train,nfolds=3) print model_cv OUTPUT]

If you want a short overview of model performance, this is a very practical method.
In the following table, the most interesting metrics are the training classification error and validation classification error over each fold. You can easily compare these in case you want to validate your model:
print model_cv.scoring_history()
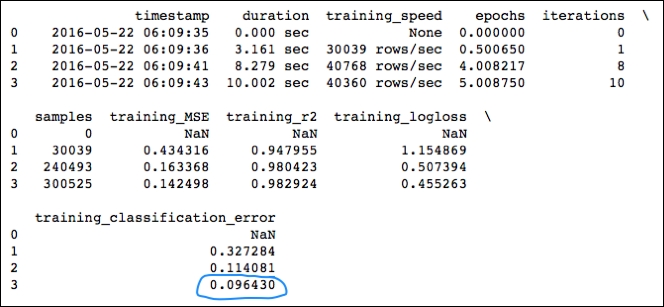
Our training classification error of .096430 and accuracy in the .907 range on the MNIST dataset is pretty good; it's almost as good as Yann LeCun's convolutional neural network submission.
H2O provides a convenient method to acquire validation metrics as well. We can do this by passing the validation dataframe to the cross-validation function:
model_cv.train(x=x,y=y,training_frame=train,validation_frame=test,nfolds=3) print model_cv
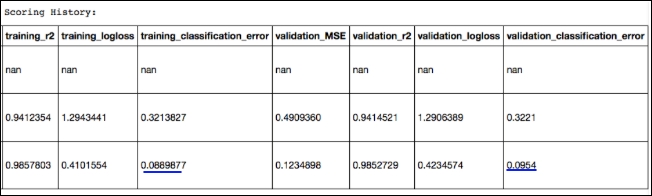
In this case, we can easily compare training_classification_error (.089) with our validation_classification_error (.0954).
Maybe we can improve our score; let's use a hyperparameter optimization model.
Considering that our previous model performed quite well, we will focus our tuning efforts on the architecture of our network. H2O's gridsearch function is quite similar to Scikit-learn's randomized search; namely, instead of searching the full parameter space, it iterates over a random list of parameters. First, we will set up a parameter list that we will pass to the gridsearch function. H2O will provide us with an output of each model and the corresponding score in the parameters' search:
hidden_opt = [[18,18],[32,32],[32,32,32],[100,100,100]]
# l1_opt = [s/1e6 for s in range(1,1001)]
# hyper_parameters = {"hidden":hidden_opt, "l1":l1_opt}
hyper_parameters = {"hidden":hidden_opt}
#important: here we specify the search parameters
#be careful with these, training time can explode (see max_models)
search_c = {"strategy":"RandomDiscrete",
"max_models":10, "max_runtime_secs":100,
"seed":222}
from h2o.grid.grid_search import H2OGridSearch
model_grid = H2OGridSearch(H2ODeepLearningEstimator, hyper_params=hyper_parameters)
#We have added a validation set to the gridsearch method in order to have a better #estimate of the model performance.
model_grid.train(x=x, y=y, distribution="multinomial", epochs=1000, training_frame=train, validation_frame=test,
score_interval=2, stopping_rounds=3, stopping_tolerance=0.05,search_criteria=search_c)
print model_grid
# Grid Search Results for H2ODeepLearningEstimator:
OUTPUT]
deeplearning Grid Build Progress: [##################################################] 100%
hidden
0 [100, 100, 100]
1 [32, 32, 32]
2 [32, 32]
3 [18, 18]
model_ids logloss
0 Grid_DeepLearning_py_1_model_python_1464790287811_3_model_3 0.148162 ←------
1 Grid_DeepLearning_py_1_model_python_1464790287811_3_model_2 0.173675
2 Grid_DeepLearning_py_1_model_python_1464790287811_3_model_1 0.212246
3 Grid_DeepLearning_py_1_model_python_1464790287811_3_model_0 0.227706 We can see that our best architecture would be one with three layers with 100 units each. We can also clearly see that gridsearch increases training time substantially even on a powerful computing cluster like the one that H2O operates on. So, even on H2O, we should use gridsearch with caution and be conservative with the parameters that are parsed in the model.
Now let's shutdown the H2O instance before we proceed:
h2o.shutdown(prompt=False)