
Sentiment analysis is one of the most popular applications of NLP. Sentiment analysis refers to the process of determining whether a given piece of text is positive or negative. In some variations, we consider "neutral" as a third option. This technique is commonly used to discover how people feel about a particular topic. This is used to analyze sentiments of users in various forms, such as marketing campaigns, social media, e-commerce customers, and so on.
- Create a new Python file, and import the following packages:
import nltk.classify.util from nltk.classify import NaiveBayesClassifier from nltk.corpus import movie_reviews
- Define a function to extract features:
def extract_features(word_list): return dict([(word, True) for word in word_list]) - We need training data for this, so we will use movie reviews in NLTK:
if __name__=='__main__': # Load positive and negative reviews positive_fileids = movie_reviews.fileids('pos') negative_fileids = movie_reviews.fileids('neg') - Let's separate these into positive and negative reviews:
features_positive = [(extract_features(movie_reviews.words(fileids=[f])), 'Positive') for f in positive_fileids] features_negative = [(extract_features(movie_reviews.words(fileids=[f])), 'Negative') for f in negative_fileids] - Divide the data into training and testing datasets:
# Split the data into train and test (80/20) threshold_factor = 0.8 threshold_positive = int(threshold_factor * len(features_positive)) threshold_negative = int(threshold_factor * len(features_negative)) - Extract the features:
features_train = features_positive[:threshold_positive] + features_negative[:threshold_negative] features_test = features_positive[threshold_positive:] + features_negative[threshold_negative:] print " Number of training datapoints:", len(features_train) print "Number of test datapoints:", len(features_test) - We will use a Naive Bayes classifier. Define the object and train it:
# Train a Naive Bayes classifier classifier = NaiveBayesClassifier.train(features_train) print " Accuracy of the classifier:", nltk.classify.util.accuracy(classifier, features_test) - The classifier object contains the most informative words that it obtained during analysis. These words basically have a strong say in what's classified as a positive or a negative review. Let's print them out:
print " Top 10 most informative words:" for item in classifier.most_informative_features()[:10]: print item[0] - Create a couple of random input sentences:
# Sample input reviews input_reviews = [ "It is an amazing movie", "This is a dull movie. I would never recommend it to anyone.", "The cinematography is pretty great in this movie", "The direction was terrible and the story was all over the place" ] - Run the classifier on those input sentences and obtain the predictions:
print " Predictions:" for review in input_reviews: print " Review:", review probdist = classifier.prob_classify(extract_features(review.split())) pred_sentiment = probdist.max() - Print the output:
print "Predicted sentiment:", pred_sentiment print "Probability:", round(probdist.prob(pred_sentiment), 2) - The full code is in the
sentiment_analysis.pyfile. If you run this code, you will see three main things printed on the Terminal. The first is the accuracy, as shown in the following image: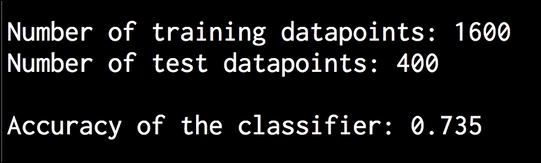
- The next is a list of most informative words:

- The last is the list of predictions, which are based on the input sentences:
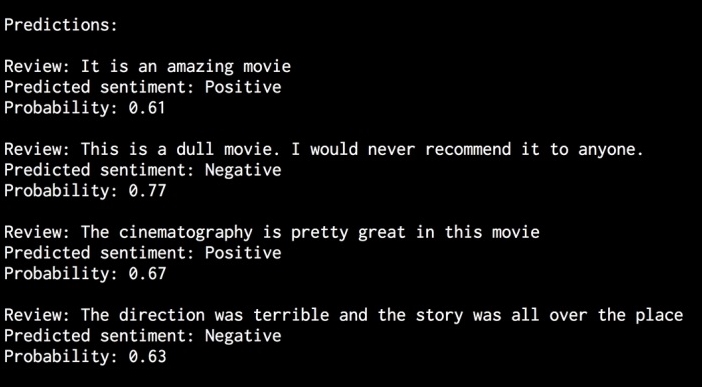
We use NLTK's Naive Bayes classifier for our task here. In the feature extractor function, we basically extract all the unique words. However, the NLTK classifier needs the data to be arranged in the form of a dictionary. Hence, we arranged it in such a way that the NLTK classifier object can ingest it.
Once we divide the data into training and testing datasets, we train the classifier to categorize the sentences into positive and negative. If you look at the top informative words, you can see that we have words such as "outstanding" to indicate positive reviews and words such as "insulting" to indicate negative reviews. This is interesting information because it tells us what words are being used to indicate strong reactions.