
We can build a model from the dataset to estimate how many stars a rating may entail. However, the data points available within a review are only:
- funny
- useful
- cool
These would not appear to be good indicators for a rating number. We can use a model, such as:
model <- lm(stars ~ funny + useful + cool, data=reviews) summary(model)
This produces the statistics of the model:
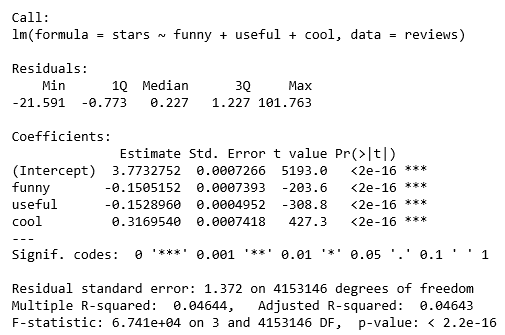
As expected, we don't have enough information to work with:
- Over four million degrees of freedom, just about one per review
- P values are very small—the probability that we have estimated correctly is non-existent
- 3.7 intercept (close to the halfway point of the range)
- Such low affect rates (under one times each factor) meaning we aren't moving far from the intercept